Systemy kontroli wersji - miwanek/Omami GitHub Wiki
Systemy kontroli wersji
Podróż w czasie to koncept, który prawdopodobnie każdemu z nas kiedyś krążył po głowie. Jak wielu niedogodnościom i cierpieniom moglibyśmy zapobiec gdybyśmy tylko mogli cofnąć błędy, które popełniliśmy w przeszłości? Na nasze szczęście podróż w czasie istnieje, a narzędzia, które ją umożliwiają są powszechnie dostępne i w wielu przypadkach darmowe, a kryją się pod nazwą “Systemy kontroli wersji”.
Czym są systemy kontroli wersji?
Systemy kontroli wersji to programy umożliwiające śledzenie wszystkich zmian jakie wpłynęły na aktualny stan określonego pliku. Pozwala nam to na przywrócenie dowolnej wersji tego pliku z przeszłości jeżeli proces jego rozwoju pójdzie w złym kierunku. Systemy kontroli wersji możemy podzielić na 3 kategorie:
- Lokalne
- Scentralizowane
- Rozproszone
Każda z kategorii ma swoje wady i zalety, a umiejętność odpowiedniego ich wykorzystania jest kluczowa do prawidłowego rozwoju projektów.
Lokalne systemy kontroli wersji
Założeniem lokalnych systemów kontroli wersji jest to, że wszelkie zmiany, które nastąpiły w śledzonych plikach przetrzymywane są na urządzeniu, na którym te pliki się znajdują. Ma to swoje zastosowania - niestety bardzo wąskie, ze względu na to, że nad projektami często pracuje wiele osób, a pozostałe dwie kategorie systemów kontroli wersji posiadają bardzo praktyczny skutek uboczny w postaci ułatwienia współpracy między deweloperami. Kolejną wadą tego rozwiązania jest to, że projekt i wszystkie zmiany, które w nim zaszły zależą tylko od jednego urządzenia co sprawia, że awaria systemu lub plików odpowiedzialnych za śledzenie zmian może wiązać się z utratą całej historii projektu, a żeby się przed tym zabezpieczyć musimy samodzielnie wykonywać kopie zapasowe. Jednak jeżeli pracujemy nad projektem samotnie to korzystanie z lokalnego systemu kontroli wersji może być dobrym rozwiązaniem jeżeli projekt, nie jest bardzo istotny, a szybkość konfiguracji jest ważniejsza niż bezpieczeństwo projektu w razie awarii urządzenia.
Scentralizowane systemy kontroli wersji
Scentralizowane systemy kontroli wersji pozbywają się jednej kluczowej wady systemów lokalnych - repozytorium przechowywane jest na dostępnym dla wielu osób serwerze, a więc umożliwia to współpracę między deweloperami, którzy mogą dzięki temu razem pracować nad tymi samymi plikami.
Rozproszone systemy kontroli wersji
Najpopularniejszą kategorią systemów kontroli wersji są zdecydowanie systemy rozproszone, które są w gruncie rzeczy hybrydą pomiędzy systemami lokalnymi oraz scentralizowanymi. Koncept polega na tym, że każdy deweloper posiada lokalne repozytorium, które połączone jest z repozytorium utrzymywanym na dostępnym dla współpracujących osób serwerze. Umożliwia to lokalną pracę nad projektem z zachowaniem możliwości lokalnej kontroli wersji i udostępnianie wyników naszej pracy dopiero wtedy gdy jesteśmy nią usatysfakcjonowani. Dodatkową zaletą jest to, że w skutego istnienia wielu wersji lokalnych naszego repozytorium jest ono dużo odporniejsze na awarie pojedynczych systemów oraz serwera, na którym znajduje się wersja zdalna.
Rozproszony vs. scentralizowany
Podczas gdy systemy lokalne nie oferują wiele i nie są żadną konkurencją dla systemów scentralizowanych oraz rozproszonych (z uwagi na nieistniejące wsparcie dla współpracy), to pozostałe 2 zdają się funkcjonalnie oferować to samo, a więc zobaczmy czym się różnią.
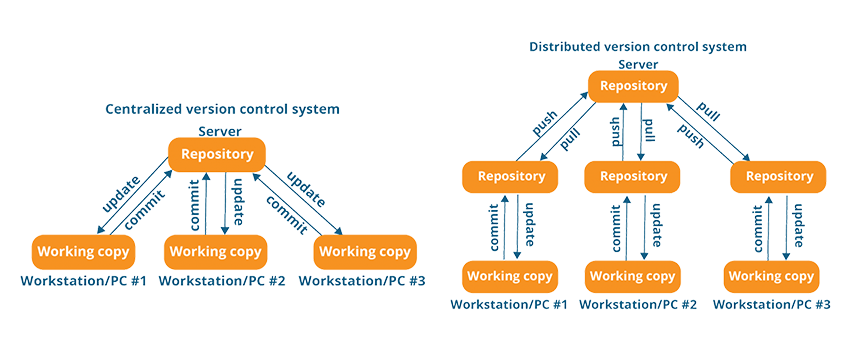
Patrząc na grafikę powyżej możemy zauważyć, że faktycznie finalnie efekt pracy powinien być ten sam. Mamy serwer oraz urządzenia lokalne, które komunikują się ze sobą w celu synchronizacji plików. Różnica polega na sposobie tej komunikacji. W systemach scentralizowanych po wprowadzeniu zmian w plikach “commitujemy” je, a więc wysyłamy informację do naszego repozytorium na serwerze, że wprowadziliśmy zmiany i w tym momencie serwer aktualizuje swoje wersje plików, a powiązane urządzenia dbają o to aby ich wersje były zgodne z tym co jest na serwerze. W celu uniknięcia problemów wynikających z jednoczesnej pracy kilku osób nad jednym plikiem często wykorzystuje się tu mechanizm blokowania plików, a więc jeśli jedno urządzenie jest w trakcie edytowania danego pliku, to reszta traci tę możliwość aż do momentu zsynchronizowania zmian i odblokowania pliku. Systemy rozproszone charakteryzują się dodatkową, lokalną warstwą pośrednią pomiędzy serwerem, a lokalnymi plikami. Jeżeli dokonujemy zmian w pliku to najpierw “commitujemy” je do swojej lokalnej kopii repozytorium, a następnie dopiero na nasze życzenie kopia ta synchronizuje się (push) z wersją zdalną, z której wszyscy współpracownicy (także na życzenie) mogą “zapullować” nowe zmiany. Ten system w większym stopniu pozwala na niezależność zmian lokalnych na każdym urządzeniu i nie posiada (zazwyczaj) mechanizmu blokowania plików, a więc nic nie stoi na przeszkodzie aby 6 osób w tym samym czasie edytowało jeden plik - potem po prostu trzeba będzie zadbać o odpowiednie rozwiązania konfliktów pomiędzy równoległymi wersjami. Ryzyko konfliktów nie jest jednak wystarczającą wadą aby przyćmić benefity jakie daje nam takie rozwiązanie, a rozwiązywanie konfliktów przy plikach tekstowych zazwyczaj jest najwyżej lekką niedogodnością. No, ale właśnie… To wszystko brzmi bardzo dobrze kiedy ograniczymy się do plików tekstowych…
Pliki binarne
Na pierwszy rzut oka systemy rozproszone wydają się rozwiązaniem idealnym i prawdopodobnie w wielu przypadkach będą idealne, ale rozwiązanie to posiada jedną wadę, która może okazać się bardzo istotnym problemem - wersjonowanie dużych plików binarnych. Systemy kontroli wersji są zazwyczaj dostosowane do pracy z plikami tekstowymi, zręcznie wykrywają, które konkretnie linijki w pliku źródłowym uległy zmianie, przez co, i tak już lekkie, pliki tekstowe wersjonowane są na zasadzie konkretnych, bardzo precyzyjnie określonych zmian wewnątrz nich. A więc nawet przy bardzo długiej pracy nad jednym projektem historia zmian, które zaszły w istniejących w nim plikach tekstowych nie powinna nabrać żadnej znaczącej wagi. Co się dzieje jeśli wersjonujemy pliki binarne? Po pierwsze każdy taki plik musi w całości zostać dodany do repozytorium i chociaż wiele systemów zapewnia, że przetrzymywanie kolejnych wersji takich plików jest zoptymalizowane i śledzenie zmian w nich nie jest dużo cięższe od śledzenia zmian plików tekstowych, to jednak z dużym prawdopodobieństwem nasze “zmiany” w nich opierają się częściej na usunięciu starego pliku i dodaniu nowego - naszej nowej wersji lub i tak mają ogromne odzwierciedlenie w kodzie binarnym pliku. W wyniku tego każda wersja pliku binarnego, która pojawiła się w historii naszego projektu będzie miałą rozmiar przybliżony do tego pliku i zostanie na naszym repozytorium nawet jeżeli plik usuniemy. Wiąże się to z tym, że repozytoria przechowujące takie pliki potrafią się bardzo szybko rozrastać i osiągać wagi budzące trwogę nawet w największych twardzielach. I tutaj też zwróćmy uwagę o ile większy jest ten problem w systemach rozproszonych niż w systemach scentralizowanych - o ile poświęcenie jednego serwera na przetrzymywanie takiej ilości informacji, może nie być aż tak dużym problemem, to wymóg przetrzymywania tych danych u każdego dewelopera pracującego nad danym projektem lokalnie może, w przypadku naprawdę wielkich rozmiarów, być nieakceptowalny, a nawet przy mniejszych rozmiarach doprowadza do znacznych spadków płynności pracy z repozytorium. Problem ten oczywiście nie pozostaje bez rozwiązania, jednak wymaga on zwykle trochę dodatkowego wysiłku. W przypadku najpopularniejszego systemu kontroli wersji jakim jest Git zostało stworzone narzędzie Git LFS (Large File Storage), które umożliwia przetrzymywanie w repozytorium jedynie “wskaźników” na dany plik binarny, którego historia edycji przetrzymywana będzie na zupełnie innym - scentralizowanym repozytorium. Narzędzie to rozszerza możliwości Gita praktycznie niezauważalnie dla przeciętnego użytkownika - z plikami binarnymi pracujemy dokładnie tak samo jak zazwyczaj, a całe zarządzanie nimi rozgrywa się już automatycznie bez wymuszania żadnych dodatkowych działań człowieka. Ważne jest to, że Git LFS instalujemy u siebie lokalnie, reszta osób korzystających z repozytorium także musi mieć to narzędzie skonfigurowane - w przeciwnym wypadku po pullowaniu plików binarnych pozostaniemy z samymi “wskaźnikami” bez właściwych plików. Git LFS wciąż jest dość młodym systemem i cały czas się rozwija (w trybie open source), więc wiele osób wciąż nie poleca używać go do trzymania naprawdę dużych repozytoriów ze względu na problemy ze stabilnością, które ciągle mu się zdarzają. Starszym i bardziej stabilnym rywalem Git LFS jest działający na podobnych zasadach jest system Mercurial z rozszerzeniem Largefiles. Standardem i prawdopodobnie najczęściej używanym systemem w projektach z dużą ilością plików binarnych jest system Perforce, który jest stworzony głównie z myślą o właśnie tego typu projektach. Niestety Perforce nie jest darmowy… Problem plików binarnych jest czymś o czym warto wiedzieć i co warto mieć na uwadze w planowaniu swojego systemu kontroli wersji, ale tak naprawdę dotyczy on wąskiego grona projektów - takich, w których pliki binarne stanowią dużą część projektu i współpraca bez ich stałej synchronizacji pomiędzy deweloperami nie jest możliwa, a zmiany pojawiają się w nich często. Prawdopodobnie najczęściej do tej kategorii trafiają gry komputerowe, w których ogromna ilość grafik i/lub modeli trójwymiarowych decyduje o przewadze rozwiązań, które pozwalają sobie z nimi radzić.
Podsumowując
Jak widać mimo dominującej przewagi popularności systemu rozproszonego (Git), na rynku dalej jest miejsce na inne narzędzia do podróży w czasie, a wybór może nie być tak oczywisty jak mogłoby się wydawać. Mam więc nadzieję, że teraz, drogi Czytelniku, jesteś gotowy na atak plików binarnych i jeżeli będzie trzeba, to skutecznie znajdziesz alternatywę dla klasycznego, czystego gita.
P.S. Zachęcam też do zapoznania się z tematem “Git Attributes”, który jest wystarczająco szeroki aby napisać o nim kolejny artykuł, ale może między innymi trochę ułatwić pracę z plikami binarnymi w klasycznym repozytorium Git. :)