Improving NN Efficiency - newlife-js/Wiki GitHub Wiki
by 서울대학교 유승주 교수님
NN Efficiency
BERT
BERT size 계산하기
Computation, Dimension, Model size


Sparsely Gated Mixture of Experts
FFN 모델 크기를 키워서 accuracy 높이는 방법
input에 따라서 다른 Expert를 택해서(gating) input 별로 다른 FFN을 타도록 설계
약 2000개의 FFN으로 구성, input별로 1~2 개 정도의 FFN만 돌리므로 연산은 많아지지 않고 모델 사이즈만 커짐


※ Model size가 클수록 quality가 좋음
(모델 size가 크면 sample도 적게 필요)

-> 1.6T까지 size를 키움
self-supervised learning
데이터를 레이블링하는 데 많은 비용이 들기 때문에 self-supervised learning하는 방법을 찾게 됨
self-supervised learning으로 pre-training을 진행한 후에, labeling된 적은 수의 data로 fine-tuning할 수 있음
-
Contrastive Predictive Coding
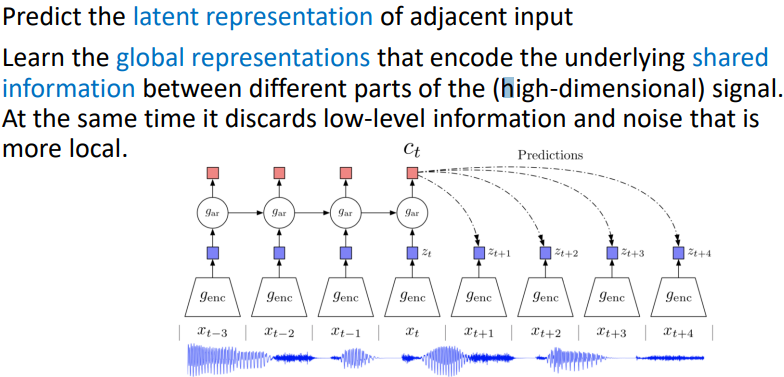
CNN에도 적용해서(image의 일부분으로부터 feature를 뽑아서 나머지 부분을 예측하도록 학습 -> feature extractor를 학습할 수 있음)

-
Contrastive learning of visual representations
Transformation을 가해도 similarity를 크게 갖도록 학습
batch 내의 다른 데이터들은 negative sampling으로 사용하여 학습

 ■ BYOL(Bootstrap Your Own Latent)
■ BYOL(Bootstrap Your Own Latent)
 ■ Barlow Twins
■ Barlow Twins
latent vector의 각 element의 batch-wise vector의 correlation이 크게 되도록 latent vector representation을 학습
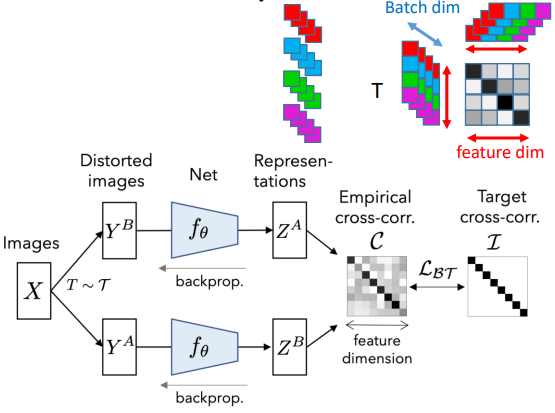
-
Self-Supervised Vision Transformer(SiT)

Memory Capacity Problems
학습할 때는 중간 activation layer 모두 저장해야 하기 때문에 큰 memory가 필요
※ Adam의 경우 momentum과 variance of the gradients 모두 가지고 있어야 함.
정교한 정보(precision)를 가지고 update해야 함(32bit).
1.5 Billion parameters -> 24GB 필요
Activation Checkpointing
모든 activation layer를 저장하지 않고, N개마다 한 번 저장하고
backward pass에서 activation을 다시 계산하여 weight update
계산량은 많아지지만 batch size는 키울 수 있음

Transferring Activation between GPU and CPU Memory(vDNN, ZeRO-Offload)
activation을 CPU Memory저장해 놓았다가 backward pass 중에 fetch해서 사용
3D Parallelism
1T 이상의 model을 학습하기 위해서는 많은 gpu의 병렬 계산이 필요

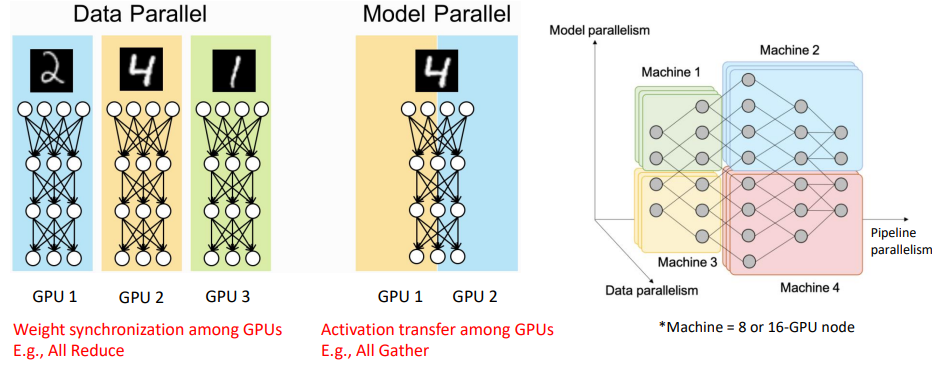
Data Parallelism
각각의 GPU가 동일한 weight를 가진 model을 각각 가지고 있음
다른 학습데이터를 사용하여 weight update함
각 weight를 average하여 갖도록 함
- All reduce: 다른 mini-batch로부터 나온 weight를 더해서 global weight를 업데이트(Data Parallel)

Model Parallelism
모델의 사이즈가 커서 weight들을 모두 갖고있을 수 없을 때 1 layer에 여러 GPU가 할당되어 연산
다음 layer를 계산하기 위해서는 이전 activation 모두가 필요하므로 GPU간 activation transfer가 필요
weight transfer보다 activation transfer가 훨씬 overhead가 큼(느림)
-> GPU node간 통신은 하지 않고, node 내부의 GPU간 통신(intra GPU node communication, NVLINK 등)만 하도록 model parallelism 구성
- All gather: 다른 종류의 weight들을 concat하여 사용(Model Parallel)

Pipe Parallelism

Model State
Adam Optimizer를 사용하면 weight를 update하기 위해 model state(momentum과 variance)를 저장하기 위한 추가 메모리가 필요함
성능을 위해서 momentum과 variance는 high-precision(fp32)을 가져야 함

ZeRO-DP(Zero Redundancy Optimizer-Data Parallelism)
Layer별로 GPU가 weight를 나눠서 가지고 있다가 layer 시작하기 직전에만 all gather로 모아서 연산하고 바로 버림




ZeRO-Offload
Optimizer states are kept in CPU memory for the entire training
backward에서 계산된 gradient를 CPU가 받아서 weight update 후 다시 GPU로 넘김

Zero Infinity
Flash메모리 등 가용한 모든 메모리 사용

Recommender system
Prod2Vec
Word2Vec과 같은 방식으로 상품을 embedding

Youtube

Memory Problems
 Sparse feature: user가 본 영상 정보, 검색 정보 등 -> embedding table이 큼
Sparse feature: user가 본 영상 정보, 검색 정보 등 -> embedding table이 큼
Dense feature: user profile 등
NPU and Server Architecture
NN Accelerator
CPU는 보통 느리고 power를 많이 사용
-> 특정 task(matrix multiplication 등)에 최적화된 highly tuned processor를 설계한 것
최대한 메모리 접근은 줄이고(데이터 재사용), 불필요한 연산은 줄이고(zero-skipping), 메모리 사용량 줄이고(low precision, quantization, weight-pruning)
※ Convolution도 Matrix Multiplication이다.

- BLAS: matrix multiplication을 위한 library
- cuBLAS(BLAS in CUDA)
convolution을 matrix multiplication으로 하면 아래와 같이 중복되는 element가 많이 생김(memory-inefficient)
 cuBLAS는 중복된 형태 그대로를 DRAM에 가지고 있지만, cuDNN은 원본 그대로로 가지고 있다가 Cache로 넘기기 때문에 더 memory-efficient
cuBLAS는 중복된 형태 그대로를 DRAM에 가지고 있지만, cuDNN은 원본 그대로로 가지고 있다가 Cache로 넘기기 때문에 더 memory-efficient

Systolic Array Matrix Multiplication

가로로는 input이 들어가고, 세로로는 partial sum이 들어옴(matrix 하나는 cell에 저장되어 있고)


※ 2D Convolution을 1D convolution의 concat으로 생각하고 Hardware로 2D convolution을 구현

Memory Bandwidth
matrix의 weights들은 한번만 쓰고 버리기 때문에 메모리 접근 횟수가 많음
-> batch 처리를 통해 matrix를 재사용하도록 함
DRAM으로는 bandwidth 감당이 되지 않아 HBM(High-Bandwidth Memory)를 쓰게 됨
TPU


※ TPUv4i에서는 기존의 128x128 scalar product의 systolic array를 32x32-4x4 dot product로 바꿔서 chip 면적과 power 소모량을 줄임

NVIDIA Tensor core
NVIDIA Tensor core는 정해진 규격의 빠른 matrix multiplication 연산을 제공
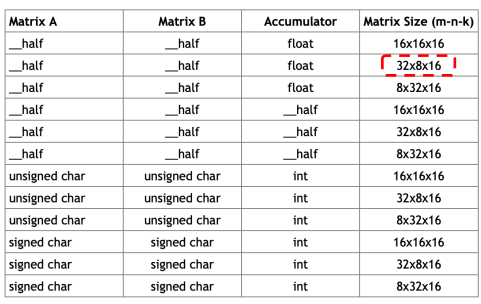
Precision을 낮추면 해당 연산을 더 빠르게(throughput이 크게) 수행
16bit -> 8bit -> 4bit


※ Zero Skipping: weight가 0인 element는 연산을 하지 않도록 해서 속도를 높임

※ Weight Pruning: 불필요한 weight를 0으로 만들어서 sparsity를 높임
accuracy는 낮아져도 속도를 높일 수 있음

Neural Rendering
3D object/scene을 빠르게 rendering하기 위한 기술
Neural Radiance Field(NeRF)
Learn the implicit representation of the given scene
5D(position, direction) input으로 Rendering(color, density)을 출력하는 MLP를 학습
ray별로 sampling을 해 MLP에 넣어서 volume rendering하고 loss를 구해 back propagation
ray의 sample마다 구해진 color의 weighted sum이 최종 rendering image가 됨
weight는 transmittance(survival probability: 앞 sample point에 의해 가려지지 않을 확률)와 opacity(surface일 확률)의 곱으로 계산


high computation cost로 real-time application으로 사용하긴 힘들었음..

PlenOctree
σ(density)와 k(Spherical Harmonics의 9 coefficients)를 계산하는 NeRF 방식의 MLP를 학습
Voxel grid별로 sampling한 point에 대해 MLP에 입력시켜 voxel grid representation을 계산
L2 loss를 통해서 back propagation하여 voxel grid를 fine-tuning
(solid한 particle이 있는 voxel grid만 남기는 filtering 과정이 중간에 포함되어 있음)

Plenoxel
PlenOctree의 density와 SH coefficient를 구하는 MLP를 학습하는 과정을 생략
voxel grid representation을 randomly initialize하고 PlenOctree의 fine-tuning 과정과 같은 방식으로 parameter를 update함
