Examen: 2022_06_29:GISAM - myTeachingURJC/Arq-computadores-01 GitHub Wiki

Examen convocatoria Extraordinaria: 2022-06-29. GISAM
- Tiempo: 2h
- Tipo de examen: Presencial. Realizado a través de Aula Virtual. Acceso a la wiki (internet)
- Objetivo:
- Resolver el problema de examen de la convocatoria ordinadira de GISAM, con fecha 2022/Junio/29
Contenido
Enunciado
El examen se ha realizado a través de Aula virtual
Problema 1 (2.5 ptos): Rendimiento
Las instrucciones de un procesador están divididas en 3 grupos: A, B y C. Tres fabricantes han implementado su propio procesador, usando el mismo repertorio de instrucciones. En esta tabla se muestran los CPI de cada grupo de instrucciones para cada procesador:
| Procesador | Freq (Ghz) | A | B | C |
|---|---|---|---|---|
| P1 | 1 | 1 | 2 | 3 |
| P2 | 1.5 | 1 | 1 | 3 |
| P3 | 2.0 | 2 | 3 | 3 |
Para evaluar su rendimiento se ejecuta un programa de prueba que tiene 2 millones de instrucciones, compuesto de un 20% de instrucciones de tipo A, un 40% de tipo B y un 40% de tipo C
a) ¿Qué procesador tiene mejor rendimiento? (1.5 ptos)
b) ¿Cuánto mejor es el procesador de mayor rendimiento con respecto a los otros dos? (1 pto)
Problema 2 (2.5 ptos): Ordenacion/alineaiento/direccionamiento
Tenemos un computador de 64-bits que dispone de 32 registros de propósito general (x0-x31). La ordenación que usa es little-endian. Para acceder a los datos de la memoria utiliza un direccionamiento indirecto con desplazamiento. Puede acceder tanto a datos alineados como no alineados. Estas son algunas de las instrucciones disponibles:
li rd, valor: Carga del valor inmediato en el registro rdlb rd, off(rs1): Leer un byte de memoria y guardarlo en rdlh rd, off(rs1): Leer una media palabra de memoria y guardarla en rdlw rd, off(rs1): Leer una palabra de memoria y guardarla en rdld rd, off(rs1): Leer una doble palabra de memoria y guardarla en rdsb rs1, off(rs2): Almacenar en memoria el byte que hay en rs1sh rs1, off(rs2): Almacenar en memoria la media palabra que hay en rs1sw rs1, off(rs2): Almacenar en memoria la palabra que hay en rs1sd rs1, off(rs2): Almacenar en memoria la doble palabra que hay en rs1
Este es un volcado de la memoria, correspondiente a las direcciones que comienzan en 0xE010 y 0xF000. Los valores están en HEXADECIMAL
| Dir | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xE010 | FF | A8 | 18 | 73 | 10 | 20 | 30 | 40 | CA | FE | BA | CA | DA | BA | CA | CA |
| 0xF000 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Se pide:
a) (1.5 ptos) Indicar el valor de los registros del x1 al x5 cuando se ejecutan estas instrucciones (secuencialente):
li x1, 0xE010
lb x2, 7(x1)
lh x3, 1(x1)
lw x4, 4(x1)
ld x5, 8(x1)
b) (1 pto) Suponiendo que inicialmente los registros del x1 al x5 contienen los siguientes valores: x1=0,x2=0x73, x3=0x1801, x4=0x40302010, x5=0xCACABADACABAFECA
Escribe el contenido de los 16 bytes de memoria situados desde la dirección 0xF000 en adelante al terminar de ejecutarse las siguientes instrucciones:
li x1, 0xF000
sb x2, 8(x1)
sh x3, 9(x1)
sw x4, 0xB(x1)
sd x5, 0(x1)
Pregunta 3 (2.5 Puntos): Circuitos lógicos
Dado el siguiente circuito
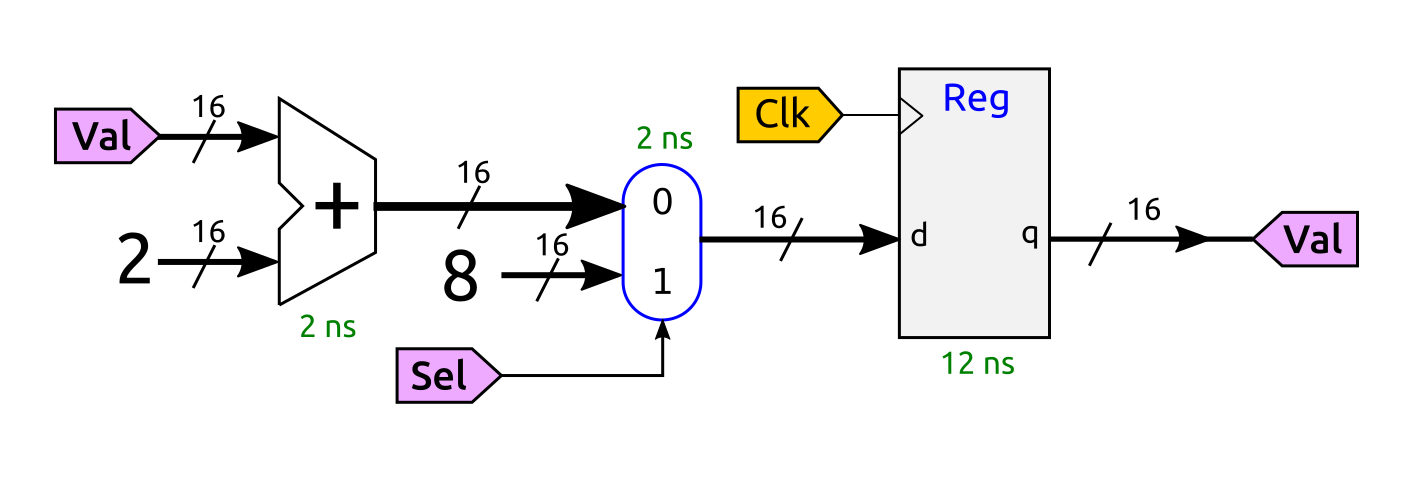
- a) Explica brevemente la estructura y componentes de este circuito (0.5)
- b) Calcula el retardo de la parte combinacional (0.5)
- c) Calcula la frecuencia máxima de funcionamiento a la que podría funcionar (0.5)
- d) Si inicialmente todas las señales están a 0, indica el valor del registro transcurridos 3 ciclos de reloj. La señal Sel está todo el tiempo a 0 y el valor inicial del registro es 0 (0.5)
- e) ¿Qué ocurre cuando Sel se pone a 1 durante varios ciclos de reloj? (0.5)
Problema 4 (2.5 ptos): Computador nanoRiscV
Tenemos un computador nano-RISCV como el mostrado en la siguiente figura

El retardo de lectura de la memoria ROM es de 20ns. La memoria RAM tiene un retardo de lectura de 30ns y de 20ns para la escritura.
También se conocen los retardos de las siguientes fases, que son iguales para todas las instrucciones:
- Decodificación: 5 ns
- Ejecución: 5 ns
- Write-back: 0ns
Las fases de Fetch y acceso a memoria están determinadas por los retardos de las memorias utilizadas
El resto de retardos se consideran despreciables (0 ns)
Se pide:
a) (0.6 ptos) Calcula cuál es el retardo de la fase de Fetch
b) (0.6 ptos) Calcula el tiempo que tardan las instrucciones de tipo R
c) (0.6 ptos) Calcula el tiempo que tarda la instrucción ld
d) (0.7 ptos) Calcula la frecuencia máxima de funcionamiento de este computador
Solución al examen
Problema 1 (2.5 ptos): Rendimiento
a) Tendrá mejor rendimiento el procesador que ejecute el programa más rápidamente, es decir, el que tarde menos tiempo. Para ello calculamos primero el número de ciclos que tarda cada procesador, y dividimos por su frecuencia. Usamos N para representar el número de instrucciones totales del programa de prueba
- P1: Ciclos =
N*0.2*1 + N*0.4*2 + N*0.4*3 = N[0.2 + 0.8 + 1.2] = N * 2.2= 4.4 millones de ciclos - P2: Ciclos =
N*0.2*1 + N*0.4*1 + N*0.4*3 = N[0.2 + 0.4 + 1.2] = N * 1.8= 3.6 millones de ciclos - P3: Ciclos =
N*0.2*2 + N*0.4*3 + N*0.4*3 = N[0.4 + 1.2 + 1.2] = N * 2.8= 5.6 millones de ciclos
Dividiendo por la frecuencia de cada uno obtenemos el tiempo:
- Tcpu_1 =
4.4*10^6 / 10^9= 4.4ms - Tcpu_2 =
3.6*10^6 / 1.5*10^9= 2.4ms - Tcpu_3 =
5.6*10^6 / 2*10^9= 2.8ms
El procesador con mejor rendimiento es el P2
b) Para comparar procesadores utilizamos el rendimiento relativo (n)
- n = R2 / R1 = Tcpu_1 / Tcpu_2 = 4.4 / 2.4 = 1.83. P2 es 1.83 veces más rápido que P1
- n = R2 / R3 = Tcpu_3 / Tcpu_2 = 2.8 / 2.4 = 1.17. P2 es 1.17 veces más rápido que P3
Problema 2 (2.5 ptos): Ordenacion/alineaiento/direccionamiento
a)
x1 = 0xE010. Asignado por la instruccion li (direccionamiento inmediato)x2 = 0x40. Se lee el Byte situado en la direccion E010 + 7x3 = 0x18A8. Se lee la media palabra (2 bytes) de la direcion E010 + 1. El byte de E011 es el de menos peso (A8)x4 = 0x40302010. Se lee la palabra (4 bytes) de la direccion E010 + 4. El byte de E014 es el de menor peso (10)x5 = CACABADACABAFECA. Se lee la doble palabra (8 bytes) de la direccion E010 + 8. El byte de E018 es el de menor peso (CA)
b)
- Se accede siempre a la direccion base 0xF000
- El byte 0x73 se guarda en F000 + 8
- La media palabra 0x1801 se guarda en F000 + 9. En F009 se almacena el byte de menor peso (01)
- La palabra 0x40302010 se guarda en F000 + B. En F00B se almacena el byte de menor peso (10)
- La doble palabra 0xCACABADACABAFECA se guarda en F000 + 0. Se almacena el byte de menor peso en F000 (CA)
El contenido de la memoria es (comenzando por la dirección F000):
0xCA, 0xFE, 0xBA, 0xCA, 0xDA, 0xBA, 0xCA, 0xCA, 0x73, 0x01, 0x18, 0x10, 0x20, 0x30, 0x40, 0x00
Si lo representamos en un tabla quedaría así:
| Dir | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0xE010 | FF | A8 | 18 | 73 | 10 | 20 | 30 | 40 | CA | FE | BA | CA | DA | BA | CA | CA |
| 0xF000 | CA | FE | BA | CA | DA | BA | CA | CA | 73 | 01 | 18 | 10 | 20 | 30 | 40 | 0 |
Pregunta 3 (2.5 Puntos): Circuitos lógicos
- a) Explica brevemente la estructura y componentes de este circuito (0.5)
El circuito está formado por la conexión en anillo de un registro de 16 bits (parte secuencial) con otro circuito combinacional, que a su vez está dividido en un sumador de 16 bits y un multiplexor (ambos combinacionales)
- b) Calcula el retardo de la parte combinacional (0.5)
El retardo de la parte combinacional lo determina el camino que va desde la salida del registro hasta llegar otra vez a su entrada: 2ns (sumador) + 2ns (mux) = 4ns
- c) Calcula la frecuencia máxima de funcionamiento a la que podría funcionar (0.5)
Para el cálculo de la frecuencia máxima tenemos que calcular el tiempo mínimo que transcurre desde que hay un dato estable en la entrada del registro hasta que llega un nuevo dato estable. Este tiempo es de: 4ns + 12ns = 16ns. Por tanto, la frecuencia máxima de funcionamiento es de: 1 / 16ns = 62.5Mhz
- d) Si inicialmente todas las señales están a 0, indica el valor del registro transcurridos 3 ciclos de reloj. La señal Sel está todo el tiempo a 0 y el valor inicial del registro es 0 (0.5)
Como la señal sel está a 0, lo que llega a la entrada del registro es su propio valor incrementado en dos unidades (configuración típica en anillo). Por tanto, en el primer ciclo se captura un 2, en el segundo un 4 y en el tercero habrá un 6
-
e) ¿Qué ocurre cuando Sel se pone a 1 durante varios ciclos de reloj? (0.5)
Cuando sel se pone a 1, lo que llega a la entrada del registro es un 8, por lo que el registro se carga con ese valor inicial. Mientras sel valga 1, el registro valdrá 8. Al ponerse sel a 0 de nuevo la cuenta continúa (pero esta vez empezando en 8)
Problema 4 (2.5 ptos): Computador nanoRiscV
a) En la fase de Fetch es donde se cargan las instrucciones de la memoria ROM. Su retardo está determinado por el retardo de lectura de la memoria ROM que es de 20ns. El resto de retardos es cero, por tanto:
Retardo Fetch = 20 ns
b) En el caso de las instrucciones de tipo R, que en el nano-RISC son add, sub, and y or, NO hay fase de acceso a memoria. Los retardos de estas instrucciones están datos por:
retardo_R = R_fetch + R_decodificación + R_ejecución + R_memoria + R_writeback = 20ns + 5ns + 5ns + 0ns + 0ns = 30ns
c) La instrucción ld además de los retardos anteriores (que en este ejemplo son iguales para todas las instrucciones) tenemos el retardo debido a la lectura de los datos de la memoria RAM, que es de 30ns. Por tanto, el retardo de ls es de 20ns + 5ns + 5ns + 30ns + 0ns = 60ns
d) Para calcular la frecuencia máxima necesitamos conocer el caso peor (la instrucción más lenta). La instrucción de beq y de sd, en este problema, tienen los mismos retrasos que las instrucciones R
La escritura en la memoria RAM tarda 20ns, pero se realiza en paralelo con las fases de fetch y decodifación por lo que no forma parte del retardo del ciclo actual
Por ello, la instrucción que más tarda es ld, y por ello, la frecuencia máxima está dada por fmax = 1 / 60ns = 16.7 MHZ (aprox).
Autores
- Katia Leal Algara
- Juan González-Gómez (Obijuan)

Licencia
