3. Forecast - nbrown02/FlowViz-Jira GitHub Wiki
The Forecast page provides forecasts for issues at Backlog level (Story, Bug, Task etc.). It excludes forecasting for number of items at any levels higher such as Epic. Subtask issue type is not included in the dataset.
When will it be done?
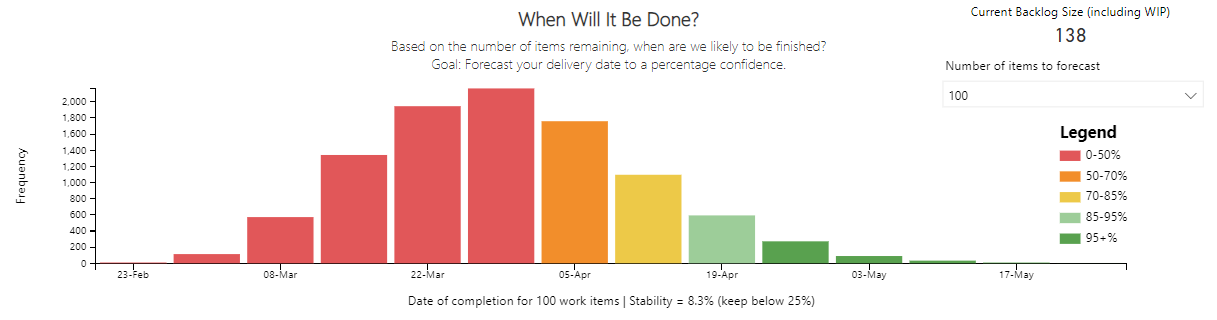
What is this chart and how does it work?
Based on the number of items to forecast (using the drop down), what is the forecast completion date to a percentage likelihood.
The chart runs 10,000 simulations of different scenarios using the historical throughput data of the last 'n' weeks (controlled via the input data range filter). The output is a distribution of these simulations in forecasted completion date, with percentiles of likelihood. As well as this, the throughput stability percentage is shown (aim to keep this below 25%).
The current backlog size number is based on the number of items (Stories, Tasks, Bugs etc.) in the backlog that are not in a To Do or In Progress State Category.
Intended behaviour and misuse
The intended behaviour with this chart is to highlight that software/product development is complex. Traditional estimation from teams normally produces a single result and does not produce a likelihood of meeting that result. More often than not the result presented is only 50% likely due to dividing the remaining work by the average. This means the odds of that result are a coin-toss. This method allows the reader/customer/client to choose the amount of risk they wish to sign-up to, in particular if they want to deliver ‘everything’.
It can be misused in that it only gets used at the beginning of the project/product development. It should be continually inspected as part of your product/project progress. Another common mistake is not throwing away ‘old data’, which is something you should do if context/domain/team size changes. Use this chart to see if ‘everything’ is needed and re-prioritise scope.
What will we get?
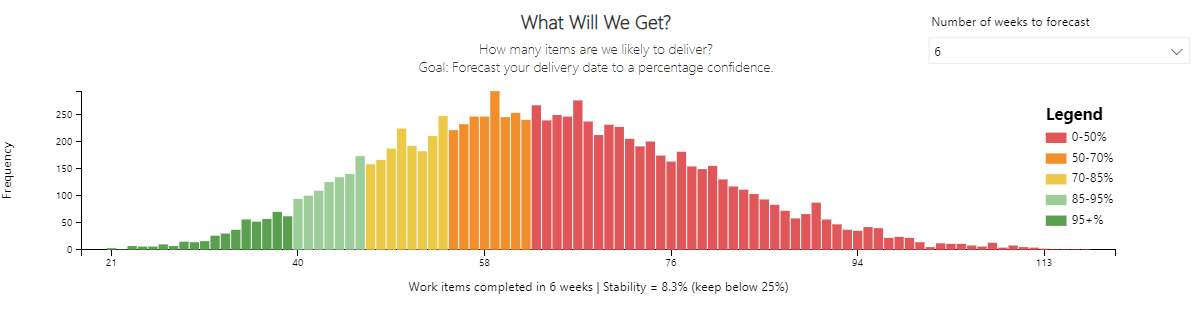
What is this chart?
Based on the number of weeks to forecast (using drop down), what is the percentage likelihood of completing n number of items.
The chart runs 10,000 simulations of different scenarios using the historical throughput data of the last 12 weeks (controlled via the input data range filter). The output is a distribution of these simulations in number of items forecast to be delivered, with percentiles of likelihood. As well as this, the throughput stability percentage is shown (aim to keep this below 25%).
Intended behaviour and misuse
The intended behaviour with this chart is to highlight that software/product development is complex. Traditional estimation from teams normally produces a single result and does not produce a likelihood of meeting that result. More often than not the result presented is only 50% likely due to dividing the remaining work by the average. This means the odds of that result are a coin-toss. This method allows the reader/customer/client to choose the amount of risk they wish to sign-up to, in particular if they want to deliver ‘everything’.
It can be misused in that it only gets used at the beginning of the project/product development. It should be continually inspected as part of your product/project progress. Another common mistake is not throwing away ‘old data’, which is something you should do if context/domain/team size changes. Use this chart to see if ‘everything’ is needed and re-prioritise scope.