Motivation
- CV의 목적은 Test Data를 최대한 활용하여 ML 모델의 일반적인 오차를 알아내어 과적합을 막는 것이다. K-Fold의 경우 Test Data 구간을 여러 번 돌아가며 평가 데이터의 편중을 막아 과적합을 방지하고 여러 구간을 나누어 병렬적으로 사용하기 때문에 데이터의 분포가 IID해야 하는 특징을 가지고 있다.
- 금융에서 CV를 적용할 때 어떤 이슈가 있는 지를 연구
The Goal of Cross-Validation

- ML의 목적 : 데이터의 일반 구조를 알아내서 unseen feature를 보고 미래를 예측하고자 함
- Test Data란 부분도 Train을 시킨다면 데이터를 요약하는 능력만 증가할 뿐 예측력은 전혀 없게 됨.
- 데이터가 IID 하다는 전제 하에서 K-Fold는 ML 모델을 일반적으로 검증하기에 좋은 Tool이 됨.
- CV 정확도는 각 Fold 별의 Test Metric으로 계산하고 이때, 1/2를 넘는다면 ML Model이 무엇인가 학습했다고 간주한다.
- ML Model의 CV는 Hyper Parameter Tuning으로 사용하고 다른 하나는 Backtesting이다.
Why K-Fold CV Fails in Finance
- 모델 개발 관점: IID Process를 따른 Data를 사용하는 경우가 거의 없기 때문
- 백테스팅 관점: 백테스트의 목적인 나쁜 모델을 폐기하는 것에 쓰는 것이 아닌 모델 자체를 조정하기 위해 사용하기 때문
Information Leakage
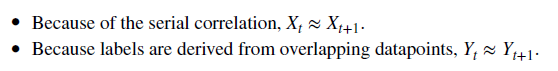
- Information Leakage는 Train 데이터가 Test 데이터에도 등장하는 정보를 포함하는 경우에 발생함. 다만, Train/Test를 물리적으론 정확하게 나누기 때문에 기술적 오류가 아니라면 이런 부분은 발생하지 않음. 다만, 계열 상관 특징에 의해 위와 같이 X_t ~ X_(t+1) , Y_t ~ Y_(t+1)인 경우에 물리적인 index의 마지막이 t까지라면 t+1이 Test로 분류되고 이는 '사실상' Inforamtion Leakage라고 볼 수 있음.
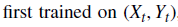
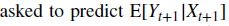
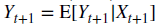 : X가 무관한 특징이라 하더라도 Expectation 값이 사실상 Y_(t+1)로 수렴하게 되는 현상이 발생하게 됨.
: X가 무관한 특징이라 하더라도 Expectation 값이 사실상 Y_(t+1)로 수렴하게 되는 현상이 발생하게 됨.
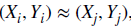
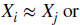
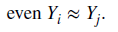
- Information Leakage로 판단하려면 (Xt,Yt) ~ (X_(t+1), Y_(t+1))이 되어야 하고 한쪽만 맞아서는 충분하지 않다.
A Solution : Purged K-Fold CV
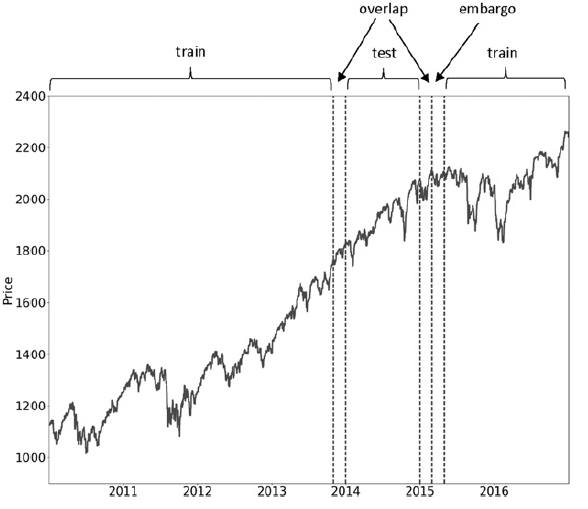
- Purging(Delete Overlap) : Train/Test 데이터의 'Label'이 중첩된 경우의 Observation을 모두 제거하는 것 > 이 부분은 Labeling으로 인한 중첩 요소 일괄적으로 제거
- Embargo : Purging을 하고 나서 부가적인 작업으로 이는 시계열 상관성 정보가 남아있게 되는 경우가 있어서 시계열 흐름 상 테스트 직후의 부분에 대해 일정 구간 보수적으로 삭제하는 행위 > 좀더 진보적으론 어디까지를 흘렀는지를 미세하게 체크해서 할 수도 있을듯.
Purging the Trainig Set
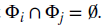
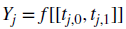
- 결국 목적은 Information Set I(Train),J(Test)간의 교집합을 없애는 것이고
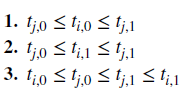
def getTrainTimes(t1, testTimes):
trn = t1.copy(deep=True)
for i, j in testTimes.iteritems():
df0 = trn[(i <= trn.index) & (trn.index <= j)].index # Train starts within test
df1 = trn[(i <= trn) & (trn <= j)].index # Train ends within test
df2 = trn[(trn.index <= i) & (j <= trn)].index # Train envelops test
trn = trn.drop(df0.union(df1).union(df2))
return trn
Embargo
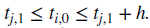
- Purge로 누수 방지 못한 경우에 사용하고 시계열 흐름의 정보가 누출된 경우만 제거하는 것이므로 Train - (1) - Test - (2) - Train일 때 (2)에 해당하는 구간에만 적용함. 구간의 길이는 임의로 정해진다. 대략적으론 작은 값 0.01T 정도로 매우 충분하다고 함.
def getEmbargoTimes(times, pctEmbargo):
step = int(times.shape[0] * pctEmbargo)
if step == 0:
mbrg = pd.Series(times, index=times)
else:
mbrg = pd.Series(times[step:], index=times[:-step])
mbrg = mbrg.append(pd.Series(times[-1], index=times[-step:]))
return mbrg
The Purged K-Fold Class
class PurgedKFold(_BaseKFold):
def __init__(self, cv_config, tl=None):
self._cv_config = cv_config
n_splits = self._cv_config.get('n_splits', 3)
pctEmbargo = self._cv_config.get('pctEmbargo', 0.)
if not isinstance(tl, pd.Series):
raise ValueError('Label Through Dates must be a pd.Series')
super().__init__(n_splits=n_splits, shuffle=False, random_state=None)
self.tl = tl
self.pctEmbargo = pctEmbargo
def split(self, X, y=None, groups=None):
if False in X.index == self.tl.index:
raise ValueError('X and ThruDateValues must have the same index')
indices = np.arange(X.shape[0])
mbrg = int(self.pctEmbargo*X.shape[0])
test_starts = [(i[0], i[-1]+1) for i in np.array_split(indices, self.n_splits)]
for i, j in test_starts:
t0 = self.tl.index[i]
test_indices = indices[i:j]
maxTlIdx = self.tl.index.searchsorted(self.tl[test_indices].max())
train_indices = self.tl.index.searchsorted(self.tl[self.tl <= t0].index)
if maxTlIdx < X.shape[0]:
train_indices = np.concatenate([train_indices, indices[maxTlIdx+mbrg:]])
yield train_indices, test_indices
- self.tl은 pd.Series로 index,value는 각각 Triple Barrier의 시작점과 끝점을 나타냄.
- PurgedKFold 클래스의 split method 분석
- mbrg는 엠바고를 적용하기 위한 길이를 미리 percentage를 이용해 길이 산출
- maxTlIdx는 purging으로 **train - (1) - test - (2) - train에서 (2)**파트의 purging 부분 idx를 계산
- train_indices를 계산하는 과정에서 위의 (1) 파트의 purging을 해버린 train_indices를 산출
- np.concatenate([train_indices, indices[maxTlIdx+mbrg:]]) 을 통해 (1),(2)의 purging, embargo를 적용한 최종 train indices를 산출
sklearn bug
def cvScore(clf, X, y, sample_weight=None, scoring='neg_log_loss', t1=None, cv=None, cvGen=None, pctEmbargo=None):
if scoring not in ['neg_log_loss', 'accuracy']:
raise Exception('Wrong scoring method')
if cvGen is None:
cvGen = PurgedKFold(n_splits=cv, t1=t1, pctEmbargo=pctEmbargo)
if sample_weight is None:
sample_weight = np.ones(len(X))
score = []
for train, test in cvGen.split(X=X):
fit = clf.fit(
X=X.iloc[train, :], y=y.iloc[train],
sample_weight=sample_weight[train]
)
if scoring == 'neg_log_loss':
prob = fit.predict_proba(X.iloc[test, :])
score_ = -log_loss(y.iloc[test], prob, sample_weight=sample_weight[test], labels=clf.classes_)
else:
pred = fit.predict(X.iloc[test, :])
score_ = accuracy_score(y.iloc[test], pred, sample_weight=sample_weight[test])
score.append(score_)
return np.array(score)
- 코드 설명
- clf.fit을 통해 따로 모델을 만들고 scoring input에 따라 predict/predict_proba와 metric function인 log_loss, accuracy_score를 활용하여 score를 따로 계산
- model을 검증할 때 주로 쓰므로 feature importance 쪽 모듈과 연계