数据结构 - liuzhen153/play-algorithm-python GitHub Wiki
什么是数据结构
该章大量参考并使用『我的第一本算法书』中的内容,如果感兴趣的同学可以去购买该书或该书电子版查阅。
计算机存储数据时,犹如成行成列的『箱子』,每个『箱子』存储一个数据,决定了数据存储的顺序和位置关系的便是【数据结构】。
如何选择数据结构-电话薄的设计
现在大家都用手机,存储和查询电话号码十分方便。一个电话薄看似简单,这里面也能映射出选择合适的数据结构的重要性。
方式一:顺次添加
当我们有一个纸质电话薄,在得到一个新号码时,只能从上往下记录,这种方式对写一条新数据来说十分方便,例如:
| name | tel |
|---|---|
| Jack | 123xxx |
| Emma | 456xxx |
| Colin | 789xxx |
| Leon | 132xxx |
| ChaoChao | 132xxx |
| ... | ... |
假如我们要给『Tommy』打电话,在上面的排序中,我们不知道Tommy具体在哪,只能从上往下翻,胆子野一些说不定『随机查找』更快些。但是无论怎样,当这种存储很大时,我们找起电话来就不容易了。
方式二:按姓名首字母排序
无论中文名还是英文名,我们都可以找到其首字母。如果以联系人姓名首字母排序,数据都会是以字典顺序排列的,他们就是有『结构』的,例如:
| name | tel |
|---|---|
| ChaoChao | 132xxx |
| Colin | 789xxx |
| Emma | 456xxx |
| Jack | 123xxx |
| Leon | 132xxx |
| ... | ... |
这时,如果我们要给『Tommy』打电话,就可以很轻松确认Tommy的大致位置。
但是,如果我们要添加一条数据呢?比如我们新认识一个朋友『Fred』,要将他的手机号写到电话薄里。由于我们的电话薄是按照姓名首字母排序的,所以需要将其写在Emma和Jack的中间,但是上面已经没有空位可以写,所以需要将Jack的『内容写到下一行,并清空本行』,相对应的,后面所有的数据都要执行『将本行内容写到下一行,并清空本行』的操作。如果一次操作耗时10s,当我们的电话薄很大时,添加一个人进来可能要花费好几个小时。
方式三:将顺序添加和按首字母排序结合
通过上面的研究,我们发现:
- 顺序添加方式的新增速度快、成本小
- 按首字母排序方式的查询速度快
如果我们将电话薄分成多个部分呢?我们将每一个部分记为一个表,每一个表对应一个首字母:表A、表B、 表C... 例如:
表C
| name | tel |
|---|---|
| ChaoChao | 132xxx |
| Colin | 789xxx |
| ... | ... |
表E
| name | tel |
|---|---|
| Emma | 456xxx |
| Elin | 256xxx |
| Elfa | 356xxx |
| ... | ... |
表J
| name | tel |
|---|---|
| Jack | 123xxx |
| Jonny | 632xxx |
| ... | ... |
这样一来,我们每次添加新数据就可以找到对应的表往后面顺序写就行了,而查询时也可以快速定位到大概位置。
虽说各个表中的存储还是无规律的,每次都要从表头开始往下查找,但是也要比从整个电话薄中查找要快得多了!
几种基本的数据结构
图引自『我的第一本算法书』第一章
1.链表
概念图
如下图,Blue、Yellow、Red三个字符串存储于链表中,每个数据都有一个『指针』,它指向下一个数据的内存地址(Red是最后一个数据,其指针不指向任何位置)。
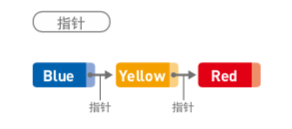
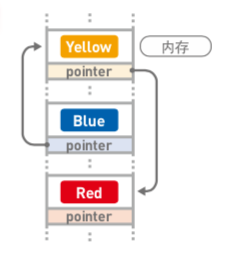
在内存中存储
由上述内容可知,在链表中,数据无需存储在连续空间内,一般都是分散存储的。
访问方式 - 顺序访问
因为数据是分散存储的,所以想要访问一个数据,只能从第一个数据开始,顺着指针往下找。比如,想查找Red,查找顺序如下:
Blue -> Yellow -> Red(Done)
查找数据的耗时和链表长度n有关,时间复杂度为:
O(n)
添加数据
如果想添加数据,只需改变添加位置前后的指针指向即可,比如『在Blue和Yellow直接添加Green』:
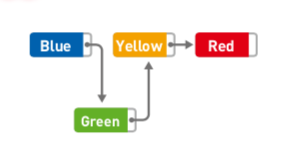
添加数据的耗时和链表长度n无关,如果已经到达需要添加数据的位置,则时间复杂度为:
O(1)
删除数据
删除数据也一样,我们只需要改变指针的指向即可,比如『删除Yellow』:
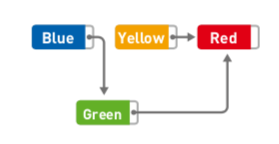
此时,Yellow本身还存在,不过没关系,它已经无法被访问,今后需要用到其所在存储空间时,直接覆盖掉即可。
和『添加数据』一样,删除数据的时间复杂度为:
O(1)
特点
由上述内容我们可以看出,链表有以下特点:
- 数据呈线性排列,分散存储
- 访问比较耗时 O(n)
- 数据的添加和删除都比较方便 O(1)
2.数组
概念图
数组也是线性排列的,它的结构和最开始讲的『按姓名首字母排序的电话薄』类似。
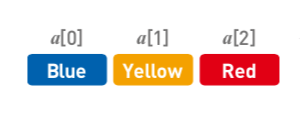
在内存中存储
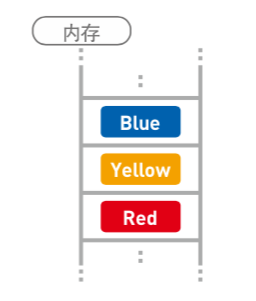
数组的数据按顺序存放在连续空间内:
访问方式 - 随机访问
因为数据存放在连续空间内,所以我们可以用数组下标计算出每个数据的内存位置,借此直接访问目标数据,这叫做『随机访问』:
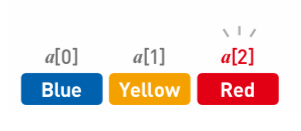
我们可以通过数组下标查找目标数据,查找数据的耗时和数组长度n无关,时间复杂度恒为:
O(n)
添加数据
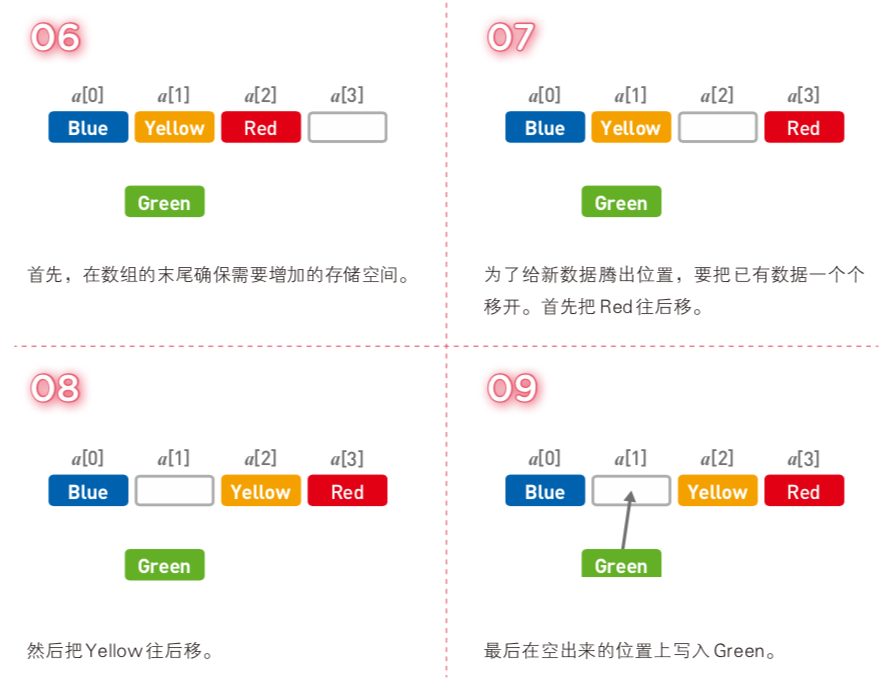
如果想添加数据,需要经过以下步骤:
① 在数组末位增加存储空间
② 从新数据要存放的位置,把后面已有数据一个个后移
③ 插入新数据
例如,我们尝试将Green添加到第二个位置上:
添加数据的耗时和链表长度n有关,如果在数组头部添加数据,则时间复杂度为:
O(n)
删除数据
删除数据是将『添加数据』反过来操作一遍,需要经过以下步骤:
① 删除目标数据
② 把目标数据后面已有数据一个个往前移
③ 删除末尾多余空间
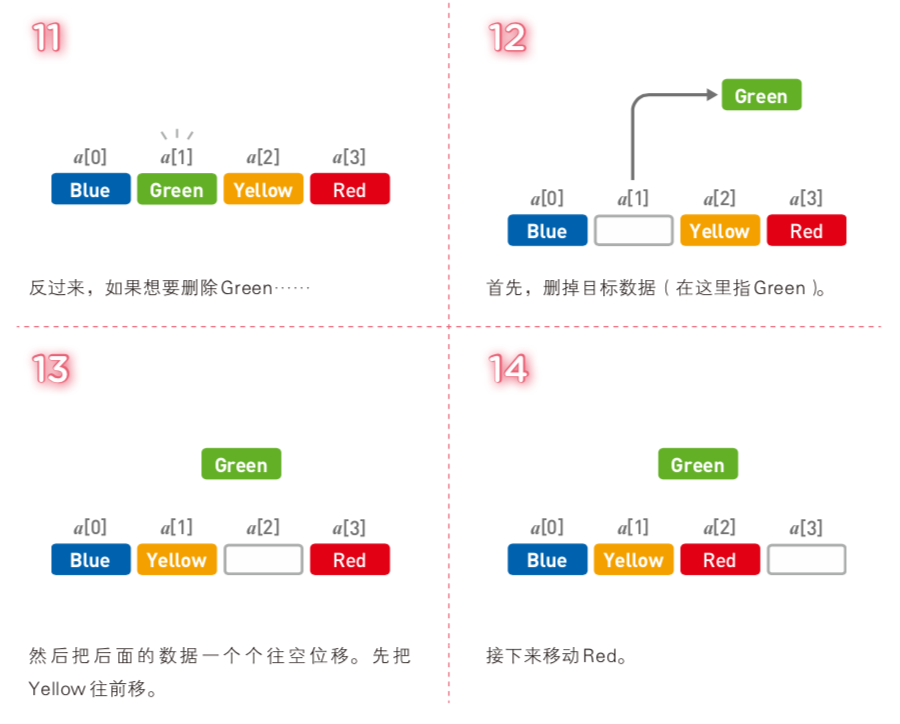
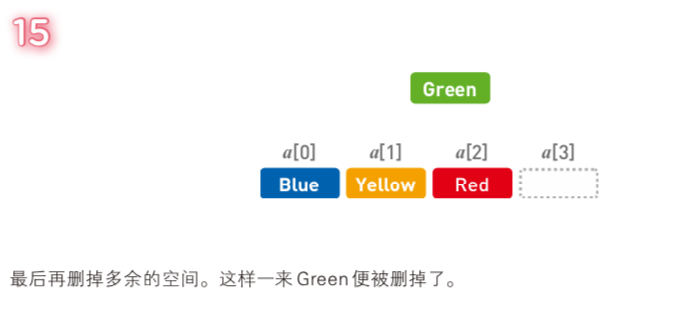
和『添加数据』一样,删除数据的时间复杂度为:
O(n)
特点
由上述内容我们可以看出,数组有以下特点:
- 数据呈线性排列,连续存储
- 访问快速 O(1)
- 数据的添加和删除比较复杂 O(n)
和链表对比
通过对比,我们可以根据哪种操作频繁来决定使用哪种数据结构。
| 访问 | 添加 | 删除 |
|---|---|---|
| 链表 | 慢 | 快 |
| 数组 | 快 | 慢 |
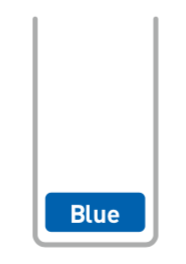
3.栈
概念图
栈也是线性排列的。栈就像一摞书,新书都会被堆在最上面,取书时也只能从最上面开始取。
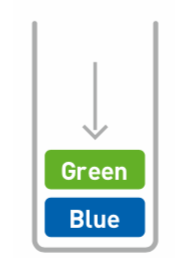
添加数据 - 入栈(push)
往栈中添加数据的操作叫做入栈(push)
添加Green:
添加Red:
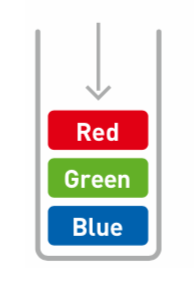
取出数据 - 出栈(pop)
从栈中取出数据的操作叫做出栈(pop)
例,我们要取出Green:
① 先取出Red:
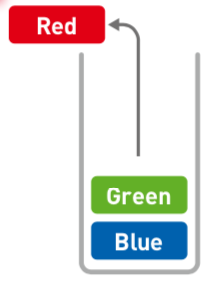
② 这时Green在顶部,才能通过出栈操作取出:
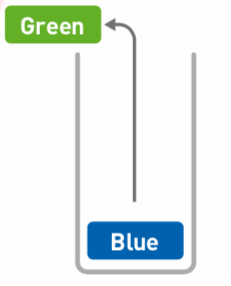
特点
由上述内容我们可以看出,栈有以下特点:
- 『后进先出』,Last In First Out (LIFO)
- 添加和删除数据只能在一端进行
- 只能访问到顶端的数据
- 要想访问中间的数据,必须通过出栈操作将目标数据移到栈顶
- 很适合『只需要访问最新数据』的情况
4.队列
概念图
队列也是线性排列的。队列就像排队取款的人,只能从前面往后处理,新来的人只能排在队尾。
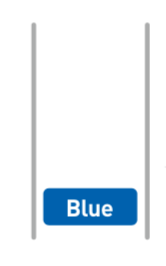
添加数据 - 入列
往队列中添加数据的操作叫做入列
添加Green:
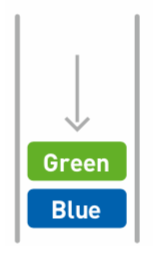
添加Red:
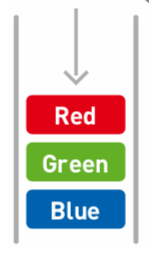
取出(删除)数据 - 出列
从队列中取出(删除)数据的操作叫做出列
例,我们要取出Green:
① 先取出(删除)Blue:
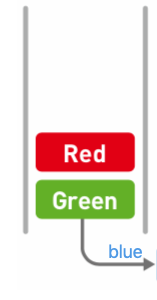
② 这时Green在头部,才能通过出列操作取出(删除):
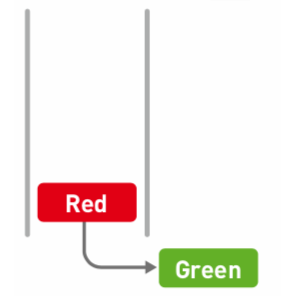
特点
由上述内容我们可以看出,队列有以下特点:
- 『先进先出』,First In First Out (FIFO)
- 添加和删除数据是在两端进行的(添加-尾端,删除-头部)
- 只能访问到头部的数据
- 要想访问中间的数据,必须通过出列操作将目标数据移到头部
- 很适合『先来的数据先处理』的情况
进阶-几种复杂的数据结构
埋坑,后续补充
- 哈希
- 堆
- 二叉树