Python_ML - jjin-choi/study_note GitHub Wiki
이거부터 보자 https://lovit.github.io/nlp/representation/2018/03/26/word_doc_embedding/
https://lovit.github.io/nlp/machine%20learning/2018/03/21/kmeans_cluster_labeling/
https://stackoverrun.com/ko/q/7967067
http://doc.mindscale.kr/km/unstructured/04.html
https://frhyme.github.io/python-lib/document-clustering/
[DAY01] Dataset & Performance metrics
======================================
http://www.phontron.com/class/nn4nlp2019/schedule.html // spacy / itidfvectorizer (sklearn.feature_extraction.text) / tsne
https://lss.fnal.gov/archive/2019/slides/fermilab-slides-19-718-cms.pdf http://www.iasonltd.com/wp-upload/all/2020_NPL_Classification_A_Random_Forest_Approach_(Rev).pdf https://ieeexplore.ieee.org/abstract/document/8695493
파이토치
ime2020 https://wikidocs.net/21667
- 두 개 이상의 데이터 프레임을 하나로 합치는 데이터 연결 (cf.merge 와는 다르다)
- 일반적으로 위/아래로 데이터 행을 연결.
- 옆으로 데이터 열을 연결하려면
axis=1
Link: Pandas
pd.concat(list, axis=1)- To avoid overfitting, it is common practice when performing a (supervised) machine learning experiment to hold out part of the available data as a test set
X_test, y_test. - Here is a flowchart of typical cross validation workflow in model training. The best parameters can be determined by grid search techniques.

- A random split into training and test sets
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
X, y = datasets.load_iris(return_X_y,=True)
# Holding out 40% of the data for testing (evaluating) the classifier
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=0)- There is still a risk of overfitting on the test set because the parameters can be tweaked until the estimator performs optimally.
- To solve this problem, yet another part of the dataset can be held out as a so-called “validation set”.
- Training proceeds on the training set, after which evaluation is done on the validation set, and when the experiment seems to be successful, final evaluation can be done on the test set.
- k-fold Cross-validation (CV for short): the training set is split into k smaller sets.
- A model is trained using
k-1of the folds as training data - The resulting model is validated on the remaining part of the data
- The performance measure reported by
k-foldcross-validation is then the average of the values computed in the loop. - Pros: not waste too much data
- Cons: computationally expensive
- A model is trained using

sklearn.model_selection.cross_val_score(estimator, X, y=None, *, groups=None, \
scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', error_score=nan)
# Arguments
# estimator: 대상 data
# cv: default 5-fold 이고 int 값
# scoring: 모델 성능 evaluation rules 에 대한 parameter
# https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter 참고
# Classification / Clustering / Regression 마다 적합한 evaluation function 정의되어있음
# Return
# scores: cross validation 의 score
from sklearn.model_selection import cross_val_score
scores = cross_val_score(data, X, y, cv=5)
print (f"Accuracy : {scores.mean()}")from sklearn import metrics
scores = corss_val_score(data, X, y, cv=5, scoring='f1_macro')- cross_validate != cross_val_score
- cross_validate 는 여러 metrics 에 대해 evaluate 가능
Link : Scikit-learn

- EDA is the process of visualizing and analyzing data to extract insights from it.
- In other words, EDA is the process of summarizing important characteristics of data in order to gain better understanding of the dataset.
- 데이터를 잘 아는 사람들과 토론을 하자 !
- 데이터의 분포 및 값을 검토하여 데이터가 표현하는 현상을 더욱 이해하고 잠재적 문제 발견.
- 다양한 각도에서 살펴보는 과정을 통해 문제 정의 단계에서 다양한 패턴을 발견하여 기존의 가설을 수정하거나 새로운 가설
- 분석 계획에서는 어떤 속성 및 속성 간 관계에 집중적으로 관찰할지, 최적의 방법은 무엇일지 등등
- 분석의 목적과 변수가 무엇이 있는지 확인. 개별 변수의 이름/설명을 가지는지 확인
- 데이터 전체적으로 살펴보기. head 나 tail 부분 확인, 이상치 결측치 등등
- 데이터 개별 속성값 관찰하기. 각 속성 값이 예측한 범위와 분포를 갖는지 확인. 그렇지 않다면 이유 확인
- 속성 간의 관계에 초점을 맞추어 개별 속성 관찰에서 찾아내지 못한 패턴 발견 (상관관계, 시각화)
sns.pairplot(main_df[numeric_col_name]) - Descriptive Statistics
- numerical data
- pd.describe() method 이용하여 brief summary / basic statistics
- sns.boxplot() method 로 graph of distribution
- categorical data
- pd.value_counts() method 이용하여 summary
- numerical data
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy import stats
df = pd.read_csv('input.csv') # read data from CSV file
df.head()
# for numerical data
df.describe() # mean, standard deviation, max & min values
# for categorical data
df['column_name'].value_counts()- Grouping of Data
- pd.groupby() method and pivot
* Handling missing values in dataset
* ANOVA: Analysis of variance
* Correlation
> Link : [EDA](https://medium.com/code-heroku/introduction-to-exploratory-data-analysis-eda-c0257f888676)
y label 의 결과에 따라 각 column 과의 data 분포도를 볼 수 잇음
## □ Stratified sampling
### - 원본 데이터의 y 또는 그룹 비율 고려하여 샘플링
[최진 / Jin Choi] 2020-08-24 11:06
층화 추출 Stratified sampling : 원본 데이터의 y 또는 그룹의 비율을 고려하여 샘플링 실행
[최진 / Jin Choi] 2020-08-24 11:10
pandas 의 Series
- pd.Series(list) 가 있다면 index 와 values 가 동시에 들어간다.
- pd.Series(list, index=index_list) 를 사용하면 index 를 직접 지정해줄 수 있음
- pd.Series(dictionary) dict 형태를 넣어주면 이에 맞게 key (index) : val (data) 로 series 생성
[최진 / Jin Choi] 2020-08-24 11:11
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.html
# Performance metrics
- Model : 고양이와 개를 분류하는 Classification / 상품의 판매량 혹은 주식의 가격 예측하는 Regression
## □ Regression model
### - Scale-dependent Errors
* RMSE (Root Mean Squared Error)
+ 단점 : 예측 대상의 크기에 영향을 받는다.
> <img width="300" src="https://wikimedia.org/api/rest_v1/media/math/render/svg/e258221518869aa1c6561bb75b99476c4734108e"><br/>
```python
from sklearn.metrics import mean_squared_error
RMSE = mean_squared_error(y, y_pred)**0.5- MAPE (Mean Absolute Percentage Error)
- 단점 : 실제값이 1보다 작으면 MAPE 는 무한대에 가까운 값이 나올 수 있음.

- MASE (Mean Absolute Scaled Error)
- 예측값과 실제값의 차이를 평소에 움직이는 평균 변동폭으로 나눈 값.
- MAPE 가 오차를 실제 값으로 나누었지만, MASE 는 평소 변동폭에 비해 얼마나 오차가 나는지를 측정하는 기준.
- 변동성이 큰 지표와 변동성이 낮은 지표를 같이 예측할 때 유용.

from keras import losses
model.compile(loss=losses.mean_squared_error, optimizer='sgd')Link: Memory_Segment
[최진 / Jin Choi] 2020-08-24 11:24
- regression metrics
- root mean squared error (RMSE) : RMSE 값이 27 이면 무슨 의미일까 ?
- R squared = 1 - (MSE/(1/N)*sum(y_i-y_mean)^2)
- mean absolute error (MAE) : 편차에 대한 절대값의 평균.
[최진 / Jin Choi] 2020-08-24 11:51 confusion matrixs (혼합 행렬) : 실제와 예측 레이블의 일치 개수를 matrix 형태로 표현
[최진 / Jin Choi] 2020-08-24 11:57 https://datascienceschool.net/view-notebook/731e0d2ef52c41c686ba53dcaf346f32/
[최진 / Jin Choi] 2020-08-24 12:01 불균일한 dataset 종류
- 하버드 입학 지원자의 합격률은 2 % 인데 우리 모델은 다 떨어진다고 예상하면 정확도는 0.98 이지만, Accuracy 만으로만 모든 data를 처리할 수는 없음.
[최진 / Jin Choi] 2020-08-24 12:03 imbalanced data 가 대부분이기 때문에 딥러닝에서 이를 더 잘 다룬다. 머신 러닝에서는 (통계 기반의) ...
ML (통계학 기반의 모델) / DL (NN 모델들) 최근 딥러닝에서 여러 기법으로 imbalance data 적용한 사례가 많아서 사례 소개정도만 할 예정..
[최진 / Jin Choi] 2020-08-24 12:03 이러한 경우에는 정밀도 (Precision) 을 사용한다.
[최진 / Jin Choi] 2020-08-24 12:05 정밀도는 trade off 가 있음
□ Imbalanced data
[최진 / Jin Choi] 2020-08-24 12:05 https://databuzz-team.github.io/2018/10/21/Handle-Imbalanced-Data/
[최진 / Jin Choi] 2020-08-24 12:08 https://towardsdatascience.com/handling-imbalanced-datasets-in-deep-learning-f48407a0e758
[최진 / Jin Choi] 2020-08-24 12:08 https://towardsdatascience.com/methods-for-dealing-with-imbalanced-data-5b761be45a18
[최진 / Jin Choi] 2020-08-24 12:10 Sensitivity, Recall 민감도 : 실제 긍정 데이터 중 긍정이라고 예측한 비율. 얼마나 잘 긍정이라고 예측하는지 ? 요새는 recall 이라고부름
[최진 / Jin Choi] 2020-08-24 12:14 precision 과 recall 은 trade off 이기 때문에 F1 Score 이라는 통합적 지표가 존재한다..! F1 = 2 ((precision * recall) / (precision + recall))
[최진 / Jin Choi] 2020-08-24 12:15 학사 경고 예측 --> recall 암을 예측 --> precision (아무나 암이라고 하면 리스크가 크다..!)
[최진 / Jin Choi] 2020-08-24 12:16 precision recall curve 사용하여 예측 확률 threshold 변화시켜 precision/recall 측정
[최진 / Jin Choi] 2020-08-24 12:17 임지혜님/공인욱님/신아형님/김상갑님/이규홍님 및 기타 메일등
[최진 / Jin Choi] 2020-08-24 18:47 https://github.com/jjin-choi
[최진 / Jin Choi] 2020-08-24 18:49 jjin-choi / Cj+*
[최진 / Jin Choi] 2020-08-24 20:48 https://3months.tistory.com/325
[최진 / Jin Choi] 2020-08-24 20:49 https://blog.naver.com/PostView.nhn?blogId=youji4ever&logNo=221484324353&parentCategoryNo=&categoryNo=10&viewDate=&isShowPopularPosts=false&from=postView
[최진 / Jin Choi] 2020-08-24 20:49 https://m.blog.naver.com/youji4ever/221705683091
2020년 8월 25일 화요일
[최진 / Jin Choi] 2020-08-25 08:44
- 프로젝트 대상 데이터 및 프로젝트 목적 정하기
- 프로젝트에서 검증하고 싶은 가설 정하기
- 가설에 대한 확인 방법 (시각화, 통계 등) (EDA, Feature Engineering...)
- 기본적인 데이터 전처리 방향 정하기 (모델링)
- 데이터 정리 방향으로 전처리 진행
[최진 / Jin Choi] 2020-08-25 08:45 최종 산출물
- 분석 대상 DATASET
- 시각화 notebook 페이지
- 3개 이상 가설과 그 가설 검증을 위한 시각화 결과물
- 예측 모델개발 notbook 페이지
- 전처리 모듈 개발하기
- hyper parameter 등
[최진 / Jin Choi] 2020-08-25 08:46 dacon.io
[최진 / Jin Choi] 2020-08-25 09:12 지금 할일
- 데이터셋 선정
- 분석 주제 선정
- 가설 선정
-
머신러닝 학습 방법들 Gradient descent based learning Probability theory based learning Information theory based learning (우리가 할 것 !)
-
Entropy 관련 내용 정리하기 공식 데이터의 label 이 존재할 확률, - 가 붙어있는 로그이기 때문에 확률이 1 이면 entropy 가 0 확률이 1 이라는 건 불확실성이 없으므로 entropy 가 0 확률이 작을수록 모호성이 커짐
growing a decision tree 대상 라벨에 대해 어떤 attribute이 더 확실한 ㅈ어보를 제공하는가 ? 로 branch attribute 선택 확실한 정보 선택 기준은 알고리즘 별로 차이남 tree 생성 후 pruning 통해 tree generalization 시행
decision tree 특징 훈련 시간이 길고 메모리 공간 많이 사용 직관적 결과 표현 top-down / recursive / divide and conquer 기법 greedy 알고리즘 -> 부분 최적화
관측치의 절대값이 아닌 순서가 중요 -> outlier 에 이점 자동ㅎ적 변수 부분 선택 scaling 필요 없음
알고리즘
ID3 -> C4.5, CART
연속형 변수를 위한 regression tree 도 존재
Information gain
- 엔트로피 함수를 도입하여 branch splitting
- 엔트로피 사용하여 속성별 분류시 impurity 측정하는 지표
- 전체 엔트로피 - 속성별 엔트로피로 속성별 information gain 계산
- 전체 데이터 d의 정보량, 속성 a로 분류시 정보량, a 속성의 정보 소득 등으로 구할 수 잇음
information gain 문제점 : Attribute 포함된 값이 다양할수록 선택하고자 함 label 값도 작아져서 전체적으로 해당 attribute 의 entropy 가 줄어듦 이를보완하기 위해 C4.5 제안 log를 씌워서 평준화 시켜서 분할 정보 값을 대신 사용
CART 알고리즘
gini index : entropy 와 비슷한 그래프가 그려짐
https://scikit-learn.org/stable/modules/tree.html
tree 라는 알고리즘은, 이는 되도록이면 branch 가 일어났을때 새로 생성되는 branch 를 모호성이 적은 방향으로 y 라벨이 한족으로 많이 치우져서 있는 형태로 측정하는 방법은 gini 와 entropy 를 쓸 수 있음. binary 형태로 구현되어있고 최근에는 gini 가 디폴트
decision tree 생기는 문제점 : leaf node 가 너무 많은 경우 over-fitting impurity 또는 variance 는 낮은데, node에 데이터가 1개 어떤 시점에서 tree pruning 해야할지?
방법:
-
pre-pruning 사전에 값을 정하자 ! 5단계 이하는 내려가지 마 ~ 하위 노드 개수, 하위 노드의 label 비율을 정한다. threshold 잡을 수가 없음. 실험적으로 잡을 수밖에 없음.. CHAID 등 사용 계산 효율이 좋고 작은 dataset 에서 잘 작동 속성을 놓칠 수 있음. under-fitting 가능성 높음
-
post-pruning 오분류율 최소화
머신러닝 교과서 !! 꼭 읽어보기
sklearn.tree.DecisionTreeClassifier
splitter 신경 안써두 댐 max_depth 깊게 들어가는 단계
decision parameter 는 너무 많기 때문에 params = [] 리스트로 만들어서 append 하면 편하다
그리드 서치 (너무 방대해서 베이지안이나 다른 방식 써야하기도 함)
모델에서 결과가 나왔을 때 어떤 feature 가 가장 중요한지 알려주는 장점 !
continuous attribute 나누기
- 불연속적 명목 데이터에 비해 나눌 수 있느 ㄴ구간이 많음 전체 데이터를 모두 기준점으로 하고, 중위값, 4분위수들을 기준점으로 한다. y-class 값이 바꾸는 수를 기준점으로 한다.
chart_studio 는 뭐하는 건지 plotly.figure_factory 는 ?
house prices : advanced regression techniques 해보기
numetrical category feature 나눠서 해두면 나중에 보기 편함
cross validation 사용해서 house_price_with_dt 해보기
앙상블 모델 하나의 모델이 아니라 여러 개 모델의 투표로 y값 예측 regression 문제에서는 평균값을 예측 실시간으로 서비스 하는 경우에는 리소스를 너무 많이 사용하게 됨
kaggle 대세 기법 (structed dataset)
- keywords
valia (가장 기본적인) ensemble boosting bagging adaptive boosting
sklearn.ensemble.VotingClassifier
// bagging // 2_bagging.ipyn 단순히 같은 dataset 으로 만드는 classifier 를 만드는 게 아니라, dataset은 모데이터의 sampling 이므로 dataset 마다 model 을 만들어서 이를 ensemble 해보자. 다양한 sampling dataset 으로 다양한 classifier 만들자.
bootstrapping 학습 데이터에서 임의의 복원 추출 (추출할때마다 데이터를 다시 넣는것) subset 학습 데이터 n개를 추출
외부 input 없이 처음 시작하는 일을 지칭
bootstrap의 subset sample 로 모델 n 개를 학습 -> 앙상블
from sklearn.model_selection import GridSearchCV GridSearchCV : sub sampling 몇개 할건지는 사람이 설정해주는 hyper parameter tuning 이 모듈은 matrix 형태로 각각 값을 나열
1 0.9 0.6 0.3 max
10 20 30 40
n_estimator
위의 hyper parameter 을 입력하는 걸 만들어서, 모든 경우에 가장 최적화된 모델을 뽑아줌.
(딥러닝에서는 grid search 하기 힘들다. 보통 randomized search / 베이지안 을 사용한다.) auto-sklearn
https://automl.github.io/auto-sklearn/master/
out of bag error
oob error estimation
bagging 실행 시 bag 에 미포함 데이터로 성능 측정 validation set 처리하는 방법과 유사
grid.best_estimator_.oob_score_
// random forest //
간단하면서도 좋은 성능
correlation 낮은 m 개의 subset data 로 학습,
split 시 검토 대상 feature 를 random 하게 n개 선정
ex) 10 개 중에 7개만 쓰고 이 중 모호성 줄이는 걸 split 으로
전체 feature 가 p 이면 n=p 이면 bagging tree
feature 의 재사용 가능, n은 root p 또는 p/3
variance 가 높은 트리 -> last node 1~5
즉 bagging 과 decision tree 가 합쳐진 것인데, 모든 feature 를 보는게 아니라 n개만 본다.
이 n을 정하는 방법은 아래와 같음
sklearn.ensemble.RandomForestClassifier 에서 max_features 에 대해서 정리하기
auto (sqrt(n_features)) / sqrt / log2/ None (n_features)
//// time series ////
시간에 특화된 기능이 필요 (시계열 데이터)
python datetime 모듈 말고도 pendulum 이 더 쉽게 됨
python datetime module 도 좋긴 함
datetime 이면 to_datetime 으로 변환해주어야 함.
보통 리눅스에서는 utf-8 을 따르는데 윈도우에서는 cp949 로 인코딩되어있기 때문에
이를 잘 파악해야함.
pd.crosstab 정리하기
// bike demand //
시간과 관련된 것을 datetime 으로 변경하고 index 값으로 넣어주고
**resample** 혹은 groupby 이용하여 찾을 수 있음
resample 중요
```python
df['count'].resample('D').sum() #D/M/W/Q 는 resampling 알파벳 제공한다. (인터넷 찾아보면 됨) resampling - filter
selection 은 date_range 만들어서 사용함녀 됨.
period = pd.date_range(
start = '2011-01-01', end='2011-05-31', freq='M')
df['count'].resample('D').sum()[period]// time shifting //
shift 2 를 먹혀준다 .shift(periods=2, fill_value=0) -> 2칸 씩 옮겨 간것
// moving avergae // 시계열 데이터는 노이즈 발생 -> 노이즈 줄이면서 추세를 보기 위한 이동 평균법
-
rolling expand 30일 기준으로 (1/1 ~ 1/31) 까지 데이터를 평균낸다.
-
secondary y
// predictions //
data sampling for timeseries dataset 테이터 특징에 따라 기존 데이터와 다른 샘플링 방법 사용 nested corss validation 의 평균 성능 측정이 일반적 계절성이 나타나는 경우는 시간축에서 쪼갠다. 데이트 타임의 period 를 들어가서 그걸 잘라서 예측
sMAPE 를 많이 사용
사용 가능한 모델 stats.model ARIMA https://bit.ly/3gv9ZZx Facekbook의 prophet https://bit.ly/3huWKsS 전처리 후 regression 문제처럼 interpretable DL for time series (N-beats : neural basis expansion analysis for interpretable time series forecasting)
id 값을 meta data 로 쓸때는 임베딩 기법을 사용 (딥러닝)
https://github.com/blissray/s-python/tree/master/day3/imbalanced_dataset 하나의 y값이 존재하는 것과 달리 page 마다 y 값을 예측할 필요가 있음
object
/ 4일차/
imbalanced data
보통 트레이닝 data 는 F:T = 5:5 로 비율을 최대한 맞추고 test data 는 original data set 의 비율을 그대로 맞추자.
dataset resampling imbalanced class 가 충분히 많으면 under sampling -> false 데이터를 줄임 부족하다면 over sampling -> true 데이터를 늘림 데이터를 늘리는게 좋은 방식 gpt? 로 텍스트 augmentation 가능
딥러닝에서는 데이터 임베딩 가능 scikit learn 의 imbalanced dataset 확장 모듈 SMOTE 는잘 안됨.
/ under sampling/
random - 가장 작은 class 를 기준으로 random 하게 선택 Nearmiss - heuristics based on NN algorithm AIIKNN - 자기 class 내에서 가장 가까운 데이터만 남김 Instance hardness threshold : 모델을 사용해서 해당 모델이 나오는 확률 (predict_proba) 기반으로 sample 선택
/ over sampling / random - 현재 가능한 데이터 일부를 복사
/ Performance matrixs / f1 말고도 많이 쓰는게 ROC curve (Receiver Operating Characteristics)
잘 틀린거랑 잘 맞춘거의 비율?
lh 공사에서 하는 compas 라는 거
how to handle imbalanced dataset 데이터를 늘려라 ! 앙상블과 알고리즘의 고도화가 할만하다
melt 를 쓰자
data 시각화 !
- CC
- DD
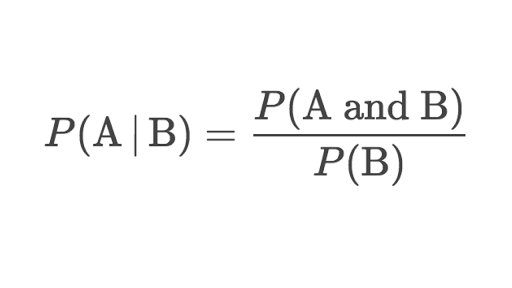
One hot 으로 먼저 바꿔줘야 한다.
np.where(Y_data==True) # Y_data 가 True 인 값의 index 가 return sklearn.naive_bayes.BernoulliNB NB 에서 0 또는 1로 ,,
-
Multinomial Naive Bayes X 값이 Binary 가 아니라 1 이상의 값을 가지느 ㄴ문제
-
Bag of words 단어별로 인덱스를 부여해서 한 문장의 단어 개수를 vector 로 표현
-
Multinomial naive bayes 식계산 방식이 다름
분모 : 특정 문서가 몇번 나왔는가 + smoothing value
- count vectorizer..
vector 화 시키는 방법은 다양한데, sklearn 을 이용하자. stop word 등등 text data 일때도
/ processing
- data prepare 데이터 로딩 / tagging
- 전처리 cleansing / tokenization 띄어쓰기로 자른다. / stopword 제거 / stemming
- vectorizer hyper parameter (Ngrams Threadshodl, TF-IDF or Bag of words) bag of words 단점은 단어가 많이 출현했는데 그게 진짜 중요한 건지 아닌지 다르다. data 가 크면 bert 를 쓰는게,, log data 는 TF-IDF 도 괜찮다.
multinominal 이랑 logistic regression 만 쓸 수 있다. text 데이터 이므로
sklearn 의 pipeline 이용하기 fit(X, y) 에서 변환된걸 fit 하고 ... 예측하고 ..
- 설치 conda install -c conda-forge fasttext conda install -c conda-forge transformers
pip install --upgrade gensim pip install -U spacy python -m spacy download en python -m spacy download en_core_web_lg python -m spacy validate
https://datascienceschool.net/view-notebook/3e7aadbf88ed4f0d87a76f9ddc925d69/ 이 내용 정리하기https://chan-lab.tistory.com/27
- CC
- DD
- CC
- DD
2020.10.03
The 5 clustering algorithms data scientists need to know
clustering ? data point set 을 기준으로 비지도적으로 분류하기 위한 것. 같은 group 에 속한 data points 는 특징과 비슷한 속성을 갖고 있음. 다른 group 에 속한 data points 와는 비슷하지 않는 특징 속성 가져야 한다. https://michigusa-nlp.tistory.com/27 https://ratsgo.github.io/machine%20learning/2017/04/16/clustering/
https://astralworld58.tistory.com/58
- K-means clustering
2021.08.10
tsne : https://lovit.github.io/nlp/representation/2018/09/28/tsne/