第二期扩展实践:提升模型精度的几种尝试 - leewishyuanfang/ModelArts-Lab GitHub Wiki
在【华为云 ModelArts-Lab AI实战营】第二期 (https://github.com/huaweicloud/ModelArts-Lab/tree/master/train_inference/image_recognition)的猫狗图像分类问题中,训练得到的模型的精度大概在82%左右,要求能够通过调试提高模型的精度。 通过三天的艰苦奋斗,我终于得到了识别精度在96%的猫狗分类模型,其中酸甜只有自己知道。下面,就把这几天以来的实践过程总结如下:
**1. 实践第一步:调整batch_size(批大小)、learning_rate(学习率)、max_epochs(最大训练轮数)等超参
-
实践第二步:分析模型精度不高的原因:过度拟合问题
-
实践第三步:通过L1、L2正则化方法来尝试缓解过度拟合问题
-
实践第四步:通过图像增强技术来尝试缓解过度拟合问题
-
实践第五步:通过增加训练图片的方式来尝试缓解过度拟合问题
-
实践第六步:通过简化模型结构的方式来尝试缓解过度拟合问题
-
实践第七步:通过resnet的预训练模型来最终得到高精度模型**
接下来,就具体介绍实践的详细过程。 首先,我是在华为ModelArts提供的NoteBook开发环境中进行本次实践的,实践所基于的最初脚本来自于【华为云 ModelArts-Lab AI实战营】第一期(https://github.com/huaweicloud/ModelArts-Lab/issues/49)所提供的第二个实践(https://github.com/huaweicloud/ModelArts-Lab/blob/master/notebook/DL_image_recognition/image_recongition.ipynb)。
第一次接触ModelArts提供的开发环境并使用jupyter notebook进行在线编程,不得不先点个赞。
第一, 开发环境提供了高性能的计算能力,开发者无需像在本机开发一样苦恼计算能力的不足,也无需为TensorFlow开发环境发愁(我在本机安装TensorFlow开发环境时,也遭遇过无数的坑,甚至为此专门换了一台电脑);
第二, jupyter notebook提供了分段编程的能力(这个叫法可能并不准确,因为我也是第一次用),可以编辑一段代码就执行一段代码,每段代码执行后均记录了执行后的系统环境,使得编辑了一段代码后,不用将所有代码全部执行一遍,而是只需重新执行本段代码即可。在实践中,因为需要从网上下载训练集和加载训练集到内存中,如果没有这个功能,同时又不改原始代码的话,就意味着每执行一次,大量时间都浪费在下载训练集和加载训练集上了。
但也不得不说,好东西就是贵,我用的开发环境是带GPU进行训练的,每小时的费用是7.6元,一不留神,可能就欠费了。所以一旦完成练习,一定要记得关闭NoteBook
1. 实践第一步:调整batch_size(批大小)、learning_rate(学习率)、max_epochs(最大训练轮数)等超参
一开始,我也是按照第二期的附加题提供的思路一,想通过调整batch_size(批大小)、learning_rate(学习率)、max_epochs(最大训练轮数)等超参,来提高模型的精度。这一步骤花费了我大量的时间,但却总是得不到好的实验结果,模型的精度很难提高到84%以上。即便偶尔超过了84%,用同样的参数在下次实验时往往又没办法重现,最终,不得不放弃这个思路。
2. 实践第二步:分析模型精度不高的原因:过度拟合问题
在通过调整超参来提高模型精度的尝试失败后,我便想先静下来分析一下精度始终上不去的原因。在查看模型训练时的每个epoch的输出时,我发现:随着模型在训练集上的精度的不断提高,模型在验证集上的精度在达到80%左右后,就会开始震荡,不再提高。
在程序中,通过early_stoping来防止过度拟合问题,early_stoping可以确保当模型在验证集上的精度上不去时,提前结束模型训练。
 当去掉模型训练中设置的early_stoping(如上图所示),并把最大epochs改为30,我们可以从训练过程中更加清楚地发现过度拟合问题:
当去掉模型训练中设置的early_stoping(如上图所示),并把最大epochs改为30,我们可以从训练过程中更加清楚地发现过度拟合问题:

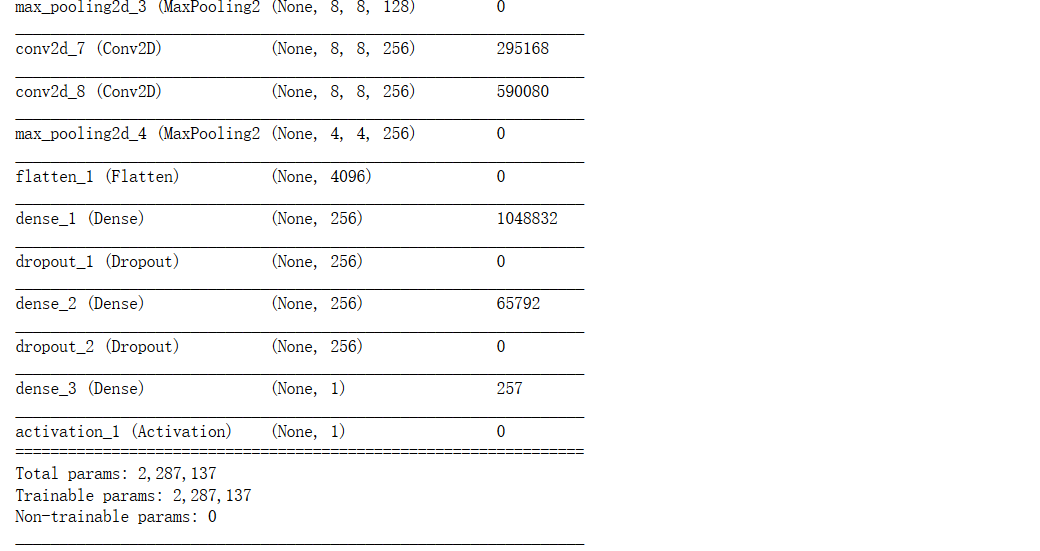
随着epochs的增加,模型在训练集上的精度越来越高(超过了97%),但在验证集上的精度却只能保持在80%左右震荡。 我们来看模型的结构图
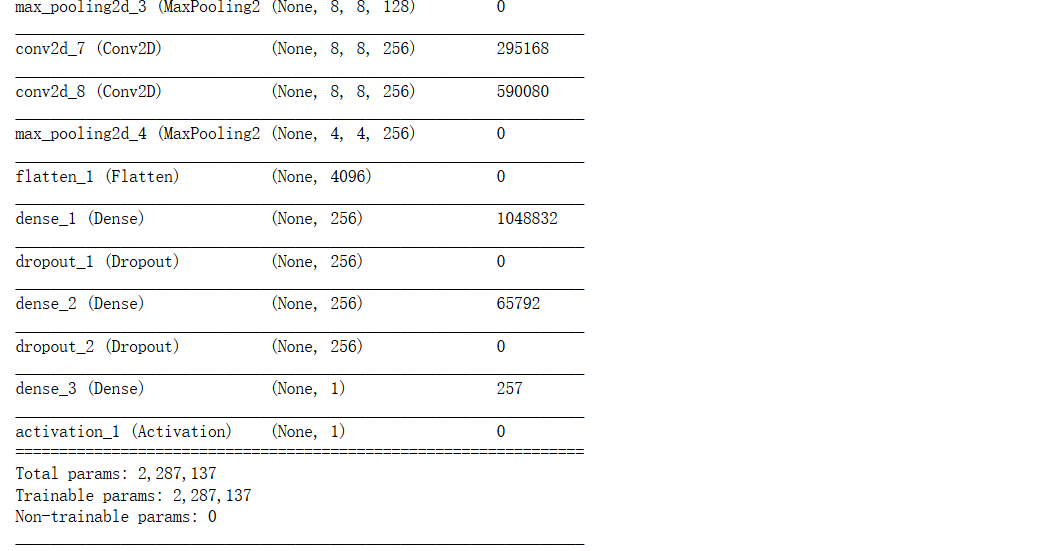
从结构图我们可以看出,整个模型有近230万个参数需要进行训练,而数据集的整个大小只有25000张图片,除去25%的测试集,再从剩下的图片中再除去25%的验证集,实际上只有14062张图片用于训练,相比参数个数来说,训练集太小了。 那么,我接下来的思路就是:如何缓解过度拟合问题。 在第一期提供的代码中,其实已经采用了early stoping和Dropout(随机失活,在学习过程中通过将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性)来缓解过度拟合问题。但要想进一步提高模型精度,我们需要采用其他更多的方法。 缓解过度拟合,有这几个思路: (1) 使用L1、L2正则化 (2) 通过图像增强技术来扩展训练集 (3) 实际增加训练集中图片数量 (4) 调整模型的网络结构 下面,将逐一进行尝试
3. 实践第三步:通过L1、L2正则化方法来尝试缓解过度拟合问题
在这一步骤中,我尝试在模型中加入L1、L2正则化,如下图所示:


结果发现,加入正则化后,模型精度反而下降了……
 尝试失败。
尝试失败。
4. 实践第四步:通过图像增强技术来尝试缓解过度拟合问题
接下来,我尝试通过图像增强技术来缓解过度拟合问题 图像增强,也就是通过旋转、放大缩小、平移、翻转等方式,从原始图片中生成新的图片,从而增加数据集中的图片数量。 具体的代码如下: 首先,把整个数据集进行重新整理,分为训练集、验证集和测试集三个文件夹,其中,训练集、验证集文件夹中的图片又分为cat和dog两个文件夹
将猫狗数据集进行随机划分分组
import shutil import os from tqdm import tqdm_notebook from random import shuffle
if os.path.exists('./data /train/'): shutil.rmtree('./data/train/') if os.path.exists('./data/validation/'): shutil.rmtree('./data/validation/') if os.path.exists('./data/test/'): shutil.rmtree('./data/test/') def organize_datasets(path_to_data, n=4000, val_ratio=0.2,test_ratio=0.2): files = os.listdir(path_to_data) files = [os.path.join(path_to_data, f) for f in files] shuffle(files) files = files[:n] test_n = int(len(files) * test_ratio) test, train = files[:test_n], files[test_n:] val_n = int(len(train) * val_ratio) val,train = train[:val_n], train[val_n:] for c in ['dogs', 'cats']: os.makedirs('./data/train/{0}/'.format(c)) os.makedirs('./data/validation/{0}/'.format(c)) os.makedirs('./data/test/{0}/'.format(c))
print('folders created !')
for t in tqdm_notebook(train):
if 'cat.' in t:
shutil.copy2(t, os.path.join('.', './data', 'train', 'cats'))
else:
shutil.copy2(t, os.path.join('.', './data', 'train', 'dogs'))
for v in tqdm_notebook(val):
if 'cat.' in v:
shutil.copy2(v, os.path.join('.', './data', 'validation', 'cats'))
else:
shutil.copy2(v, os.path.join('.', './data', 'validation', 'dogs'))
for v in tqdm_notebook(test):
shutil.copy2(v, os.path.join('.', './data', 'test'))
print('Data copied!')
organize_datasets('./data/data/', n=25000, val_ratio=0.25,test_ratio=0.25)
接下来,创建训练集和验证集的基于图像增强的图像生成器
通过图像增强技术生成训练数据集和验证数据集的生成器
train_datagen = ImageDataGenerator(rescale=1 / 255., shear_range=0.2, zoom_range=0.2, horizontal_flip=True ) val_datagen = ImageDataGenerator(rescale=1 / 255.) train_generator = train_datagen.flow_from_directory( DATA_DIR+'train/', target_size=(ROWS, COLS), batch_size=400, class_mode='categorical')
validation_generator = val_datagen.flow_from_directory( DATA_DIR+'validation/', target_size=(ROWS, COLS), batch_size=batch_size, class_mode='categorical') 在训练模型时,不再使用model.fit方法,而是model.fit_generator方法 model.fit_generator( train_generator, steps_per_epoch=2000, epochs=50, validation_data=validation_generator, validation_steps=5, verbose=2, shuffle=True, callbacks=[history, early_stopping]) 通过上述修改,模型训练时,将通过训练生成器和验证生成器来生成训练所需的图片,从理论上来说,图片数量可以是无穷的。 然而,实践发现:通过这种方式,模型的训练过程变得很缓慢,而且收敛速度也大大降低了,除此之外,模型在验证集上的精度在80%左右仍然开始了震荡。使得我不得不也放弃了这种思路。

5. 实践第五步:通过增加训练图片的方式来尝试缓解过度拟合问题
既然图像增强没办法达到目的,我接下来就是尝试扩大猫狗数据集中图片的数量。通过网上搜索,我发现第二期实践提供的猫狗数据集来自于kaggle比赛中猫狗大战数据集中的训练集。于是,我从网上找到了kaggle比赛中猫狗大战数据集中的测试集(共12500张图像),并通过已有分类模型,完成了测试集中图像的标注,然后将这12500张图像加入到数据集中开始新一轮的训练。 最终,训练精度提升了不到2%,模型的精度仍然达不到要求,实践再次失败。
6. 实践第六步:通过简化模型结构的方式来尝试缓解过度拟合问题
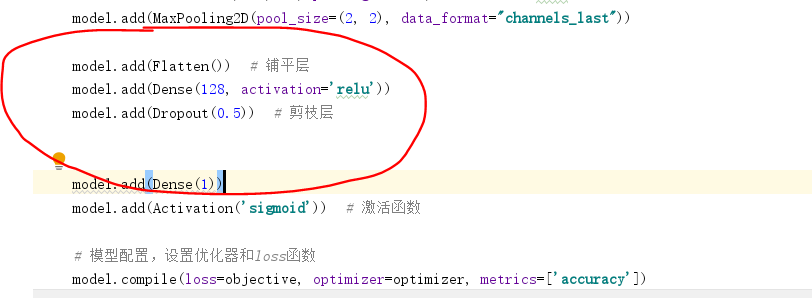
为什么增加了数据集的大小,模型的精度提升仍有限呢?我的理解是增加的图像数量仍不足。尽管将数据集扩充了一半,但相比模型中待训练的近230万个参数,这种提升仍是有限的。因此,接下来我开始考虑从模型本身的结构入手,来提升模型的精度。 我重新回顾了一下模型的结构图,发现模型的参数之所以这么多,主要在于模型最后添加了两个全连接层(分别有256个节点)作为隐含层,这两个隐含层的参数个数就高达170余万,占据了所有参数的74%。
 程序中添加了两个全连接层
程序中添加了两个全连接层

那么,为了减少需要训练的模型参数,我决定先去掉一个全连接层,并把剩下的全连接层的节点数量减少为128
只使用一个全连接层
 此时,模型的可训练参数数量减少为170万个左右,那么再尝试训练模型。
此时,模型的可训练参数数量减少为170万个左右,那么再尝试训练模型。
 训练过程的日志输出如下:
训练过程的日志输出如下:
终于,模型的精度第一次提升到了86%以上。由此可见,模型并不是越复杂越好,而是要跟训练集的大小相适应。网络的结构对于模型精度的影响要大于batch_size(批大小)、learning_rate(学习率)、max_epochs(最大训练轮数)等超参对模型精度的影响。
7. 实践第七步:通过resnet的预训练模型来最终得到高精度模型
尽管模型精度提升到了84%以上,但仍有14%左右的图像是没有办法正确识别出来的。为此,我继续尝试通过resnet网络来进行猫狗图像识别的模型训练。 相比之前实验中采用的VGG16网络,resnet网络要更加复杂,模型的参数数量要更多,如果仅通过已有的25000张图片来训练resnet网络,是远远不够的,幸运的是,resnet网络也提供了若干预训练模型,来加速网络的训练和提升精度。 所谓的预训练模型,就是实现使用大型的图像分类数据集完成了对模型的训练,并将训练后的模型参数保存下来。在我们的训练过程中,就可以在创建模型时直接导入这些已经训练好的模型参数,然后再对模型的某些层展开训练(这里一般指的是模型最后的全连接层)。 采用预训练模型,能够充分利用模型在大型数据集上已经提取出来的图像特征,使得即便只有少量的训练数据,也能够达到很高的训练精度,训练速度也大大提高。 接下来。我们就对我们的程序进行改造,具体代码如下: 只需将原有程序中模型创建的这部分代码:

改为以下代码: from keras.applications.resnet50 import ResNet50
导入预训练模型
base_model = ResNet50(weights='imagenet', include_top=False, pooling=None, input_shape=(ROWS, COLS, CHANNELS), classes=2)
冻结base_model所有层,这样在训练时,这些层的参数不会再参与训练
for layer in base_model.layers: layer.trainable = False x = base_model.output #添加自己的全链接分类层 x = Flatten()(x)
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x) predictions = Dense(2, activation='softmax')(x) #获得最终模型 model = Model(inputs=base_model.input, outputs=predictions) 在这里,我们采用的是resnet在imagenet这个数据集上训练得到的预训练模型。Imagenet数据集有1400多万幅图片,涵盖2万多个类别。当使用ResNet50()导入模型时,程序会自动联网到github上下载预训练模型(这里我得吐槽一句,为啥我在本机直接从github上下载预训练模型就只有不到15kb的下载速度,而NoteBook就几乎是瞬间下载…)。 程序的其他部分不变,我们再次展开实验

我们可以发现,模型在训练集和验证集上的精度,均得到了极大提高 最终,在测试集上的精度如下:

可以看到,最终的模型在测试集上的分类精度高达96%,几乎是完美完成了分类任务。 由此,可以总结如下:采用常用模型的预训练模型,可以大大缩短模型训练的时间,提高模型的精度。在训练数据不充分,计算资源和开发时间有限的情况下,采用预训练模型是我们的最佳选择。