Hyper Parameter Tuning with Cross Validation - jaeaehkim/trading_system_beta GitHub Wiki
Motivation
- Train data에 대해 Feature Selection을 마치고 난 뒤에 Hyper Parameter Tuning은 필수적인 과정이다.
- Feature가 정해지고 난 뒤 Model의 HP를 정하기 위해 CV를 통해 Metric(Score function)을 최대화 하는 Parameter로 최종 결정 짓는다. 이전에 모델을 과적합 시키지 않기 위한 많은 고민을 했으므로 HP Tuning 작업에선 최대 성능의 모델을 선택하면 된다.
- Search 방법론을 배울텐데 이것이 Meta-Label로 여러 ML 모델 혹은 Rule-based 모델로 확장되면 각 파트에 계속 적용할 수 있게 된다.
Grid Search Cross Validation
- Grid Search는 Hyper parameter로 나올 수 있는 모든 경우의 수에 대해서 search 하는 방식이다. CV에선 scoring function을 각 경우마다 계산하여 ranking을 매겨 selection할 수 있다.
- 기저 데이터 구조(Underlying structure of the data)를 모르는 경우에 이를 통해 인사이트를 얻는 방식으로 활용 가능함.
- Ensemble-Methods, Cross-Validataion-in-Model를 통해서 얻은 지식을 반영하여 다음과 같은 코드로 표현
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
from sklearn.ensemble import BaggingClassifier
from scipy.stats import rv_continuous, kstest
from cv import PurgedKFold
def clfHyperFit(feat, lbl, t1, pipe_clf, param_grid, cv=3, bagging=[0, None, 1.0],
rndSearchIter=0, n_jobs=-1, pctEmbargo=0, **fit_params):
if set(lbl.values) == {0, 1}:
scoring = 'f1' # f1 for meta-labeling
else:
scoring = 'neg_log_loss' # symmetric towards all classes
# 1) hyperparameter searching, on train data
inner_cv = PurgedKFold(n_splits=cv, t1=t1, pctEmbargo=pctEmbargo)
if rndSearchIter == 0:
gs = GridSearchCV(estimator=pipe_clf, param_grid=param_grid, scoring=scoring, cv=inner_cv, n_jobs=n_jobs)
else:
gs = RandomizedSearchCV(estimator=pipe_clf, param_distributions=param_grid, scoring=scoring, cv=inner_cv, n_jobs=n_jobs, n_iter=rndSearchIter)
gs = gs.fit(feat, lbl, **fit_params).best_estimator_
# 2) fit validated model on the entirety of the data
if bagging[1] > 0:
gs = BaggingClassifier(base_estimator=TheNewPipe(gs.steps), n_estimators=int(bagging[0]), max_samples=float(bagging[1]),
max_features=float(bagging[2]), n_jobs=n_jobs)
gs = gs.fit(feat, lbl, sample_weight=fit_params[gs.base_estimator.steps[-1][0] + '__sample_weight'])
gs = Pipeline([('bag', gs)])
return gs
- 코드 분석
- TheNewPipe는 Sample-Weights를 반영하기 위해 sklearn의 Pipeline을 오버라이딩
- scoring을 Meta-Labeling 방식을 쓰게 되면 좀 더 세부적으로 구별(primary model & sub model)하여 모델을 train 하기 때문에 특정 클래스로 라벨링 되어있는 표본이 대량으로 들어있는 경우가 발생하므로 'F1 Score'로 하는 것을 코드에 반영했고 전체적인 train data에 대해서 학습하는 경우는 모든 경우에 대해 동일한 정도로 예측에 관심이 있으므로 'accuracy' or 'neg log loss'를 사용하게 된다. 'neg log loss'를 쓰는 것을 추천하고 이유는 뒤에서 설명한다.
- search space는 param_grid를 통해 정의하고 GridSearchCV, RandomizedSearchCV 중 선택한 후 feat=X, lbl=y를 통해 best_estimator를 찾는다.
- sample weight를 반영하여 fit
Randomized Search Cross Validation
- 위의 코드에선 이미 Randomized Search CV가 반영되어 있다. 이것을 쓰는 이유는 Grid Search CV는 복잡해질 수록 감당할 수 없는 연산량.
- 연산량을 줄이면서 좋은 통계적 성질을 갖는 대안은 각 Hyper Parameter를 uniform distribution을 이용해서 뽑아내는 방법이고 이는 조합의 개수를 쉽게 통제할 수 있다는 측면에서 자주 사용할 수 있다. (Begstra, 2011)
Log Uniform Distribution
- 각 Hyper Parameter에 대한 리서치를 통해서 knowledge가 생긴다면 Log Uniform Distribution을 활용할 수 있다.
- 예를 들면, SVM 모델의 경우 Hyper Parameter C의 경우 0.01 ~ 1의 증가와 1 ~ 100의 증가가 비슷하게 나타나므로(로그적) 단위 별로 균등하게 뽑는 것은 비효율적이어서 이런 부분을 log 함수를 활용해서 Hyper Parameter를 tuning을 더 빠른 속도로 진행할 수 있다.
Scoring and Hyper Parameter Tuning
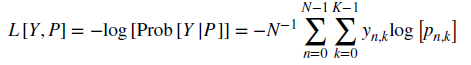
- accuracy는 높은 확률로 잘못된 매수 예측 한 경우" vs "낮은 확률로 잘못된 매수 예측 한 경우" 를 동일하게 취급
- 투자 전략이 궁극적으로 돈을 벌기 위해서는 높은 확률로 예측한 경우를 좀 더 중요하게 학습해야 한다.
- neg log loss의 경우는 p_(n,k)에 레이블 k에 대한 n번째 예측 확률이고 이것이 식에 반영되어 있다. 확률의 크기는 '포지션 크기'와 연관되어 있다.
- y_(n,k)는 레이블 1,-1의 관점에서 '방향성'의 의미가 들어가 있고 이전에 Cross-Validataion-in-Model에 cv score function을 통해 sample weight를 주고 있으므로 '수익률 크기'에 대한 요소도 학습 목표에 들어가게 된다
- y_(n,k), p_(n,k) 두 가지 요소에 여러 전처리를 통해서 '방향성', '포지션 크기', '수익률 크기'에 대한 정보를 담았고 그러므로 단순하게 accuracy를 쓰기 보다는 neg log loss를 쓰는게 '투자 전략 모델'을 만드는 관점에선 합리적이라 볼 수 있음.
Application to Quant System
- Hyper parameter tuning은 크게 3가지 파트로 나뉜다고 봄
- Train Data를 만들기 위한 과정에서의 Hyper parameter
- Bar, Event, Feature, Labeling 각각에서 많은 Hyper Parameter가 필요함
- Model 내재 Hyper Parameter
- SVM -> C, gamma
- RF -> n_estimators, max_depth, min_samples_leaf, min_weight_fraction, max_features, max_samples, max_leaf_nodes, min_impurity_decrease, class_weight, ccp_alpha
- Backtest Hyper Parameter
- bet type, bet sizing amplify, transaction fee, turn over rate, Cross Validation (k), Walk Forward update len
- Log Uniform Distribution을 확장해서 Bayesian적으로 subjective priors를 각 Hyper parameter에 맞게 반영한 분포를 이용해서 sampling 하는 방식으로 확장 가능