Random Forest - lorenzodelmedico/AI-knowledge GitHub Wiki
Supervised machine learning algorithm (classification & regression)
Family of ensemble methods.
Ensemble method are algorithm that combine multiple models to improve the predictive performance of a model. Bagging, Boosting and Stacking are the 3 categories that make ensemble learning.
Random forest rely on bagging (bootstrap and aggregating)
Bagging is a technique that trains multiple models on different random samples of the training data and then combines their predictions. For classification majority voting is used, while averaging is in use for regression. This helps to reduce the variance of the model and increase its stability.
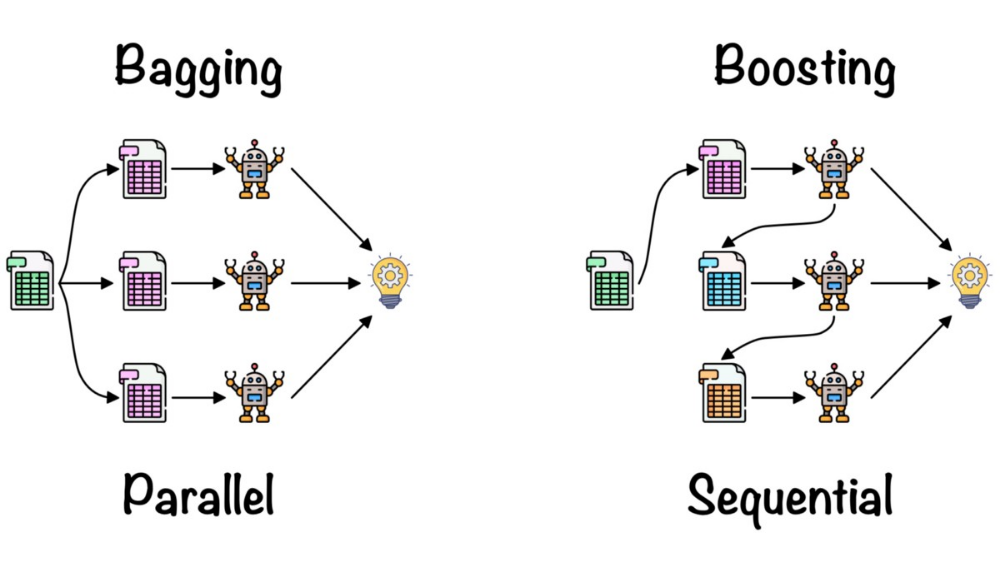
How it works:
First in Random forest a number of random records are taken from the data set. For each sample a decision tree is built, and will generate an output. Then depending on the task it'll use majority voting or averaging.
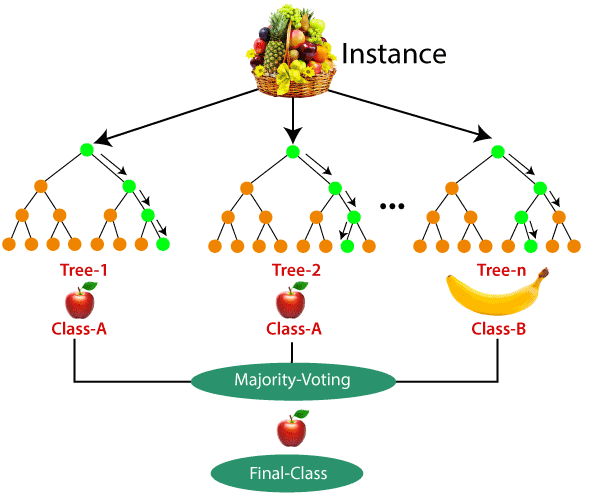
Additional information:
Random forest also allows feature selection as it computes features importance. If one's want to find the optimal numbers of trees, OOB is a good tool for it. To analyze the uncertainty of the prediction standard deviation is recommended.
Target variable
Classification is used for discrete while Regression is used for continuous target.
Source:
https://www.youtube.com/watch?v=7C_YpudYtw8
https://towardsai.net/p/programming/decision-trees-explained-with-a-practical-example-fe47872d3b53