G) Semana 7: Algoritmos de busqueda, hashing, pathfinding - natigb/Portafolio-de-Datos-II GitHub Wiki
20/05/2020
Algoritmos de búsqueda
Búsqueda secuencial
Se busca recorriendo una lista, array o vector hasta encontrar el elemento. Tiene una complejidad de O(n).
Búsqueda binaria
Encuentra un número en un array ordenado. Se inicia la búsqueda en el centro del array y si es el valor que se busca retorna el índice y si no es se busca en la mitad del array dependiendo si es menor en la mitad izquierda o mayor en la ,mitad derecha. Tiene una complejidad O(log(N))
Búsqueda por interpolación
Trata de calcular donde está el número, como buscar a un persona en un directorio telefónico. El array debe estar ordenado. Para determinar el centro: middle = low +((number-array[low])*(high- low))/(array[high]-array[low]) y luego el low=middle anterior
Hashing
Mapea grandes conjuntos de datos a conjuntos más pequeños, es un método rápido y permite asignar un índice a un valor.
Es directo porque se aplica una fórmula al valor que le va a dar directamente el índice. Ese indice puede tener dentro una lista o un valor.
Puede mapear varias keys al mismo índice, cada slot en la tabla de hash tiene un conjunto de datos y es llamado un bucket.
La función de hashing tranforma las llaves en indices, la funcion basica de hash es una función de identidad y la funcion ideal es biyectiva o injectiva.
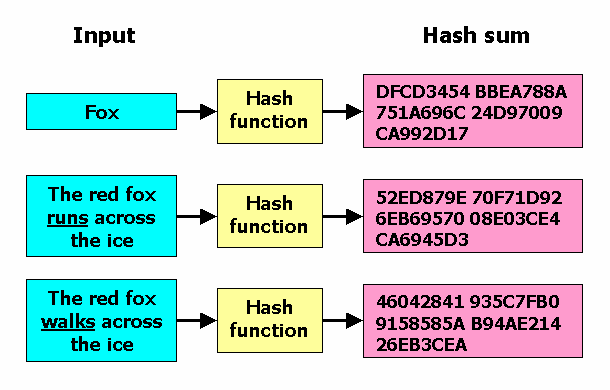
- Arimethic module method: Usar un número primo como divisor y usa el módulo como índice
- Mid-Square method: Utilizar el cuadrado de un valor, tomar r digitos del resultado y siempre va a estar 0 y (2^r)-1
- Truncation method: Ignora parte de la lave y usa el resto como índice.
- Folding method: Divide la llave en partes y las combina con un operador arimetico y uriliza el resultado como índice.
Problema con los hash tables: Colisiones
Son practicamente inevitables, es cuando 2 o mas llaves tienen el mismo índice por malas decisiones en la función de hash.
Se presentan cuando casi que todos los slots que quedan vacios mientras que muy pocos llenos presentan muchas colisiones o cuando las tablas de hash pequeñas tienen muchas llaves y pocos slots. El tratamiento de colisiones puede ser muy costoso computacionalmente.
Pathfinding
Es encontrar la ruta más corta entre 2 puntos. Se utiliza para resolver laberintos. Basados en el algoritmo de Dijkstra y se puede abstraer su funcionalidad diciendo que es un algoritmo que explora los nodos adjacentes y selecciona el que está mas cerca.
Usualmente es implemetado como un algoritmo que se ejecuta sobre una matriz. Cada celda de matriz es un nodo. Son utilizados en juegos de estrategia.
La forma más simple es cuando no hay obstáculos y solo se debe comparar el eje X y Y. Si hay obstáculos hay estrategias:
-
Random Bouncing: si hay obstáculos lo puede hacer de forma aleatoria hasta encontrar el camino pero es muy costoso.
-
Object Tracing: Se va a la meta y si encuentra un obstáculo se selecciona una "pared" y rodea el obstaculo hasta que tiene una forma de ir al objetivo.
-
Breadth- First Search : Basado en los grafos (Recorro el padre, los hijos, los nietos...), revisa las celdas de a la par, luego hace saltos de 2 celdas, de 3 y sigue hasta encintrar el objetivo. Utiliza la cola para recorrerlo. Si hay un recorrido lo va a encontrar pero es ineficiente y los movimientos diaggonales se complican.
-
Distance- First Search:
-
Better heuristic: Basado en la menor distancia al target
22/05/2020
- A*: Es un algoritmo preciso, rápido, uno de los más utilizados en juegos, es muy configurabe para el tipo de juego y mapa particular. Divide el area en celdas, las divide en walkable/unwalkable, El punto cetral de la celda es un nodo y se puede dividir el area en otra forma.
Tiene la formula F=G+H, donde G es el costo para moverse de una celda al objetivo (Puede ser la diagonal con pitágoras) y H el costo de moverse de celda a celda. Para calcular H: - Euclidian distance - Manhattan distance