Efficient DNN - newlife-js/Wiki GitHub Wiki
by 한양대학교 최정욱 교수님
Challenges in DL
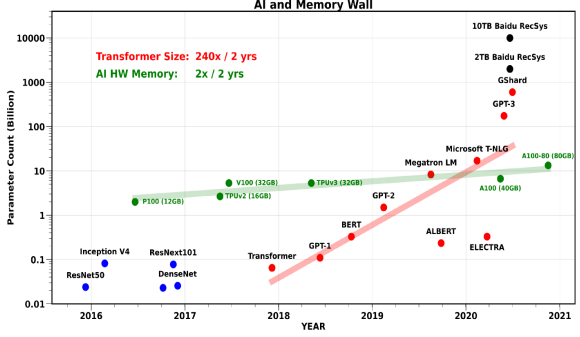
시간이 갈수록 model size, training time이 커지고 있음(Hyper-Scale AI)


반면, 메모리 capacity/bandwith는 빠르게 발전하지 못함
In-Memory Computing
Memory 내에 혹은 가까이에 가속기를 배치해서 속도를 빠르게 하기도 함

Efficient DNN Computation
Reduced Precision Computation

MAC Unit

※ Bit 수가 적을수록 HW Energy/Area cost가 작음(Add-O(bit), Mult-O(bit^2))
FP32 -> FP16으로 만들거나 quantization을 통해 int8로 만듦
Logarithmic Quantization
Weight가 많이 분포하는 부분은 촘촘하게, 적게 분포하는 부분은 sparse하게 quantization하는 방법

Non-Linear Quantization Table Lookup
weight의 분포가 대칭적이지 않을 수 있기 때문에 weight를 k-means 클러스터링해서 대표값을 뽑아 lookup table 구성
-> 저장공간 save

Pruning
안 중요한 weight를 없애 weight를 sparse하게 만드는 방법
saliency(training error에 영향을 미치는 정도 등)를 계산해서 low-saliency weights를 삭제

fine-grain 방식으로 pruning하면 HW efficiency가 좋지 않음
-> structured pruning(pruning rate는 작음)

Activation Sparsity
Activation Function(ReLU)에 조작을 가해서 0이 되는 숫자를 늘려서 더 sparse하게 함
-> Memory access, power consumption ↓
DNN Quantization
-
PTQ(Post-Training Quantization): directly converts parameters and activations to reduced-precision
이미 다 학습된 pre-trained model에 calibration/quantization만 하는 방식
 scale: -|max| ~ +|max|로 scaling하게 되면 한쪽은 낭비되는 부분이 생길 수 있음
scale: -|max| ~ +|max|로 scaling하게 되면 한쪽은 낭비되는 부분이 생길 수 있음
-> threshold를 두어서 threshold 밖의 값들은 최소/최대값으로 매핑
(threshold는 KL divergence로 scale 이전과 이후의 차이가 작은 값으로 선정)

-
QAT(Quantization-Aware Training): explotis re-training to compensate quantization error
실제 training data로 quantized된 parameter들을 최적화 해가면서 iteration을 통해 re-training
시간, resource 많이 필요

※ State-Through Estimator(STE)
quantizer(round operation)는 미분 가능하지 않으므로, step-function을 linear하게 만들어서 미분값을 구할 수 있도록 함


Binary Neural Network
- Binary Connect(BC): Weight를 1, -1로 quantization
- Binarized Neural Networks(BNN): Weight와 Activation을 모두 1, -1로 quantization 성능 저하가 너무 큼
- Binary Weight Nets(BWN): Weight를 -a, a / activation은 FP32
- XOR-Net: Weight를 -a, a / activation은 -b, b로
Ternary Networks
- Ternary Weights Nets(TWN): Weights를 -w, 0, w / activation은 FP32
- Trained Ternary Quantization(TTQ): weights를 -w1, 0, w2 / activation 은 FP32
성능 저하 많이 줄임
※ Activation Quantization
ReLU는 큰 값에서 quantization error가 크게 나타남
Clipping은 diminishing gradients가 나타남

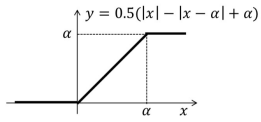
- PArameterized Clipping acTivation(PACT)
ReLU에 Clipping을 넣어서 clipping level(α)을 trainable parameter로 넣음
Reduced-Precision Floating-Point DNN

16-bit Mixed-Precision Training


8-bit DNN Training

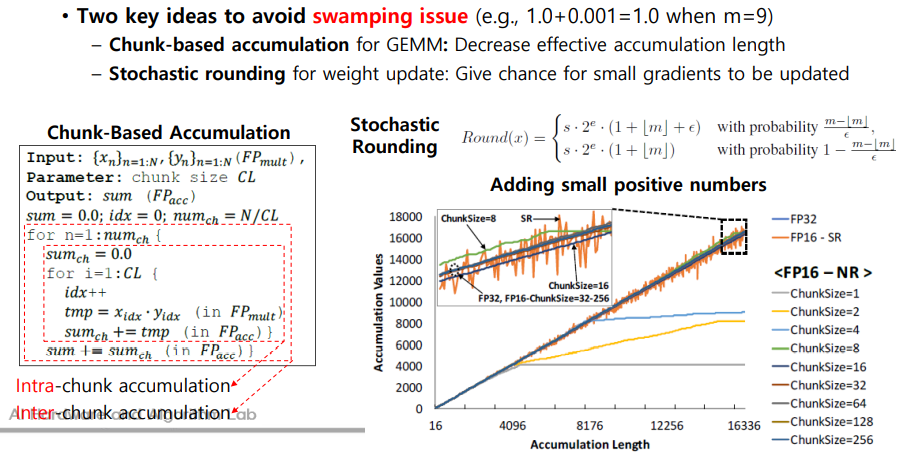
- Chunk-based accumulation
큰 수(1.0) + 작은 수(0.0001) 같은 연산을 할 때, bit수에 의해서 작은 수가 사라질 수 있는데(swamping),
이를 방지하기 위해 수의 크기 별로 chunk를 나누어서, 같은 chunk 별로 더한 후에 chunk끼리 더하는 방식