GPU Architecture - newlife-js/Wiki GitHub Wiki
by 연세대학교 노원우 교수님
비디오 게임을 지원하기 위해 발전
-> ML(non-graphics computing)과 암호화폐 채굴까지 다양한 목적으로 발전
CPU보다 많은 HW resource를 연산에 사용
-
GPUs are NOT stand-alone
CPU와 함께 쓰임(GPU에게 computation을 지시하고, GPU에게 data를 전송해줌)

discrete GPU에서는 System memory에 직접 접근할 수 없어 속도가 느림(graphics memory로 복사해서 써야함)
-> or CXL이나 NVLINK와 같은 직접 접근 기술이 필요
Virtual Memory(Unified Memory): System memory에서 자동으로 graphics memory로 전송 -
Symmetric Multiprocessors(SMP) vs Distributed Shared Memory(DSM, NUMA)

-
CPU의 Device Driver의 역할
GPU에서 접근 가능한 메모리에 information(code)을 translate,
GPU가 연산하도록 신호 보냄 -
GPU는 많은 Core(SIMT: single-instruction multiple-thread)로 이루어짐
NVIDIA에서는 streaming multiprocessors(SM), AMD에서는 computing units으로 부름
각 코어는 수천개의 thread를 돌림

※ Thread: 개별적인 register set을 가지고 연산을 함
여러 Thread가 하나의 Block으로 묶임
여러 Block은 하나의 Grid로 묶임

host(system processor) function은 __host__로 declare, GPU function은 __device__로 declare함
- function call syntax

dimGrid: Block이 어떤 dimensionality로 이루어져 있는지
dimBlock: Thread가 어떤 dimensionality로 이루어져 있는지
예시)

여기서 각 dimensionality는 (nblocks, 1, 1) (256, 1, 1) 이라고 보면 됨

1개 Thread Block = 16 Warp(32 thread) = 512 Thread
16 Block * 512 Thread/Block -> 2^13(8192) Thread
HW 구성을 보고 특성에 맞게 적정 thread 수, block 수를 고려하여 cuda coding을 함



컴퓨터 그래픽이 아닌 일반 연산에 GPU를 사용(CUDA, OpenCL 등)

GPU(device)를 CPU(host) program의 Accelerator로 활용


block dim, index 등을 통해서 global thread index를 구해서 연산에 사용


Global Memory: HBM, GDDR 등 GPU DRAM를 의미

thread별 다른 tid를 갖고 있기 때문에 병렬 연산이 가능

int a = atoi(argv[1]);
int b = atoi(argv[2]);
int c = 0;
int *c_dev = 0;
cudaMalloc(&c_dev, sizeof(int));
// GPU memory의 c_dev 주소에 int(4byte) 크기의 메모리를 할당
add<<1, 1>>(a, b, c_dev);
// CPU의 a, b를 더해서 GPU의 c_dev에 저장
cudaMemcpy(&c, c_dev, sizeof(int), cudaMemcpyDeviceToHost);
// CPU의 c 주소에 GPU c_dev 주소의 4byte 만큼을 복사해옴
cudaFree(c_dev)
// GPU c_dev 주소를 비움■ Vector Addition 코드



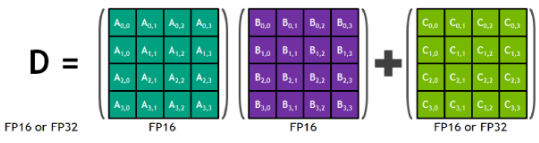
4x4 Matrix Multiply + Accumulation을 하는 accelerator
-> 16x16, 8x16 등의 연산이 가능하도록 4x4로 변환하여 연산하는 API 제공