019. 조인 알고리즘과 성능 - llighter/database GitHub Wiki
DSL in Clojure Slide Share - Misha Kozik
옵티마이저가 선택 가능합 조인 알고리즘은 크게 3가지 이다.
- Nested Loops
- Hash
- Sort Merge
- 중요성 : 1 > 2 > 3
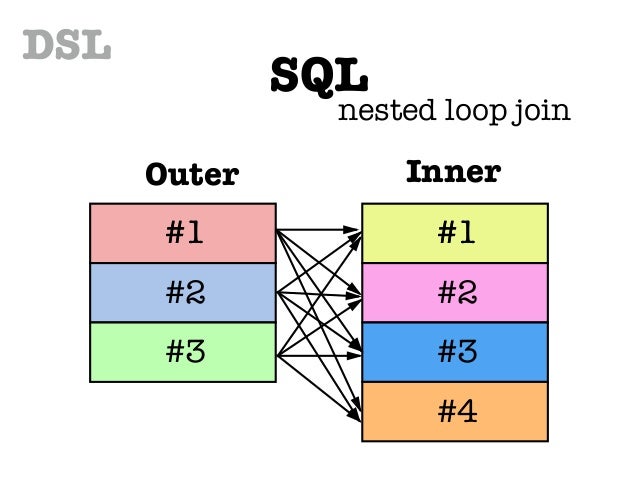
1. Nested Loops
- Nested Loops의 작동
- 중첩 반복을 사용하는 알고리즘
- 조인 성능에서 가장 중요한 알고리즘
- 구동 테이블(Outer Table)이 작을 수록 Nested Loops의 성능이 좋아진다.(검색 조건으로 압축된 구동 테이블 수가 작을 때)
- 이중 반복의 외측과 내측의 반복 처리가 비대칭이다.
Nested Loop의 특징
- Table_Outer, Table_Inner의 조인 대상 레코드를 R(Outer), R(Inner) 라고 하면 접근되는 레코드 수는 R(A) X R(B) 가 된다. Nested Loops의 실행 시간은 이러한 레코드 수에 비례한다.
Nested Loop에도 몇가지 버전이 있는데 스캔 레크드 수를 더 줄일 수 있다. ex.
EXISTS- 반결합(Semi-Join),NOT EXISTS- 반결합(Anti-Join)
- 한 번의 단계에서 처리하는 레코드 수가 적으므로 Hash 또는 Sort Merge에 비해 메모리 소비가 적다.
- 모든 DBMS에서 지원한다.
- 구동 테이블의 중요성
'구동 테이블을 작게' -> 내부 테이블의 결합 키 필드에 인덱스가 존재
Nested Loops의 내부 테이블에 인덱스가 있는 경우 그림 추가
- 이상적인 경우 구동 테이블의 레코드 한 개에 내부 테이블의 레코드 한 개가 대응하고, 해당 레코드를 내부 테이블의 인덱스를 사용해 찾을 수 있는 경우(반복없이) 접근하는 레코드 수는 R(Outer) X 2 가 된다.
- 만약 내부 테이블의 결합 키 인덱스가 사용되지 않으면 구동 테이블이 작아봤자 아무런 장점이 없다.
내부 테이블의 반복을 얼마나 생략할 수 있을지가 포인트 그림 추가
- '구동 테이블을 작게' -> '내부 테이블을 크게'
- '구동 테이블이 작은 Nested Loops' + '내부 테이블의 결합 키에 인덱스' = SQL튜닝의 기본 중에 기본
- 즉, 물리 ER 모델과 인덱스를 설정할 때, 어떤 테이블을 내부 테이블로 하고, 어떤 결합 키에 인덱스를 적성해야 하는지를 초기 단계부터 고민해야 한다.
- Nested Loops의 단점
- '구동 테이블이 작은 Nested Loops' + '내부 테이블의 결합 키에 인덱스'의 조합이더라도 성능이 충분히 나오지 않을 수 있다.
- 보통 이런 경우 결합 키로 내부 테이블에 접근할 때 히트되는 레코드들이 너무 많기 떄문이다.
- ex. 점포 테이블과 점포에서 받은 주문 테이블
내부 테이블의 선택률이 높으면 Nested Loops의 성닝이 악화 그림 추가
- 위의 문제를 해결하는 방법은 두 가지
- 구동 테이블로 큰 테이블을 선택하는 역설적인 방법
- 이렇게 하면 내부 테이블에 대한 점포 테이블의 접근이 기본 키(점포ID)로 수행되므로, 항상 하나의 레코드로 접근하는 것이 보장
- 점포에 따른 성능 비균등 문제를 해결해서, 극단적으로 성능이 저하된느 것을 막을 수 있다.
- 두 번째 방법은 해시
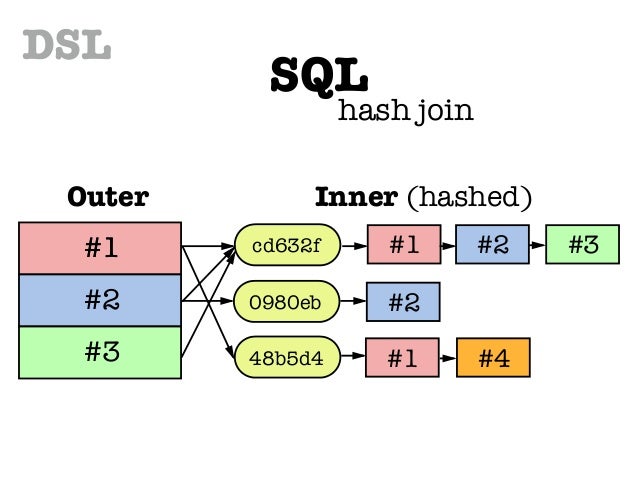
2. Hash
- Hash의 작동
- 해시 조인은 일단 작은 테이블을 스캔하고, 결합 키에 해시 함수를 적용해서 해시값으로 변환한다.
- 이어서 다른 테이블(큰 테이블)을 스캔하고, 결합 키가 해시값에 존재하는지를 확인하는 방법으로 조인을 수행한다.
- 작은 테이블에서 해시 테이블을 만드는 이유는 DBMS의 워킹 메모리에 저장되므로 조금이라도 작은 것이 효율적이기 때문이다.
- Hash의 특징
- 결합 테이블로부터 해시 테이블을 만들어서 활용하므로, Nested Loops에 비해 메모리를 크게 소모한다.
- 메모리가 부족하면 저장소를 사용하므로 지연이 발생한다.(TEMP 탈락)
- 출력되는 해시값은 입력값의 순서를 알지 못하므로, 등치 결합에만 사용할 수 있다.
- Hash가 유용한 경우
- Nested Loops에서 적절한 구동 테이블(상대적으로 충분히 작은 테이블)이 존재하지 않는 경우
- 앞서 'Nested Loops의 단점'에서 본 것처럼 구동 테이블로 사용할만한 작은 테이블이 있지만, 내부 테이블에서 히트되는 레코드 수가 너무 많은 경우
- Nested Loops의 내부 테이블에 인덱스가 존재하지 않는(똔느 여러 가지 사정에 의해 인덱스를 추가할 수 없는) 경우
한마디로, Nested Loops가 효율적으로 작동하지 않는 경우의 차선책이 Hash이다.
- Hash의 트레이드오프 두가지
- 초기에 해시 테이블을 만들어야 하므로, Nested Loops에 비해 소비하는 메모리 양이 많다.
- 동시 실행성이 높은 OLTP 처리를 할 때 Hash가 사용되면, DBMS가 사용할 수 있는 메모리가 부족해져 저장소가 사용된다.
- 따라서 OLTP 처리를 할 때 Hash를 사용하면 안된다.
- 반대로 동시 처리가 적은 야간 배치 또는 BI/DWH와 같은 시스템에 한해 사용하는 것이 Hash를 사용하는 기본 전략이다.
- Hash 결합은 반드시 양쪽 테이블의 레코드를 전부 읽어야 하므로, 테이블 풀 스캔이 사용되는 경우가 많다.
- 따라서 테이블의 규모가 굉장히 크다면, 이런 풀 스캔에 걸리는 시간도 고려해야 한다.
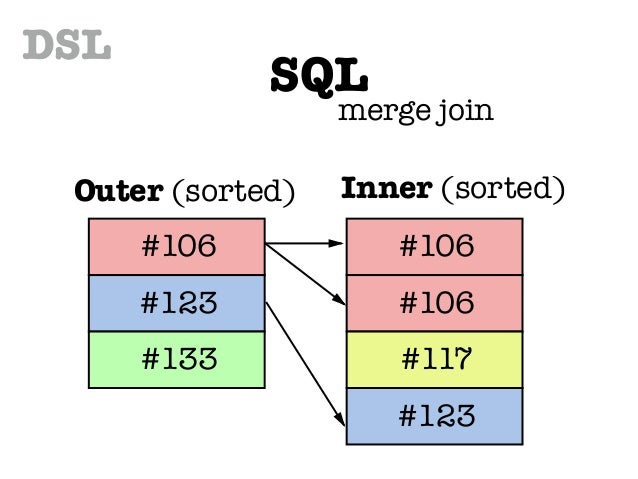
3. Sort Merge
- Sort Merge의 작동
Sort Merge === Merge, Merge Join
Sort Merge는 결합 대상 테이블들을 각각 결합 키로 정렬하고, 일치하는 결합 키를 찾으면 결합한다.
- Sort Merge의 특징
-
대상 테이블을 모두 정렬해야 하므로 Nested Loops보다 많은 메모리를 소비한다. Hash와 비교하면 규모에 따라 다르지만, Hash는 한 쪽 테이블에 대해서만 해시 테이블을 만드므로 Hash보다 많은 메모리를 사용하기도 한다. 메모리 부족으로 TEMP 탈락이 발생하면 I/O 비용이 늘어나고 지연지 발생할 위험이 있다.(Hash도 마찬가지다.)
-
Hash와 다르게 동치 결합뿐만 아니라 부등호를 사용한 조인에도 사용할 수 있다. 하지만 부정조건(<>) 조인에서는 사용할 수 없다.
-
원리적으론느 테이블이 결합 키로 정렬되어 있다면 정렬을 생략할 수 있다. 다만 이는 SQl에서 테이블에 있는 레코드의 물리적인 위치를 알고 있을 때이다. 따라서 이러한 생략은 구현 의존적이다.
-
테이블을 정렬하므로 한쪽 테이블을 모두 스캔한 시점에 결합을 완료할 수 있다.
- Sort Merge가 유효한 경우
테이블 정렬으 ㄹ생략할 수 있는 (상당히 예외적인) 경우에는 고려해볼만 하지만, 그 이외의 경우는 Nested Loops와 Hash를 우선적으로 고려한다.
4. 의도하지 않은 크로스 조인
삼각 결합 그림 추가
- Nested Loops가 선택되는 경우
- 크로스 조인이 선택되는 경우
큰 트랜잭션과 작은 마스터 그림 추가
- 의도하지 않은 크로스 조인을 회피하는 방법
불필요한 조인 조건을 추가해서 크로스 결합을 회피 그림 추가