[기계학습][5주차] 다중선형회귀 이론 - mingoori0512/minggori GitHub Wiki
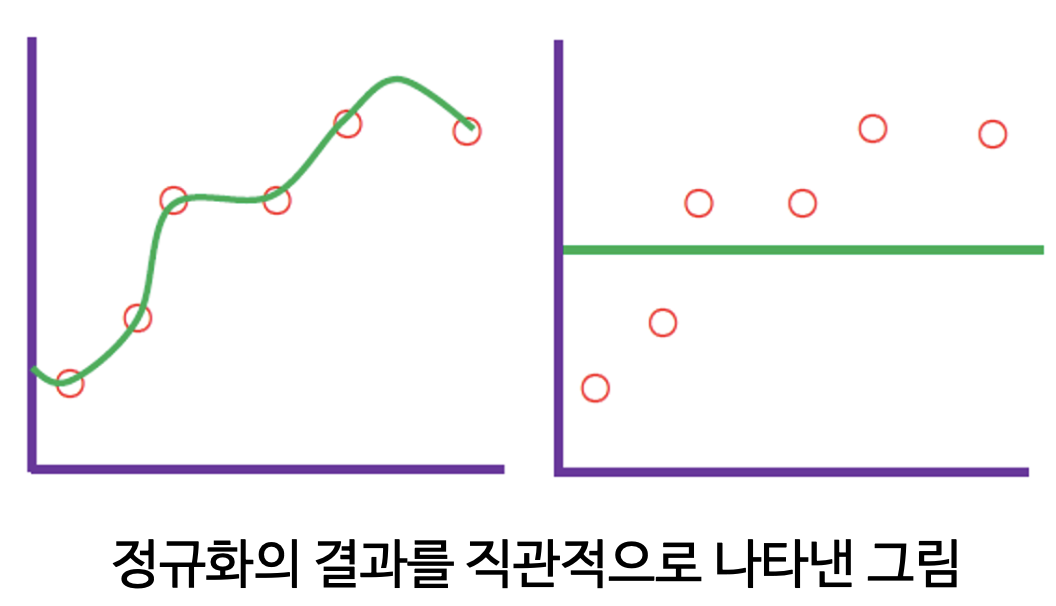
정규화
-정규화란?
- 회귀계수가 가질 수 있는 값에 제약조건을 부여하여 미래 데이터에 대한 오차 기대
- 미래 데이터에 대한 오차의 기대 값은 모델의 Bias와 variance로 분해 가능.
- 정규화는 variance를 감소시켜 일반화 성능을 높이는 기법(단, 이 과정에서 bias가 증가할 수 있음)
- 학습 데이터를 잘 갖추고 있지만, 미래 데이터가 조금만 바뀌어도 예측값이 들쭉날쭉할 수 있음
- 강한 수준의 정규화를 수행한 결과로 학습 데이터에 대한 설명력을 다소 포기하는 대신 미래 데이터 변화에 상대적으로 안정적인 결과를 나타냄
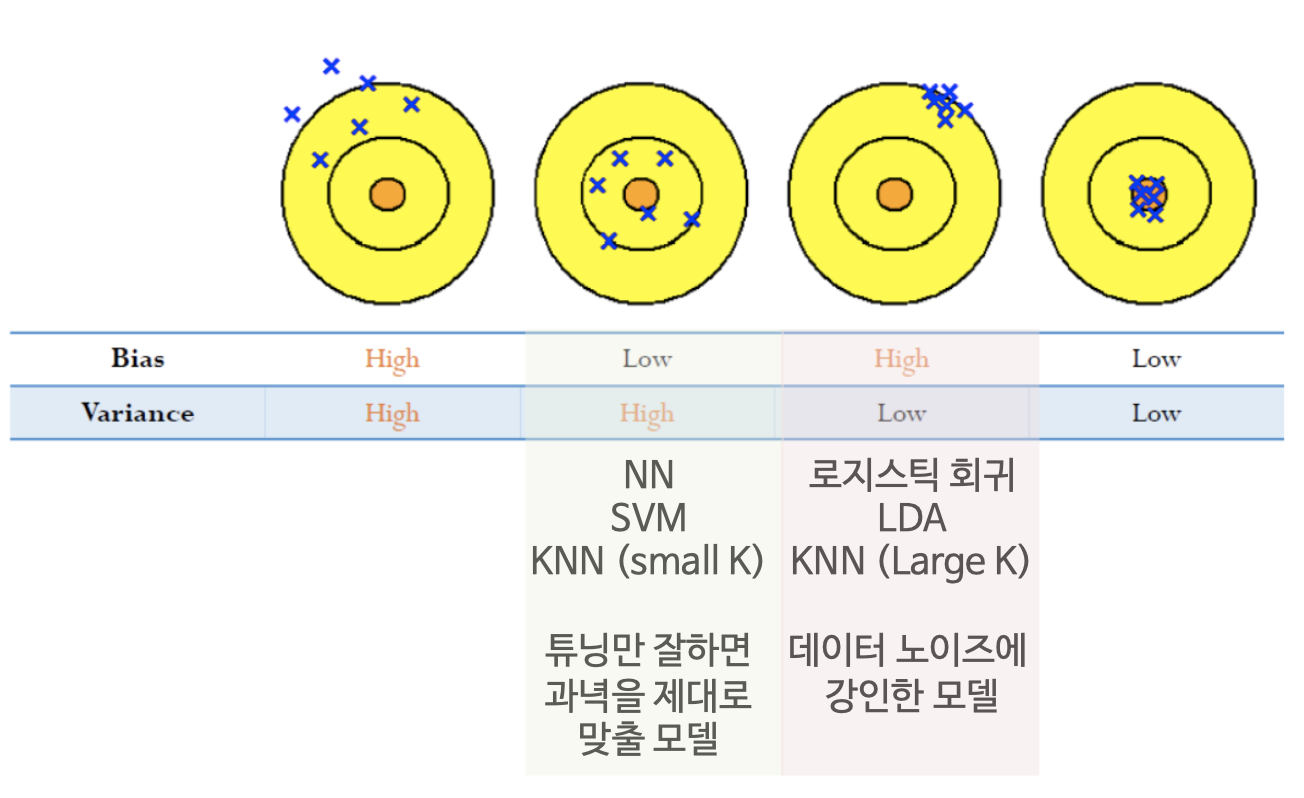
Bias-Variance Decomposition
- Bias-Variance Decomposition란?
- 일반화(generalization) 성능을 높이는 정규화(Regularization), 앙상블(ensemble) 기법의 이론적 배경
- 학습에 쓰지 않은 미래 데이터에 대한 오차의 기대값을 모델의 Bias와 Variance로 분해하자는 내용
- Bias-Variance의 직관적인 이해
- 첫번째 그림을 보면 예측값(파란색 엑스표)의 평균이 과녁(Truth)과 멀리 떨어져 있어 Bias가 크고, 예측값들이 서로 멀리 떨어져 있어 Variance 또한 큼.
- 네번째 그림의 경우 Bias와 Variance 모두 작음. 제일 이상적임
* 부스팅(Boosting)은 Bias를 줄여 성능을 높이고, 라쏘회귀(Lasso Regression)는 Variance를 줄여 성능을 높이기는 기법임