Comparing performance of Bling Fire and Hugging Face Tokenizers - microsoft/BlingFire GitHub Wiki
Comparing performance of Bling Fire and Hugging Face Tokenizers
We did a speed comparison of Hugging Face Tokenizers and Bling Fire. Both libraries were used to create numpy arrays of 128 elements each with ids for BERT BASE model. The input was a text file in UTF-8 encoding with training data (question, answer pairs) 510 MB in size. The goal of the benchmark to see how much time it takes to process this file on one thread.
We used this code for Bling Fire:
import sys
from blingfire import *
import argparse
import numpy as np
np.set_printoptions(linewidth=72)
parser = argparse.ArgumentParser()
parser.add_argument("-m", "--model", default="./bert_base_tok.bin", help="bin file with compiled tokenization model")
parser.add_argument("-s", "--no-output", default=False, help="No output, False by default")
parser.add_argument("-n", "--no-process", default=False, help="No process, False by default")
args = parser.parse_args()
h = load_model(args.model)
for line in sys.stdin:
line = line.strip()
if not args.no_process:
ids = text_to_ids(h, line, 128, 100)
if not args.no_output:
print(line)
print(ids)
free_model(h)
We used this code for Hugging Face tokenizers:
import sys
import argparse
import numpy as np
from tokenizers import (ByteLevelBPETokenizer, BPETokenizer, SentencePieceBPETokenizer, BertWordPieceTokenizer)
np.set_printoptions(linewidth=72)
parser = argparse.ArgumentParser()
parser.add_argument("-m", "--model", default="./vocab.txt", help="bin file with compiled tokenization model")
parser.add_argument("-i", "--ignore-case", default=True, help="ignore case, True by default")
parser.add_argument("-s", "--no-output", default=False, help="No output, False by default")
parser.add_argument("-n", "--no-process", default=False, help="No process, False by default")
args = parser.parse_args()
tokenizer = BertWordPieceTokenizer(args.model, lowercase=args.ignore_case, add_special_tokens=False)
for line in sys.stdin:
line = line.strip()
if not args.no_process:
output = tokenizer.encode(line)
ids = output.ids
padded_ids = [0]*128
for i in range(min(128, len(ids))):
padded_ids[i] = ids[i]
padded_ids = np.array(padded_ids)
if not args.no_output:
print(line)
print(padded_ids)
For completeness we also ran the original code:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import sys
import tensorflow as tf
import tokenization
import numpy as np
class TokenizationTest(tf.test.TestCase):
def test_full_tokenizer(self):
tokenizer = tokenization.FullTokenizer(vocab_file="./vocab.multi_cased.txt", do_lower_case=False)
for line in sys.stdin:
line = line.strip()
tokens = tokenizer.tokenize(line)
ids = tokenizer.convert_tokens_to_ids(tokens)
padded_ids = [0]*128
for i in range(min(128, len(ids))):
padded_ids[i] = ids[i]
# no output
# print(line)
# print(np.array(padded_ids))
self.assertAllEqual([1], [1])
if __name__ == "__main__":
tf.test.main()
We ran each program 3 times and picked the fastest time out of three. The exact command line parameters and output see below:
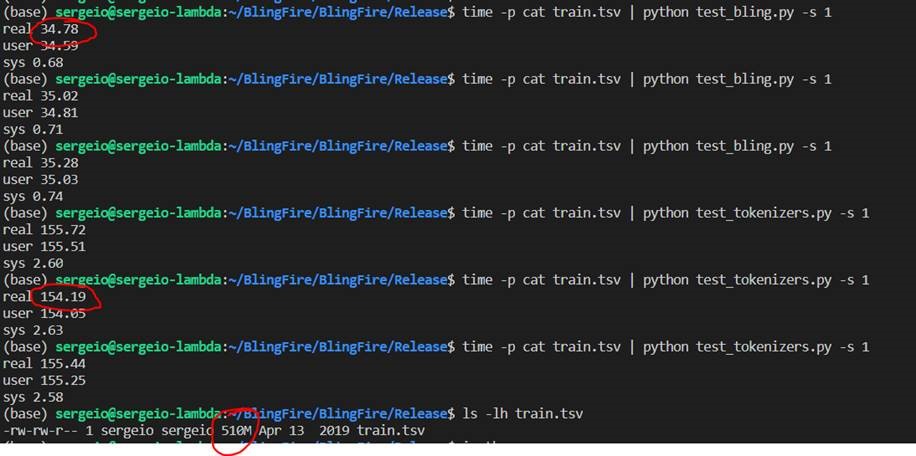
Results
The simple math with numbers above gives us:
- Bling Fire: 15 MB/s
- Hugging Face Tokenizers: 3.3 MB/s
- Original BERT implementation: 0.4 MB/s
P.S. We did not observe claimed 50 MB/s speed from Hugging Face tokenizers, it is either they used multiple threads or we did not measure it correctly. If that is the case please open an issue and we will measure again, but in the meantime, if you need low latency use Bling Fire!