汉语当用片假名表 - johanzumimvon/6 GitHub Wiki



汉语当用片假名表, 是指为了方便大多数人的认读而设计的简化形假名表.
括号内为片假名的实际字形
| a | i | u | e | o | ||
|---|---|---|---|---|---|---|
| ア | イ | ウ | エ | オ | ー | |
| k、c拉丁语、ch拉丁语 | カ | キ | ク | ケ | コ | ㇰ(コ) |
| kᵘ | 𰀪 | キ | ク | 𠀐 | 弋 | ク |
| g | ガ | ギ | グ | ゲ | ゴ | ㇰ゙ |
| θ̠~s、th | サ | シ | ス(ㇲ̅) | セ(𠂉) | ソ | ㇲ |
| ʃ | サ゚ | シ゚ | ス゚ | セ゚ | ソ゚ | ㇲ゚ |
| t | タ | 丌 | ト゚(上) | テ | ト(𛄠) | ㇳ |
| d | ダ | 丌゙ | ト゚゙ | デ | ド | ㇳ゙ |
| ʦ、z、sz、ț、c(ハーリ语、某些语言) | チャ(大) | チ | ツ | チェ | チョ | ㇳ |
| ʣ、j大多数情况 | チャ゙ | ヂ | ヅ | チェ゙ | チョ゙ | ㇳ |
| n | ナ | ニ | ヌ(ㇴ̅) | ネ | ノ | ㇴ |
| ṇ | ナ゚ | ニ゚ | ヌ゚(ㇴ゚̅) | ネ゚ | ノ゚ | ㇴ゚ |
| ñ、gn法语 | ナ゙ | ニ゙ | ヌ゙(ㇴ゙̅) | ネ゙ | ノ゙ | ㇴ゙ |
| ħ | ハ(ハ̅) | ヒ | 乛̲ | ヘ | ホ | ᆽ |
| ʕ | ア̲ | イ̲ | 㝉 | |||
| ɸ、ph | ファ | フィ | フ | フェ | フォ | ㇷ |
| p | パ(𠔀) | ピ(𰀄) | プ(乜) | ペ(ヘ†) | ポ(ホ̅) | ㇷ゚ |
| b | バ(𠔀゙) | ビ(𰀄゙) | ブ(乜゙) | ベ | ボ(ボ̅) | ㇷ゙(或者ㇷ゚) |
| m | マ | ミ | ム | メ | モ | ㇺ(∠) |
| i、j圣经、拉丁语 | ヤ | イ | ユ | 𛄡 | ヨ | イ或者イ̲ |
| l | ラ | リ | ル | レ | ロ | ㇻ̲ |
| w | ワ( ) ) |
ヰ | ウ | ヱ | ヲ | ウ |
| ŋ | ン゚ |
| ĭa | ĭu | ĭo | ə、e(汉语拼音)、eo | æ、ae、ai(汉语拼音) | ɔ、ao(汉语拼音)、au(新式汉语拼音) |
|---|---|---|---|---|---|
| ャ | ュ | ョ | エォ | アェ | アォ |
| ㅑ | ㅠ | ㅛ | ㅓ | ㅐ | ᅶ |
比如:
| 搭配 | 音 | 转写 |
|---|---|---|
| リャ | 俩 | lĭa |
| リュ | 刘 | lĭu |
| リョ | 料~刘(类似于拼音liou) | lĭo |
| レォ | 乐 | lə, leo(不方便时) |
| ラェ | 莱 | læ, lae(不方便时) |
| ラォ | 捞 | lɔ, lao(不方便时) |

其中, 在特殊情况下, 丌゙ュ(diu)拼写作デュ, 丌ュ(tiu)拼写作テュ, イ(i、yi、ji(圣经或者拉丁语(ラ丌ナ)))拼写作イ̲, 但發音不变.
这种特殊拼写只出现于与基督教、伊斯兰教有关的ヲーㇳ゙中.
之所以保留这样看似怪异的拼写, 实际上就是对拉丁语ラ丌ナ的尊重、对上帝的敬畏, 比如
| ヲーㇳ゙ | 来源 | 含義 |
|---|---|---|
| デュㇲ | Deus | 上帝, 无限实体 |
| イ̲ースーㇲ | Jēsūs | 耶稣 |
| イ̲ーサー | عيسى, Īsā, ʕīsā | 尓撒, 伊斯兰教对耶稣的称呼 |
简易片假名, 是指發音上有所简化的片假名形式.
比如浊音假名变成清音:
| 原 | 简化 |
|---|---|
| ガ | カ |
| ギ | キ |
| グ | ク |
| ゲ | ケ |
| ゴ | コ |
| ㇰ゙ | ケォ |
| サ゚ | サ或者シャ |
| シ゚ | シ |
| ス゚ | ス或者シュ |
| セ゚ | セ |
| ソ゚ | ソ或者ショ |
| ㇲ゚ | ㇲ |
| ザ | チャ |
| ジ | チ |
| ズ | ツ |
| ゼ | チェ |
| ゾ | チョ |
| ㇲ゙ | ㇳ |
| チャ゙ | チャ |
| ヂ | チ |
| ヅ | ツ |
| チェ゙ | チェ |
| チョ゙ | チョ |
| チ | ㇳ |
| ヂ | テォ |
| タ゚ | ト゚ヮ |
| 丌゚ | 丌 |
| ト゚゚ | ト゚ |
| テ゚ | ト゚ヱ |
| 斗゚ | ト゚ヲ |
| ㇳ゙ | テォ |
| ダ | タ |
| 丌゙ | 丌 |
| ト゚゙ | ト゚ |
| デ | テ |
| ド | ト |
| ㇳ゙ | テォ |
| ナ゚ | ヌヮ |
| ニ゚ | ニ |
| ヌ゚ | ヌ |
| ネ゚ | ヌヱ |
| ノ゚ | ヌヲ |
| ㇴ゚ | ㇴ |
| ナ゙ | ナ或者ニャ |
| ニ゙ | ニ |
| ヌ゙ | ヌ或者ニュ |
| ネ゙ | ネ |
| ノ゙ | ノ或者ニョ |
| ㇴ゙ | ㇴ |
| バ | パ |
| ビ | ピ |
| ブ | プ |
| ベ | ペ |
| ボ | ポ |
| ㇷ゙ | ㇷ゚ |
虽然サ゚、ス゚、ソ゚、ナ゙、ヌ゙、ノ゙可简化作シャ(瞎)、シュ(羞)、ショ(削)、ニャ(nia)、ニュ(牛)、ニョ(尿、鸟), 但由于这些音大多与汉语中的贬义词有关, 比如シャ音似瞎; ニャ音似尖叫声, 这也是为什么大多数语言缺少シャ、シュ、ショ、ニャ、ニュ、ニョ, 因此简化作サ、ス、ソ、ナ、ヌ、ノ可能更好.
其中, 有些ヲーㇳ゙的音译时间早, 因此不遵循上表规则:
| 例外者 | 来源 | 含義 |
|---|---|---|
| コラㇺ | gram | 公克 |
| キロコラㇺ | kilogram | 千克 |
| コライキア | gricia | 希腊 |
| コライカ | graica | 希腊风格的 |
| イコライカ | Y, y | 第25个拉丁字母 |
| コロコスㇺ | glucosum | 葡萄糖 |
以比如一些ヲーㇳ゙由于其浊音与m、n相邻, 其会直接被清化, 就像ヱㇳナㇺ(越南)这一情形:
| 拼写 | 来源 |
|---|---|
| セㇳナ | sedna |
| アㇳミㇴ | admin |
| アㇰマ丌ㇴ | agmatine |
| タㇰマ | tagma |
| 丌ㇰメㇴ丌ㇴ | tigmentin |
| リㇰニㇴ | lignin |
这就相当于atman(アㇳマㇴ)、atmosphaera(アㇳモㇲファェラ)、pneumonia(ㇷ゚ネウモニア)、satnav(サㇳナウ)、tatmo(タㇳモ)、tetminus.
另外, tr前面是辅音时, 转写作チャ|チ|ツ|チェ|チョ; dr前面是辅音时, 转写作チャ゙|ヂ|ヅ|チェ゙|チョ゙, 比如astro转写作アㇲチョ(太空)
ツㇷ゚ 天体
テㇴモㇴハㇰ 天文
引号仅用于说话或者声明、言论, 不得用于其他用途
括号仅用于数学代数的运算顺序.
| 名称 | 当用 |
|---|---|
| 顿号、 | , |
| 逗号,, | ၊ |
| 分号;; | ラㅣ |
| 句号。. | ။ |
| 叹号!! | ヘー။ |
| 问号? ? | エー။ |
| 冒号:: | 仌 |
| 比例 | a:b |
| 引号 | 「モモモ」 |
| 次级引号 | 「၊モモモ」 |
| 次次级引号 | 「။モモモ」 |
| 括号, 仅用于数学(モモモ) | [モモモ] |
| 次级括号 | [၊モモモ] |
| 次次级括号 | [။モモモ] |
| 次次次级括号 | [။၊モモモ] |
| 次次次次级括号 | [။။モモモ] |
| 书名号《》 | 废除, 或併入专有名词 |
| 上取整 | y=⌈x⌉ |
| 下取整 | y=⌊x⌋ |
| 隐讳号××× | モモモ |
| 破折号—— | ____ |
| 省略号…… | エトラ |
| 加号 | + |
| 减号− |  |
| 乘号× | · |
| 专有名词中缀 | · |
| 专有名词前缀 | † |
| 除号 | ÷ |
| 自然对数 | ln |
| 十二进制对数 | lγ |
| 等号 | = |
| 小数点 | ラ |
| 化学方程式等号 | ══ |
| 馀数 | モㇳ |
| 大于 | > |
| 小于 | < |
| 约等于 | ≈ |
| 阶乘 | ! |
| 双阶乘 | !! |
| 质数阶乘 | pr(n)或者πr(n) |
| 数词连接号~ | ~ |
| 名词连接号- | モモモオーモモモ |
| 名词连接号- | モモモ__モモモ |
| 比例号 | a:b=a÷b |
| 组合 | |
| 连比号 | a:b:c |
| 令, 设 | レー |
| 求证, 寻见 | レイ |
| 证明 | イレ |
| 因为 | イ |
| 所以, 因此 | レ |
| 虚数单位 | ī |
| 自变量 | x |
| 因变量 | y |
| y=f(x) | y=フ(x) |
| 导函数符号 | ' |
| 二阶导函数 | " |
| 积分符号∫ | イ |
| 不定数m | m |
| 不定数n | n |
| a(代数符号) | イ |
| b | ロ |
| c | ハ |
| d | ニ |
| e | ホ |
| f | ヘ |
| g | ト |
| h | 丌 |
| i | リ |
| j | ヌ |
| k | ル |
| l | ヲ |
| 长度 | ミㇳレペ |
| 米 | ミㇳレ |
| 质量 | 기ロㇰラㇺペ |
| 千克 | 기ロㇰラㇺ |
| 公克 | ㇰラㇺ |
| 时间 | セクㇴト゚ㇲペ |
| 秒 | セクㇴト゚ㇲsecundus |
| 物量 | モㇻ̲ペ |
| 摩尔 | モㇿ, モㇻ̲ |
| 温度 | ケㇻ̲ヰㇴペ |
| 开尔文 | ケㇾヰㇴ, ケㇻ̲ヰㇴ |
| 电量 | クーロㇺペ |
| 库仑 | クーロㇺ |
| 新库仑 | 기ーロㇺ |
| 库仑常数 | クーロㇺスー |
| 能量 | エネㇻ̲ギーア |
| 某某能 | 某某コー弋ㇴ |
| 焦耳 | ツㇿ, ツㇻ̲ |
| 压强 | パㇲカㇻ̲ペ |
| 帕斯卡 | パㇲカー |
| 力 | ニュートㇴペ |
| 牛顿 | ニュートㇴ |
| 电流 | アㇺペアペ |
| 安培 | アㇺペー |
| 电势 | ヲーㇳペ |
| 伏特 | ヲーㇳ |
| 电阻 | オーㇺペ |
| 欧姆 | オーㇺ |
| 辐射 | レㇺペ |
| 雷姆 | レㇺ |
| 遬率 | チェㇳペ |
| 卩 | チェㇳ |
y=f(x)在的不定积分可以表示为「イフ(x)드x」
a~b的定积分只需在「イ」下边加「b」, 下边加「a」即可။
ラ
「ラ」读作「拉」
| 算筹 | 大小 |
|---|---|
| ロ | 0 |
| 𝍠 | 1 |
| 𝍡 | 2 |
| 𝍢 | 3 |
| 𝍣 | 4 |
| 𝍤 | 5 |
| 𝍤̅ | 6 |
| 𝍥 | 7 |
| 𝍦 | 8 |
| 𝍧 | 9 |
| 𝍨 | ∗ |
| 𝍨̲ | # |
ロ
𝍩
𝍪
𝍫
𝍬
𝍭
||||||
𝍮
𝍯
𝍰
𝍱
𝍱|
e=2;875236
e=𝍪ラ𝍦𝍮𝍤𝍪𝍢||||||
以下历法, 除了公历, 建议以1989年为0年, 也就是坦克纪年, tankannus, タㇴカヌㇲ.

开始时间相当于1989年6月4号
土卫六, 又名saturnus'hokampa, saturnus'heks.
土卫六历法, 是指基于土卫六的历法, 由于土卫六的自转周期等于其公转周期, 因此像月亮总是一面朝向地球一样, 土卫六则总是一面朝向土星.
土卫六的一年实质上就是土星的公转周期, 也就是土卫六绕土星公转, 然後土卫六跟随土星绕太阳公转.
土星每公转一圈, 土卫六就会自转674.75482ラ9圈, 由于土星的公转会使太阳自西嚮东逆行一圈, 从而稍微抵消自转引起的太阳东升西落, 因此一个土卫六年有673.75481ラ9昼夜.
因此, 土卫六的历法(calendarum)是这样的, 也就是每个土星年有674482天或者673481天; 四土卫六年有26951687天
$10759.22÷15.945421=\frac{10759.22}{15.945421}=\frac{10759220000}{15945421}=674.75$
| 年 | 昼夜数 |
|---|---|
| 4n | 673 |
| 4n+1 | 674 |
| 4n+2 | 674 |
| 4n+3 | 674 |
土卫六的發现者是惠更斯(ホイゲㇴㇲ, Huygens, 慧根斯)
开始时间相当于 1989年6月4号
木星每公转一週, 木卫二就会自转1220週.
$10759.22÷15.945421=\frac{4332.589}{3.551181041}=\frac{4332589000000}{3551181041}=1220+\frac{1}{24}$
如果算入公转的抵消, 则木卫二的一年有1219.0417天.
木卫二平年有1219857天; 闰年有1220858天.
每二十四木卫二年, 木卫二就会迎来一次闰年, 有1220858天.
| 年 | 昼夜数 |
|---|---|
| 24n | 1220 |
| 24n+1 | 1219 |
| 24n+2 | 1219 |
| 24n+3 | 1219 |
| 24n+4 | 1219 |
| 24n+5 | 1219 |
| 24n+6 | 1219 |
| 24n+7 | 1219 |
| 24n+8 | 1219 |
| 24n+9 | 1219 |
| 24n+10 | 1219 |
| 24n+11 | 1219 |
| 24n+12 | 1219 |
| 24n+13 | 1219 |
| 24n+14 | 1219 |
| 24n+15 | 1219 |
| 24n+16 | 1219 |
| 24n+17 | 1219 |
| 24n+18 | 1219 |
| 24n+19 | 1219 |
| 24n+20 | 1219 |
| 24n+21 | 1219 |
| 24n+22 | 1219 |
| 24n+23 | 1219 |
人们普遍认为木卫二是伽利略(ガリレオ, 伽利丽欧)發现; 但是木卫二实际上由战国时期的甘德(カㇺトㇰ)發现.

ガリレオ卫星之發現者, 實 甘德カㇺトㇰ 也. ガリレオ应谓之 カㇺトㇰ卫星, カㇺトキア.
中国战国时期,天文学家甘德(カㇺトㇰ)的著作《星经》与《天文星占》中提到 仌
木星与其旁边小星的组成的系统,小星从属于木星,木卫一和木卫三呈黄色,木卫二和木卫四呈橙色.
月亮历, 是指根据月亮表面的昼夜交替与斗转星移设计的历法. 每19年闰6次.
| 年 | 昼夜数 |
|---|---|
| 19n | 13 |
| 19n+1 | 12 |
| 19n+2 | 12 |
| 19n+3 | 13 |
| 19n+4 | 12 |
| 19n+5 | 12 |
| 19n+6 | 13 |
| 19n+7 | 12 |
| 19n+8 | 12 |
| 19n+9 | 13 |
| 19n+10 | 12 |
| 19n+11 | 12 |
| 19n+12 | 13 |
| 19n+13 | 12 |
| 19n+14 | 12 |
| 19n+15 | 13 |
| 19n+16 | 12 |
| 19n+17 | 12 |
| 19n+18 | 12 |

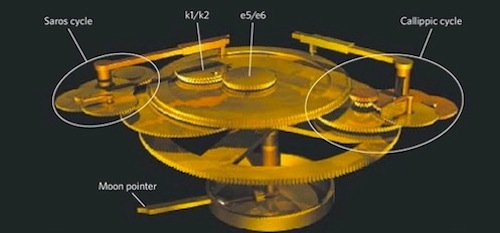
每19年闰7次.
蔀, 亦名Callippic cycle, 是指回归年与朔望月与平太阳日的最短循环. 传统上以76年为1蔀.
| 年 | 月数 |
|---|---|
| 19n | 13 |
| 19n+1 | 12 |
| 19n+2 | 12 |
| 19n+3 | 13 |
| 19n+4 | 12 |
| 19n+5 | 12 |
| 19n+6 | 13 |
| 19n+7 | 12 |
| 19n+8 | 12 |
| 19n+9 | 13 |
| 19n+10 | 12 |
| 19n+11 | 13 |
| 19n+12 | 12 |
| 19n+13 | 12 |
| 19n+14 | 13 |
| 19n+15 | 12 |
| 19n+16 | 12 |
| 19n+17 | 13 |
| 19n+18 | 12 |
[12;2,1,2,1,1,17,3,5,6,41,3,2,1,3,1,4,7,1]
如果考虑到下边的纯阴历的话, 那么1蔀应该是49·19=931年
开始时间仌 六四纯阴历0年1月1号, 相当于公元1989年1月8号
[29;1,1,7,1,2,17]
| 月 | 昼夜数 |
|---|---|
| 1 | 30 |
| 2 | 29 |
| 3 | 30 |
| 4 | 29 |
| 5 | 30 |
| 6 | 29 |
| 7 | 30 |
| 8 | 29 |
| 9 | 30 |
| 10 | 29 |
| 11 | 30 |
| 12 | 29或30 |
其中, 每经过49「年」会有26「年」的第12月有30天; 23「年」的第12月有29天.
开始时间仌 公元0年(相当于公元前1年)
| 年 | 昼夜数 |
|---|---|
| 4000n | 365 |
| 400n | 366 |
| 100n | 365 |
| 4n | 366 |
| n | 365 |
| 年月份 | 昼夜数 |
|---|---|
| 1 | 31 |
| 2 | 28或者29 |
| 3 | 31 |
| 4 | 30 |
| 5 | 31 |
| 6 | 30 |
| 7 | 31 |
| 8 | 31 |
| 9 | 30 |
| 10 | 31 |
| 11 | 30 |
| 12 | 31 |
其中, 第3月21号是春分; 第6月22号是夏至; 第9月23号是秋分; 第12月23号是冬至; 第3~第5月是春季; 第6~第8月是夏季; 第9~第11月是秋季; 第12月~第2月是冬季.
好的书写系统, 可以让蛮族迅速变得文明; 坏的书写系统或者书写系统与读音的拼读不一致尤其是英语、法语、韩国语, 会严重阻碍文明的發展.
片假名的抗噪能力 | 日本コカコラ可口可乐广告纸上的文字辩识度

三进制的信息单位为trit, 也就是チㇳ.
信息熵取整计算
| 文字种类 | 二进制信息熵 | 三进制信息熵 | 难学度 | 记忆 | 遗忘 | 管理难度 | 字符数 | 拼写长度 | 识别难度 |
|---|---|---|---|---|---|---|---|---|---|
| latin | 4ビㇳ | 3チㇳ | 易学 | 易记 | 难忘 | 易管理 | 17~89; 34~178 | 很长 | 易 |
| ロシア | 4ビㇳ | 3チㇳ | 中等 | 易记 | 难忘 | 易管理 | 35 | 长 | 中 |
| 阿拉伯文 | 5ビㇳ | 4チㇳ | 难学 | 易记 | 难忘 | 中等管理 | 28 | 短 | 难 |
| 训民正音 | 5ビㇳ | 4チㇳ | 易学 | 易记 | 难忘 | 极难管理 | 19+21=40 | 短 | 中 |
| 东南亚文字 | 6ビㇳ | 4チㇳ | 难学 | 难记 | 难忘 | 难管理 | 70~200 | 短 | 难 |
| 片假名 | 7ビㇳ | 5チㇳ | 中等 | 中等 | 难忘 | 中等管理 | 162 | 中等 | 易 |
| 汉字 | 10ビㇳ | 7チㇳ | 难学 | 难记 | 易忘 | 极难管理 | 12366 | 短但是在拼写外来语的时候, 拼写长度与片假名类似 | 难 |
「17」是指允许有「fu」转写「フ」的情况下, 阿伊努语的latin字母数目, 也就是
a, i, u, e, o, k, s, t, ț, n, h, p, f, m, y, l, v
「89」是指在考虑声调的情况下的越南语字母的数目.
片假名虽然有着较大的信息熵, 但是信息熵增加会造成字数的指数增长, 因此片假名即具有远远高于latin字母的信息熵; 相对于汉字, 片假名又容易被管理、传送, 且片假名字符集稳定; 与组成合字的训民正音相比, 片假名容易排版、存储、显示、抄写.
latin字母相当于十进制的乘法表小九九;
片假名相当于十二进制乘法表小十一十一;
汉字相当于六十进制乘法表小五十九五十九.
虽然与没有渡过打字机时代的中国人相比, 韩国人顺利度过了打字机时代, 但是训民正音这个书写系统可以说是书写系统中最大的异类____性质了与latin字母一样属于全音素文字, 但偏偏要每个音节都要组成汉字的形状, 结果在电脑时代吃了大亏____unicode有11172个位置用来专门存储训民正音, 且绝大多数位置对应的训民正音不曾出现于韩国语中, 极之讽刺, 这在管理上极为处于劣势.
即使是王码五笔输入法, 也存在重码乃至出错问题, 除非使用内码输入.
另外, 中文相较其他语言, 严谨之德更弱, 更不适合学术论文. 尤其是对外来语的音译更是一个软肋.
[转载]汉字信息熵劣势
有人尤其是愤青为汉字信息量大而骄傲,殊不知它使得中文信息管理和传递的成本增加,困难加大。
士大夫 議曰
汉字难学、难记、易忘、抄写容易出错康熙字典等等大型汉字检索系统中收录的大多数字都是错字、古字、字根、容易乱码、输入法重码问题
★中文信息产业基础建设的中心课题,就是要利用信息熵的基本原理和方法来提高中文的效率。
美国的信息产业能有今天的称雄世界的实力,能接连不断地产生新的技术产品,是跟坚实的基础建设分不开的。这个基础建设的基本依据,是信息科学技术的基本原理和方法:信息熵information entropy,也就是1个字所能容纳多数信息量。
第二次世界大战期间,美国为了提高信息储存和传递的效率,发明了多种新的编码方法,比如说对于信息熵小的部分,将「quo」编码作「qo」;对于出现率高的字母e、t,使用更短的编码,奠定了现代信息科学技术的基础。战争结束后,这些方法得到了飞跃发展。在这些方法当中,科学家香农サ゚ㇴノㇴ和霍夫曼ホㇷマㇴ提出的信息熵和数据压缩的理论和方法最能代表现代信息学的基本概念。个人计算机和BBS问世以后,信息熵和数据压缩技术迅速普及。现在,这种技术已经成为计算机和联网必不可少的组成部份。
信息熵的基本目的,是找出某种符号系统的信息量和多余度之间的关系,以便能用最小的成本和消耗来实现最高效率的数据储存、管理和传递。
五十年代,现代信息论被介绍到中国;七十年代,中国科学家完成了中文汉字字符信息熵的初步计算工作;八十年代又做了更完整的计算。他们的基本方法是:逐渐扩大汉字容量,随着汉字容量增大,信息熵的增加趋缓;汉字增加到12370以后,不再使信息熵有明显的增加。通过数理语言学中著名的齐普夫定律(zipf’s law)核算,中国科学家指出,汉字的容量极限是12366个汉字,汉字静态平均信息熵的值(平均信息量)是9.65比特。这是当今世界上信息量最大的文字符号系统。下面是联合国五种工作语言文字的信息熵比较:
法文:3.98比特
西班牙文:4.01比特
英文:4.03比特
俄文:4.35比特
中文:9.65比特
可以看出,全音素文字的信息熵小,差别不大。汉字的信息量最大,但是字数很多,因而,在信息管理和传递的时候,中文处于最不利的地位。
(一)
随着计算机的速度、储存和兼容能力等各方面的提高,中文信息管理和传递的困难是否会自动得到解决呢?不一定。例如,即便我们用四个字节来作国际标准字符集(国际标准组织已经多次提出这个方案),使每个汉字有足够的比特剩余来作奇偶检验和特性参数,让所有的计算机和操作系统都能使用,然而,数据全面管理和传递的效率问题依然存在。原因是:
(一)中文数据的文字方式决定了标准的多重性和规模过大,而且,只要汉字还再增加,尤其是文言文类古籍、考古文字、外来语音译用字,它的字符集就是不稳定的。不管一个字符用多少字节,也不管计算机的储存容量有多大,也不管各种系统的兼容有多么全面,这样的字符集做数据储存和检索还可以,做全面的数据管理就总是有严重问题。
(二)不管用什么中文输入方法,汉字输入输出的字符仍然需要多次转换,还是高成本和高消耗的。现有的中文输入方法跟语言文字的标准规范之间的差别依然存在,人的操作和学习等效率还是没有得到提高。电笔和声音输入是重要的技术,但是,这些技术突破并不能取代键盘输入,更不能解决中文的效率问题.
(三)拼音文字的每个字符只要一个字节,现在用两个字节的联码unicode, ユニコード,已经有一个字节是多余的,在做数据处理和传递的时候,为此多支出了一倍的成本包括处理多余字节的程序消耗在内。这些多余成本基本是为了迁就中文、训民正音等等东亚文字的需要。如果用四个字节,就有三个字节是多余的,使用拼音文字就要多支出三倍的成本。将来,各方面的发展能否抵消这些多余成本,还不清楚。拼音文字的母语国家是否乐意为了中国汉字的需要而继续牺牲自己的利益来年复一年地支出更多和毫无回收可能的成本,也不清楚。
(四)通讯传递中,汉字字符由双字节变成了四字节,使原来的成本和消耗增加了一倍,平衡或抵消了字节增加和速度提高所带来的效益。
中文效率的根本问题不是出在计算机方面,而是出在汉字本身。因而,不管用不用计算机,也不管计算机技术怎么发展,中文的低效率问题依然存在。再说,计算机技术发展,所有的语言文字都得益,相比之下,原来高效率的文字方式的效率仍然是高效率的,汉字方式仍然处于不利地位。
(二)
可以看出,汉字信息量大实际上是字符数很多, 就好像六十进制的乘法表一样,是中文信息管理和传递成本高、消耗大和效率低的基本原因。汉字为中国文明的延续发展发挥了巨大的历史作用。今天,汉字方式是阻碍中文信息科学技术发展的头号困难因素。中国可以在信息工业的机械设计和制作方面赶上世界先进水平,然而,如果不能摆正和改善中文的信息熵和多余度之间的关系,那么,中国的信息产业的整体就总是低效率的,就总得跟着别人后面走,难免挨打。一些美国人担心中国发展计算机和导弹技术会造成中国威胁,那的确是夸张了。即便把美国所有的计算机技术和导弹技术都交给中国,只要中国还是按照汉字方式来操作,那么,在计算机和导弹技术方面,中国就总是处于不利地位。中国火箭导弹技术专家钱学森等人早就说过:如何提高中文效率是关系到国家安全的战略大事。
许多从事中文信息熵研究的科学家们说:
中国失去了整整一个打字机时代工业革命,对中国的综合国力建设带来了不利条件;而韩国由于其文字是表音文字,虽然难管理,反而没有错过打字机时代。在计算机信息时代,汉字方式和现代科学技术矛盾更加深化了,其中最大的问题是如何利用信息熵的原理和方法来优化中文数据的管理和传递,其中包括文字方式和书写工具包括计算机在内的最优结合。这是中国科学家约30年之久的中文信息论研究的经验,其中有些科研成果受到了国际科学界的承认和高度重视。面对日益强盛的信息时代的挑战,中国科学家是有充分准备的。如果中国能按照原来准备好了的方向发展,那么,中国的信息产业就会避免许多弯路,微软公司对中国软件市场的误导作用也不会那么严重。
然而,这些年来,中国有些报刊杂志望文生义,以为汉字信息量大是好事情,把它作为鼓吹汉字文化和汉字优越论的依据,甚至把这些违背科学技术基本原理的东西贴上爱国主义的标签。这种作法极大地误导了人们对信息科学技术的理解。微软公司最关心的是中国市场的利润,而不是中文信息科学技术的前途。汉字优越论鼓动人们不要过问中文信息产业发展的基础科学技术问题。
信息科学技术跟语言文字息息相关,它的发展对许多国家的传统文化提出了挑战,包括对美国一类信息工业大国的挑战。中国的历史悠长,文字方式独特,自然就受到最严峻的挑战。面对科学技术的挑战,就要用科学技术的发展来迎战。用极端民族主义的作法回应挑战,最后总是失败,传统文化最后也还是保不住。
中国政府可以通过法律、标准和专利等手段来为中文软件和中文信息产业的发展提供环境保护。然而,发展才是硬道理。中文软件和中文信息产业到底能不能在日益全球化的竞争中幸存,最后还得看自己的基础建设搞得怎么样。就目前和将来的状况来说,中文信息产业基础建设的中心课题,就是要利用信息熵的基本原理和方法来提高中文的效率。