DNN Accelerator - newlife-js/Wiki GitHub Wiki
by 서울대학교 이재욱 교수님
Performance Analysis
Performance Metrics
Time
- Wall-clock time, response time, elapsed time: time from start to completion
- CPU time: spent time for given program
= seconds/program = (cycles/program) x (seconds/cycle)
= (instructions/program) x (cycles x instruction) x (seconds/cycle)
-> Iron Law of CPU Performance - CPI(Cycles per instruction)

- Factors involve in the CPU Time

ISA: RISC(명령어 세팅 개수가 적음) vs CISC(복잡한 명령어 세팅)
Rate(throughput)
- MIPS(million instructions per second)
MIPS가 클수록 빠른 CPU - MFLOPS(million floating-point operations per second)
Mean
-
Arithmetic mean(performance in times)
∑Execution Times / n
각 benchmark가 같은 횟수만큼 실행된다고 가정
-> Weighted Arithmetic Mean: ∑W x Execution Times / ∑W -
Harmonic Mean(performance in rates)
n / ∑(1/R) -> Weighted Harmonic Mean: ∑W / ∑ (W/R)
Roofline Model
Performance of accelerators
Computation
Floating point performance(GFLOP/sec) is the main target
- peak performance: ample parallelism, balanced combination of floating point inst., rare branch mispredictions, no thread divergence
Communication
DRAM bandwidth(GB/sec) is the main concern
- peak bandwidth: few unit stride access streams, locality-aware NUMA allocation and usage, SW prefetching, memory coalescing
Locality
Maximize cache locality to minimize communication overhead
hardware change: larger cache capacity(capacity miss), higher cache associativity(conflict miss), non-allocating caches(compulsory traffic)
sw optimization: padding avoids conflict misses, blocking avoids capacity misses, non-allocating stores minimize compulsory traffic
Arithmetic Intensity(AI)
Total floating point operations / Total DRAM bytes accesses (FLOP/bytes)
determined by on-chip memory hierarchy, algorithm
Roofline model

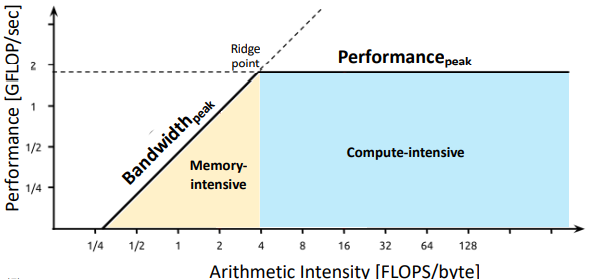
ridge point 부근이 ideal region
program optimization의 가이드라인을 제시해줌
compute bound인지, memory bound인지 파악을 해서 hw 개선이나 sw optimization을 할 수 있음

Benchmark Metrics
Metrics of DNN algorithms
- Accuracy
- Network Architecture: # of layers, filters, channels, filter size
- '# of weights(storage capacity)
- '# of MACs(operation)
Metrics for DNN hardware
- Energy efficiency
- External memory bandwidth
- Area efficiency
MLPerf Benchmark
A broad ML benchmark suite for measuring performance of ML frameworks, ML hardware accelerators, and ML cloud platforms
real-world data에 대해 time, accuracy, cost를 공정하게 비교할 수 있도록 open-source implementation 제공

DNN Accelerator Architectures
Technology Trends
- Moore의 법칙은 이미 깨짐
- CPU to xPU: 특정 연산을 위한 하드웨어 가속기의 유용성 ↑(google TPU), 특정 domain에 맞도록 parallelism, memory bandwidth 등을 최적화
- Rise of AI, Big Data: compute/memory-intensive, parameter size, FLOP, training cost, memory capacity and bandwidth ↑
- Platform war(HW + SW): PyTorch/TensorFlow/MxNet, M1+macOS, Nvidia+Cuda, TPU+Tensorflow
GPU(NVIDIA)
Diffuse Shader나 3D modeling을 위해서 만들어진 processor
data parallelism을 위해 multi-core 사용(Fetch와 Decode 과정은 여러 core가 공유하도록)

DNN을 위해서 Tensorflow 연산이나 Matrix multiplication에 최적화된 모델이 나옴
- Hard DPU(Google TPU)
- Soft DPU(Microsoft BrainWave): FPGA 기반 DNN serving platform
※ Self attention: 매우 큰 연산 오버헤드를 가짐(연산의 30% 이상)
-> ELSA: self-attention HW Accelerator IP(self-attention 연산만을 가속해주는 design)
Challenges in AI Computing Platform Design
-
Cost of Data Movement: energy는 연산보다 data movement에서 대부분 사용됨 '

-> processing-in-memory(PIM), in-storage processing(ISP) -
Memory/Storage Bandwidth and Capacity
-
Addressing Bandwidth/Capacity Bottleneck
Hard DPUs
High-parallel compute paradigms

Memory Access is the bottleneck
매 연산마다 DRAM에 접근하는 것은 비효율적
-> memory hierarchy를 이용해 data 재사용을 함

- Convolutional Reuse(하나의 filter로 sliding window하는 경우): filter weight와 activation 재사용
- Fmap Reuse(여러 filter를 동일한 data에 대해 사용하는 경우): activation 재사용
- Filter Reuse(여러 batch에 대해 동일한 filter 적용하는 경우): filter weight 재사용
Google TPU(Tensor Processing Unit)
TPU v1
Inference만 수행
server에 PCIe를 통해 연결(matrix accelerator on I/O bus)
host server가 instructions을 전달(like a floating point unit)

※ Systolic Execution: energy/time efficiency를 위해 control 과 data를 pipeline으로 구성
동일한 weight에 대해서 연산을 할 때 병렬적으로 계산

TPU v2
Training >> Inference
forward propagation, backward propagation, weight update 모두 해야하기 때문에 tensor의 lifetime이 긺

Soft DPU
Microsoft BrainWave
scalable FPGA-powered DNN serving platform
Fast(ultra-low latency, high-throughput), Flexible(adaptive numerical precision, custom operators), Friendly(turnkey deployment of CNTK/Caffe/TensorFlow)
SW(Compiler and scheduler) plays key roles to achieve high utilization
Xilinx Versal Series
