Group Replication Technical Details - malongshuai/MySQL-Group-Replication GitHub Wiki
9.Group Replication Technical Details
组复制技术的细节
本节提供MySQL组复制的更多技术细节。
9.1 Group Replication Plugin Architecture
组复制插件的架构
MySQL组复制是一个MySQL插件,它基于现有的MySQL复制基础,利用了基于行格式的二进制日志和GTID等特性。下图是MySQL组复制的整体框架图。
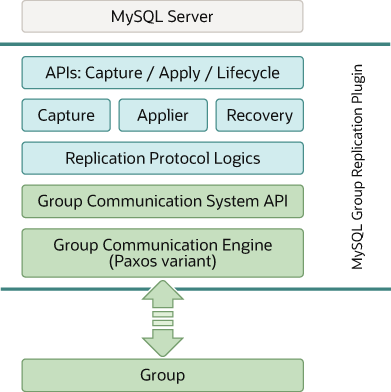
从上图的最顶端开始,有一系列的API控制组复制插件如何和MySQL Server进行交互(图中灰色方框)。中间有一些接口可以使得信息从MySQL Server流向组复制插件,反之亦然。这些接口将MySQL Server核心部分和插件隔离开来,并且大多数钩子(hook)都位于事务执行管道中(pipeline)。在Server到插件的方向上,传递一些通知信息,例如server正在启动,server正在恢复,server已准备好接收连接,server将要提交事务等等。另一方向,即插件到server的方向上,插件会通知 server对事务进行提交,终止正在进行的事务,将事务放进relay-log中排队等等。
从API往下,是一些响应组件,当通知信息路由到它们身上时就响应。capture组件负责跟踪正在执行的事务的上下文信息。applier组件负责在本节点上执行远程传输来的事务。recovery组件负责管理分布式恢复过程,还负责在节点加入组时选择donor,编排追赶过程以及对选择donor失败时的反应(译注:新节点加入组之前先要选择donor,并从donor上获取缺失的数据以便赶上组中已有的数据。即先和组中数据同步,然后才能加入到组)。
继续向下,replication协议模块包含了特定的复制协议逻辑。它负责探测冲突,在组中接收和传播事务。
最后两层是组内通信系统(GCS)的API(第一个绿色方框),以及一个基于Paxos组通信引擎的实现(implementation)(第二个绿色方框)。GCS API是组内通信API,它是一个上层API,它抽象了构建一个复制状态机(状态机在本章最前面的背景知识中解释过)所需的属性,它从插件的更上层解耦了消息传递层。组通信引擎负责处理组内成员的通信。
9.2 The Group
组复制中的(复制)组
在MySQL组复制中,一系列节点组成一个复制组。复制组有名称,名称形式为UUID。复制组是动态的,任何时候,组内成员都可以离开(既可以是自愿离开,也可以非自愿离开),组外成员也可以加入。当出现离组、加组的情况,组会自动调整它自身,以接受新的组配置。
如果一个节点加入组,它会自动从组内某个成员身上抓取它所缺失的那部分数据以便和组数据保持同步。这个状态是通过MySQL异步复制来实现的。如果节点离开组,例如出于维护的目的而停止mysql实例,剩余的节点会意识到它的离开,然后会自动重新配置组。组成员服务对此做了更详细的说明。
9.3 Data Manipulation Statements
DML语句
由于对于任何特定的数据集都没有主节点(master)的概念,所以组中的每个节点都允许在任意时间执行事务,甚至可以执行更改状态的事务(RW事务)。
任何节点都可以以一种无需由因及果的方式执行事务(译注:事务发起节点执行事务是一句一句执行按逻辑执行下去,非事务发起节点可以跳过这些逻辑,直接修改行数据为结果数据)。但是,在提交的时候,必须和组中其他节点进行协调以便对该事务命运的决定达成一致。协调提供两种目的:(1)检查事务是否应该提交;(2)在组内传播更改,以便让其他节点也应用该事务。
由于事务是通过一个原子性的广播发送的,所以组内所有节点要么全部接收到该事务,要么全都未接收到该事务。如果它们都接收到了,它们接收到的事务所在顺序位置是完全一致的。冲突检测是通过检查和比较事务的写集来进行的,所以它们是在行级别上进行探测。探测到了冲突的解决方案是先提交者获胜规则。如果在不同节点上并发执行 t1 和 t2 事务,它们都修改同一行,如果t2先提交,则t2获胜,t1终止。换句话说,此时的t1是在尝试修改t2的过期数据。
注意
如果两个事务经常冲突,更好的方法是在同一个节点上开始这两个事务。这样,它们有机会在本地锁管理器上同步,而不是在稍后的复制协议中终止。
9.4 Data Definition Statements
DDL语句
在执行DDL语句时需要小心。考虑到MySQL不支持原子或事务的DDL,因此不能乐观地执行DDL语句以及回滚需求。因此,由于DDL缺乏原子性的能力,它并不能直接适应与组复制基于的乐观复制范式。
所以,在复制DDL语句时需要多加小心。schema的更改以及对对象中包含的数据更改需要在同一个节点上进行处理,防止schema的操作还没有完成,却复制到了其他节点上。如果不这么做,可能会导致数据不一致性。
注意
如果部署的是单主模型的组复制,则没有此问题,因为所有的更改都只在主节点上执行。
警告
MySQL的DDL语句不具备原子性,也没有DDL类型的事务。组不会在执行和提交DDL操作之前做一致性协商。因此,你必须将对同一对象操作的DDL语句和DML语句路由到同一个节点上。
9.5 Distributed Recovery
分布式恢复
本节描述正在加组的成员赶上组内已有节点数据的过程,这个过程称为分布式恢复阶段。
9.5.1 Distributed Recovery Basics
分布式恢复基础
组复制的分布式恢复过程可以总结为:新节点从组中在线节点获取它所缺失的那部分数据,同时监听组中正在发生的事件。在恢复过程中,新节点会监听组中发生的事件,也会监听正在发生的事务。这是一句高层次的总结(译注:浓缩就是精华,这个总结浓缩的太精华了)。下面几小节将提供关于这两个阶段详细的说明。
Phase 1
在第一阶段,新节点会从组中选择一个在线节点作为donor来获取它缺失的数据。donor负责传输新节点开始加组那一刻之前的所有数据需求(译注:这个加组指的是新节点请求加入组的那一刻,而不是成功加入组的那一刻)。这是通过在donor和新节点之间建立一个标准的异步复制通道来实现的,二进制日志日志会通过这个通道一直向上流动,直到成员视图更新时,这意味着新节点成功成为组中成员。当新节点从donor处接收到二进制日志时,它会去应用它们。
此外,在二进制日志传输进行时,新节点也会缓存组内发生的每一个事务。即,新节点正从donor处获取缺失数据的同时,也会监听从它建立异步复制通道后组中发生的新事务。当第一阶段完成后,和donor建立的复制通道就会关闭,之后进入第二阶段:追赶。
Phase 2
在这个阶段,新节点继续执行缓存中的事务,当队列中待执行的事务数量最终达到0时,该成员将标记为ONLINE。
高弹性(可容错)
在新节点从donor获取二进制日志的时候,恢复过程可以允许donor出现故障。这种情况下,当donor在第一阶段故障时,新节点将自动重新选择一个新的donor,并从新donor那里恢复到旧donor故障的那一刻。这意味着,新节点会自动地关闭和旧donor的通道,并和新donor建立通道。
9.5.2 Recovering From a Point-in-time
从一个特定时间点处恢复
为了让新节点和donor的某个特定时间点保持同步,新节点和donor使用GTID机制。但这还不够,因为这仅提供了一种让新节点意识到它所缺失的是哪些事务的方法。它没有为新节点必须追赶到哪个特定时间点做任何标记,同时也没有传输认证(certification)有关的信息。这正是二进制日志视图标记登台的地方。它们标记二进制日志流中的视图更改,还包含一些额外的元数据信息,以及给新节点提供关于它缺失的认证相关数据。
9.5.2.1 View and View Changes
视图和视图更改
理解视图和视图更改是什么对解释视图更改标记很重要。
视图对应的是当前配置组内在线成员的列表。换句话说,在任意特定的时间点,在线且一切正常的节点。
视图更改发生在对组配置进行修改时,例如有节点要加组或离组。任何一次组成员变更都会导致一次独立的视图更改,在同一逻辑时间点传输给组内所有成员。
视图标识符惟一地标识一个视图。在视图更改时会更改它。
在组通信层,视图更改以及它们关联的视图id是加入组之前和之后的区分边界。这个概念是通过一个新的二进制事件实现的:"视图更改事件"。因此视图id也作为组成员配置变更之前、之后传输的事务的标记。
视图标识符由两部分组成:第一部分是创建组时随机生成的,在组停止(关闭)之前一直保持不变;第二部分是一个单调递增的整数,每次视图发生更改都递增一次。
使用这种混合视图id的原因是,可以明确地标记当成员加入或离开时发生的组成员配置更改,也能标记所有成员离开组后没有任何信息保留在视图中。实际上,单纯使用单调递增的整数作为标识符会导致在组重启后重用视图ID,显然这会破坏恢复过程所依赖的二进制日志标记的唯一性。总而言之,第一部分标识这个组是从什么时候启动的,第二部分标识组在什么时间点发生了更改。
9.5.3 View Changes
视图更改
本节解释如何控制视图更改标识符合并到二进制日志事件并写入到日志的过程。有以下几个步骤:
1.Begin: 稳定的组
所有节点都是在线的,并且处理组内事务。某些节点可能会因为复制的原因而稍由落后,但最终它们会达到一致。组在这里充当一个分布式的、复制的数据库。
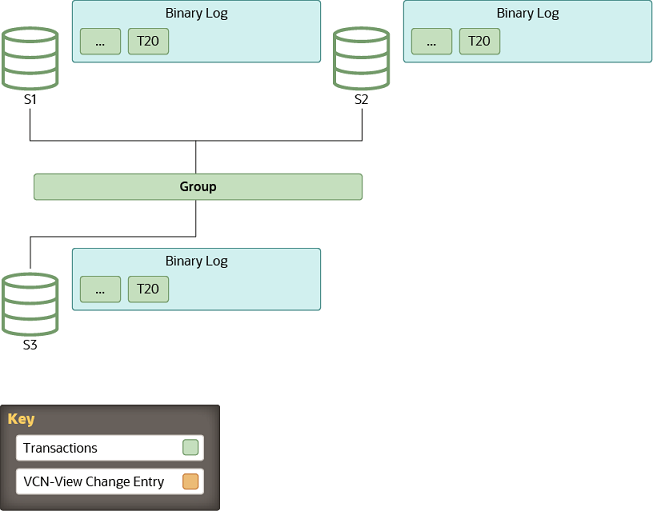
2.View Change: 新成员要加入
每当一个新成员要加入组时,都会更改视图,每个在线节点都会将视图更改的日志事件排队以等待执行。之所以要排队,是因为在更改视图之前可能已经有一些事务在排队等待应用,这些事务属于旧的视图。将视图更改事件进行排队,保证了这种情况下能正确对其标记。
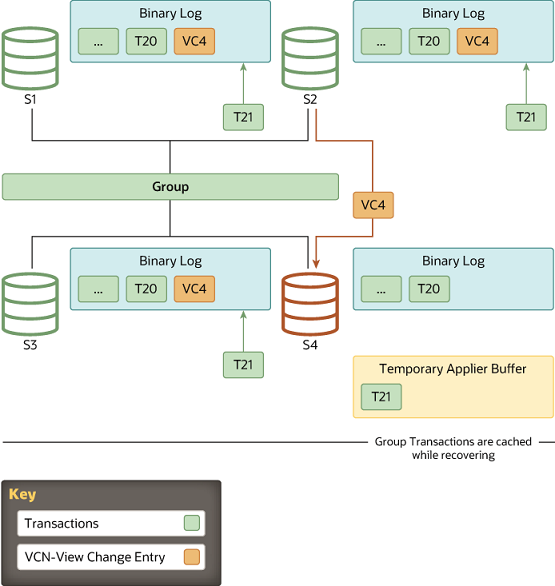
同时,待加入成员会从组内在线成员列表中选择一个donor。上面的右图中,这个新成员对应第4个视图(译注:组创建时视图id的第二部分为1,第二个成员加入后第二部分为2,依此类推,这是第四个成员,所以第二部分为4),目前在线的(3个)成员会向二进制日志中写入视图更改事件。
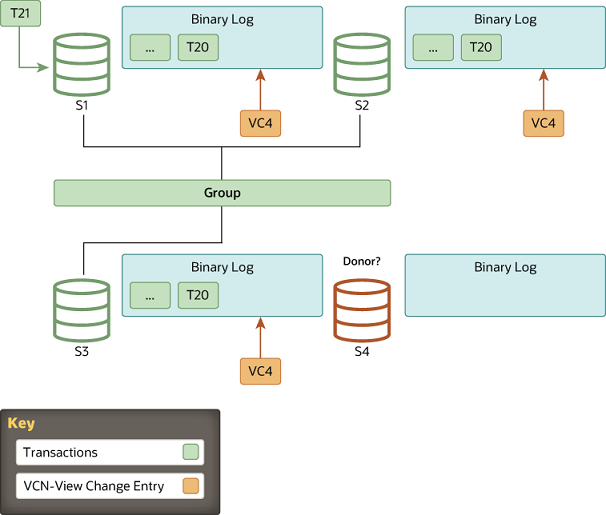
3.State Transfer: 追赶
当待加组成员选择好donor之后,它们之间会建立新的异步复制连接,并且开始状态传输(第一阶段)。该成员和donor的交互会一直持续到该成员的applier线程开始处理视图更改日志事件,因为这个事件对应的是该成员请求加入组的那一刻。换句话说,待加组成员会一直从donor上复制二进制日志,直到发现了此次加组时的视图更改标识符。
由于视图标识符会在同一逻辑时间点传输到组中所有成员,待加组成员知道在哪个视图标识符处停止复制二进制日志。这避免了复杂的GTID集计算,因为视图ID明确标记了哪部分数据属于哪个视图。
当待加组成员从donor上复制时,它也会缓存新进入组中的事务。最终,它停止从donor处复制,并转而去应用那些已缓存的事务。
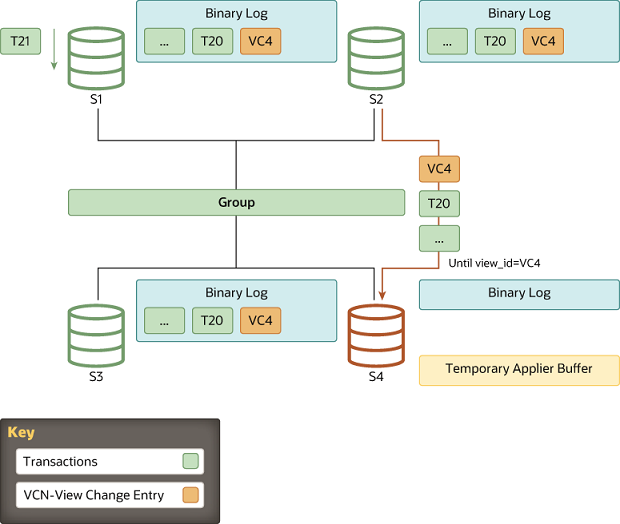
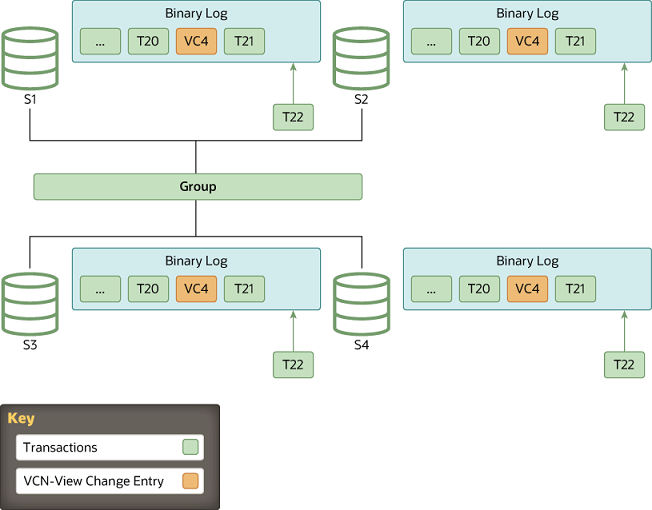
4.Finish: 追赶完成
当待加组成员根据视图标识符识别了一个视图更改的日志事件后,它和donor之间的连接就会断开,然后它开始应用已缓存的事务。需要理解的一个关键之处在于这是恢复过程的最终步骤。尽管视图更改事件在二进制日志中充当了一个标记,分隔了视图更改,但它还扮演另一个角色。它传达了在它加组时其他所有节点感知到的认证信息(certification information),也就是最后一个节点(即这个新节点)的视图也更改了。如果没有它,待加组成员就不具备验证(探测冲突)后续事务的必须信息。
追赶的持续时间(第二阶段)是不确定的,因为它依赖于负荷程度以及组内事务传输的速率。追赶的过程是完全在线的,待加组成员不会阻塞组内其他任何节点。因此,当恢复过程前进到第二阶段后,待加组成员落后的事务数量因这个原因而变化,它根据负荷程度而增加或减少。
当待加组成员的排队事务数量达到 0 后,它所存储的数据和组内其他节点就保持了一致,这时它在组内的状态会改变为ONLINE。
9.5.4 Usage Advice and Limitations of Distributed Recovery
分布式恢复的使用建议和局限性
分布式恢复有一些局限性。它基于传统的异步复制,因此如果它在复制之前完全没有数据或者备份的数据集很老,那么恢复的过程会比较慢。这意味着如果在第一阶段要传输的数据非常大,会需要一长段时间来恢复。因此,在新成员加入组之前,建议从组中在线节点备份最新的数据并恢复到该新成员上,这会将第一阶段的持续时间缩短,且会降低对donor的影响,因为它需要保存和传输更少的二进制日志。
9.6 Observability
可观察性
在组复制中内置了很多自动化功能。尽管如此,某些时候你可能想要了解幕后所发生的事情。这就是组复制的仪表(译注:即状态显示)和Performance Schema重要的原因。通过performance_schema表可以查询到系统的整个状态(包括视图、冲突统计和各种服务的状态)。
复制协议的分布式特性,以及所有节点对决定达成一致,事务和元数据因此而保持同步这一事实,使得组的状态检查变得更简单。例如,你可以连接到组中的某节点上,通过select语句查询performance_schema中关于组复制的表,可以获取本地和全局信息。更多信息见监控组复制。
9.7 Group Replication Performance
组复制的性能
本节解释如果使用可配置选项以便让你的组复制达到最佳性能。
9.7.1 Fine Tuning the Group Communication Thread
微调组通信线程
当组复制插件加载后,组通信线程(GCT)工作在一个循环内。GCT从组中和组复制插件中接收消息,负责处理仲裁、故障探测相关任务,以及向外发送存活消息、处理MySQL Server和组复制插件之间流入/流出的事务。GCT排队等待流入的消息,当没有消息时,GCT会等待。将这个等待时长配置久一点(会做一个主动等待, active wait),可以让GCT晚一点进入睡眠态,有些情况下这样配置是有益的。这是因为切换到sleep态时,操作系统会将CPU从GCT切换出来,这会导致上下文切换。
为了强制GCT做active wait,配置group_replication_poll_spin_loops选项,这使得在实际轮询队列中的下一条消息之前,GCT循环不会做任何和已配置的循环数量相关的工作。(译注:这个变量的作用是:GCT在等待下一条消息之前,等待消息引擎互斥锁释放的时长,设置长一点时间,可以多等一段时间,收到下一条消息的中间不用临时进入睡眠态)
例如:
mysql> SET GLOBAL group_replication_poll_spin_loops= 10000;
9.7.2 Message Compression
压缩消息
当网络带宽是一个瓶颈时,压缩消息可以提升组通信层的30%-40%的吞吐量。对于负载较重的大型复制组,这非常有用。
下表描述了LZ4对不同二进制日志格式的压缩率。
| Workload | Ratio for ROW | Ratio for STMT |
|---|---|---|
| mysqlslapd | 4,5 | 4,1 |
| sysbench | 3,4 | 2,9 |
由于组内N个节点为了内部通信需要和组内其他所有节点都建立TCP端对端的连接,这使得同一份数据要向外发送N次(译注:实际是N-1次,需要减去本节点自身)。更重要的是,二进制日志的压缩比较高(见上表)。这使得在包含大事务高负载的环境下,消息压缩成为一个引人瞩目的功能。
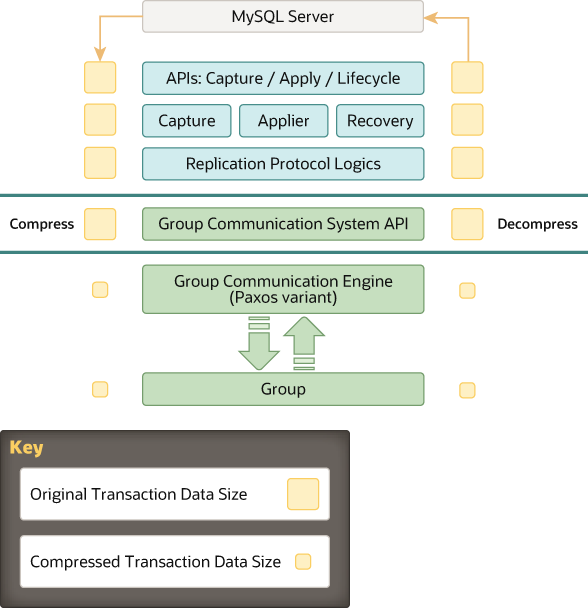
消息压缩的位置在将数据交给组通信线程之前的组通信引擎层,因此它发生在mysql用户会话线程的上下文中。事务在被发送到组之前被压缩,在被接收时被解压缩。 压缩是有条件的,取决于配置的阈值。 默认情况下压缩已启用。
此外,不要求组内所有节点都开启压缩功能才能一起工作。收到消息后,该成员会检查消息是否已被压缩,如果被压缩,则在消息传输到上层之前先解压缩。
使用的压缩算法是LZ4。默认启用压缩的阈值为1000000字节(译注:即1MB左右)。这个阈值可以设置为比默认值更大,这样只有超出阈值的大事务才会进行压缩。下面是设置压缩阈值的示例:
STOP GROUP_REPLICATION;
SET GLOBAL group_replication_compression_threshold= 2097152;
START GROUP_REPLICATION;
上面设置了压缩阈值为2MB。如果事务生成的复制消息大于2MB,例如这个事务对应生成的二进制日志大于2MB,将会压缩这段日志。如果要禁用压缩功能,将其设置为0。
9.7.3 Flow Control
流程控制
组复制只有在组内所有节点都收到了事务,且大多数成员对该事务所在顺序及其他一些相关内容都达成一致时才会进行事务提交。
如果写入组的总数量都在组中任何成员的写入能力范围之内,则此方法运行良好。如果某节点或某些节点的写吞吐量较其他节点更差,则这些节点可能会落后。
当组中有一些成员落后了,可能会带来一些问题,典型的是读取这些落后节点上的数据都是比较旧的。根据节点为什么落后的原因,组内其他成员可能会保存更多或更少的上下文,以便满足落后成员潜在的数据传输请求。
好在复制协议中有一种机制,可以避免在应用事务时,快速成员和慢速成员之间拉开的距离太大。这就是所谓的流程控制(flow control) 机制。该机制试图实现以下几个目标:
- 保证成员足够接近,使得成员之间的缓冲和非同步只是一个小问题;
- 快速适应不断变化的情况,例如不同的工作量、更多的写节点;
- 给每个成员分配公平的可用写容量;(译注:其实就是取某种类型的平均写能力值)
- 不要因为避免浪费资源而过多地减少吞吐量。
考虑到组复制的设计,可以考虑两个工作队列来决定是否节流:
- (1)认证队列(certification);
- (2)二进制日志上的应用队列(applier)。
当这两个队列中的任何一个超出队列最大值(阈值)时,将会触发节流机制。只需配置:
- (1)是否要对ceritier或applier或两者做flow control;
- (2)每个队列的阈值是多少。
flow control依赖于两个基本的机制:
- 监控组内每个成员收集到的有关于吞吐量和队列大小的一些统计数据,以便对每个成员可以承受的最大写入压力做有根据的猜测;
- 每当有成员的写入量试图超出可用容量公平份额,就对其节流限制。
9.7.3.1 Probes and Statistics
探针和统计数据
flow control依赖的监控机制是通过在组中每个成员上部署一系列的探针来实现的,这些探针收集它们的工作队列和吞吐量信息,然后将这些信息每隔一段时间就传播给组内其他成员进行共享。
这些探针分散在整个插件栈中,并且允许对探测指标进行设置,例如:
- certifier队列的大小;
- applier队列的大小;
- 已被认证(certified)的事务总数量;
- 本节点上已应用的远程事务总数量;
- 本地事务总数量。
当某成员接收到其他成员发送的统计信息时,它会计算额外的指标:自上次监控期以来有多少个事务被验证、被应用以及在本地执行了。
监控数据会每隔一段时间就和其他成员共享。监控时间间隔必须足够长,以便允许其他节点能够决定当前的写请求(译注:即对写请求达成一致),但也要足够短,使其对组的带宽影响最小。这些信息每秒钟都会共享一次,这段时间足以解决这两个问题。
9.7.3.2 Group Replication Throttling
组复制限流
基于收集到的组中所有成员的指标,会启动一个节流机制,用来决定是否限制某成员执行/提交新事务的速率。
因此,从其他所有成员处获取的指标是计算每个成员能力的基础:如果某成员的队列中事务很多(certification或applier队列),则应当让该成员执行新事务的能力接近上一周期认证和应用的能力。
组中能力最低的成员决定了组真正的处理能力,而本地事务数量决定了正有多少成员在写入它。因此,这些正在写入的成员之间应该共享这个最低处理的能力。
这意味着每个成员都有一个建立在可用容量基础上的写配额,换句话说,它可以在下一周期安全地写这些事务。如果certifier或applier队列大小超出了阈值,节流机制将强制设置写配额。
上一周期中延迟的事务数量会降低本期配额的大小,在此基础上再减少10%,以允许触发问题的度列可以减小它的大小。为了避免队列大小超出阈值时吞吐量大幅增加,此后的吞吐量只允许每周期增长10%。
当前节流机制不会惩罚低于配额的事务,但会延迟完成那些超过监控期限的事务。 因此,如果发出的写请求的配额非常小,则某些事务的延迟可能接近整个监控周期。
( 译注:
关于监控和节流限制,大概如下:
- 监控有周期,每个周期都会向外共享统计信息。收到统计信息后,会计算一些指标。
- 基于这些指标,会有一个节流机制决定执行事务的速率和能力。
- 为了避免拖后腿的问题,节点之间会共享最慢的写能力作为这个周期的写配额。
- 如果配额很小,执行事务的能力很低,就会积压事务,这些积压的事务会跨过监控周期进入下一个监控周期。
- 积压到下一个周期的事务越多,说明在下一个周期应该允许接收的新事务数量越少,否则会越压越多。
)