DOC: Introduction - ibmcb/cbtool GitHub Wiki
Two viewpoints on "Cloud Performance":
-
For the “cloud user” (customer, consumer): The benefit (in the form of maximum/average achievable application performance) to cost (in the form of the price for a collection of virtual resources) ratio on a given cloud.
- What are the “relevant” applications?
- Which benefit-cost ratio (BCR) is the important one? Average? Maximum? Minimum?
- Does the BCR change over time? Is it periodic (e.g., seasonal)?
-
For the “cloud provider”: The ability to “carve out” revenue-generating entities (virtual resources) from the pool of physical resources on the infrastructure.
- How fast can new virtual resources be instantiated?
- How would the instantiation of new virtual resources impact the use of current resources (and vice-versa)?
- What would be the minimum cost (i.e., allocated physical to virtual resource ratio) that would provide the performance levels required by users?
The determination of "Cloud Performance" is inherently empirical: experiment, experiment and then experiment some more. However, such experimentation has distinctive challenges. Clouds are massively distributed computing infrastructures, requiring experiments that span a large number of elements, for a long time, with multiple repetitions to yield statistically meaningful results.
The Cloud Rapid Experimentation and Analysis Tool (a.k.a. CBTOOL) is a framework that automates IaaS cloud benchmarking through the running of controlled experiments.
An Experiment is executed by the deployment and running of a set of Virtual Applications (VApps). Experiments can be executed interactively, having the user typing commands directly on a CLI, or in batch, by having a series of commands in text format in an experiment file read by the tool.

A Virtual Application (VApp, but also called Application Instances or AIs in the framework's jargon) represents a group of VMs, with different roles, logically connected to execute different application types. For instance, a DayTrader VApp is composed by one VM with the role load driver, one VM with the role application server (either Tomcat or WAS) and one VM with the role database (either DB2 or MySQL). On other hand a Hadoop VApp is composed by one VM with the role master and N VMs with the role slave. To see a list of available VM roles, use the command rolelist on the CLI. To see a list of VApp types use the command typelist. To see a description of a particular VApp, use the command typeshow (vapp type)
Each VApp has its own load behavior, with independent load profile, load level and load duration. The values for load level and load duration can be set as random distributions (exponential, uniform, gamma, normal), fixed numbers or monotonically increasing/decreasing sequences. The load level, has a meaning that is specific to each VApp type. For instance, for a DayTrader Vapp, it represents the number of simultaneous clients on the load generator, while for Hadoop it represents the size of dataset to be sorted.
VApps can be deployed explicitly by the experimenter (using either the CLI or GUI) or implicitly through one or more VApp Submitter. A VApp Submitter deploys Vapps with a given pattern, represented by a certain inter-arrival time and a lifetime (also fixed, distributions or sequences). To see a list of available patterns, use the command patternlist on the CLI. To see a description of a particular pattern, use the command patternshow (vapp submitter pattern).
CBTOOL has a layered architecture, designed to be expandable and re-usable. All interactions with external elements (cloud environments and applications) through adapters. For instance, the ability to interact with different cloud environments can be expanded through new cloud adapters. Similarly, the deployment and performance data collection for new applications (i.e., VApp types) is also added through adapters. In both cases, adapters are self-contained, and don’t require change in the source code. The main motivation of this architecture was to enable cloud environment and application experts to develop adapters directly and incrementally.
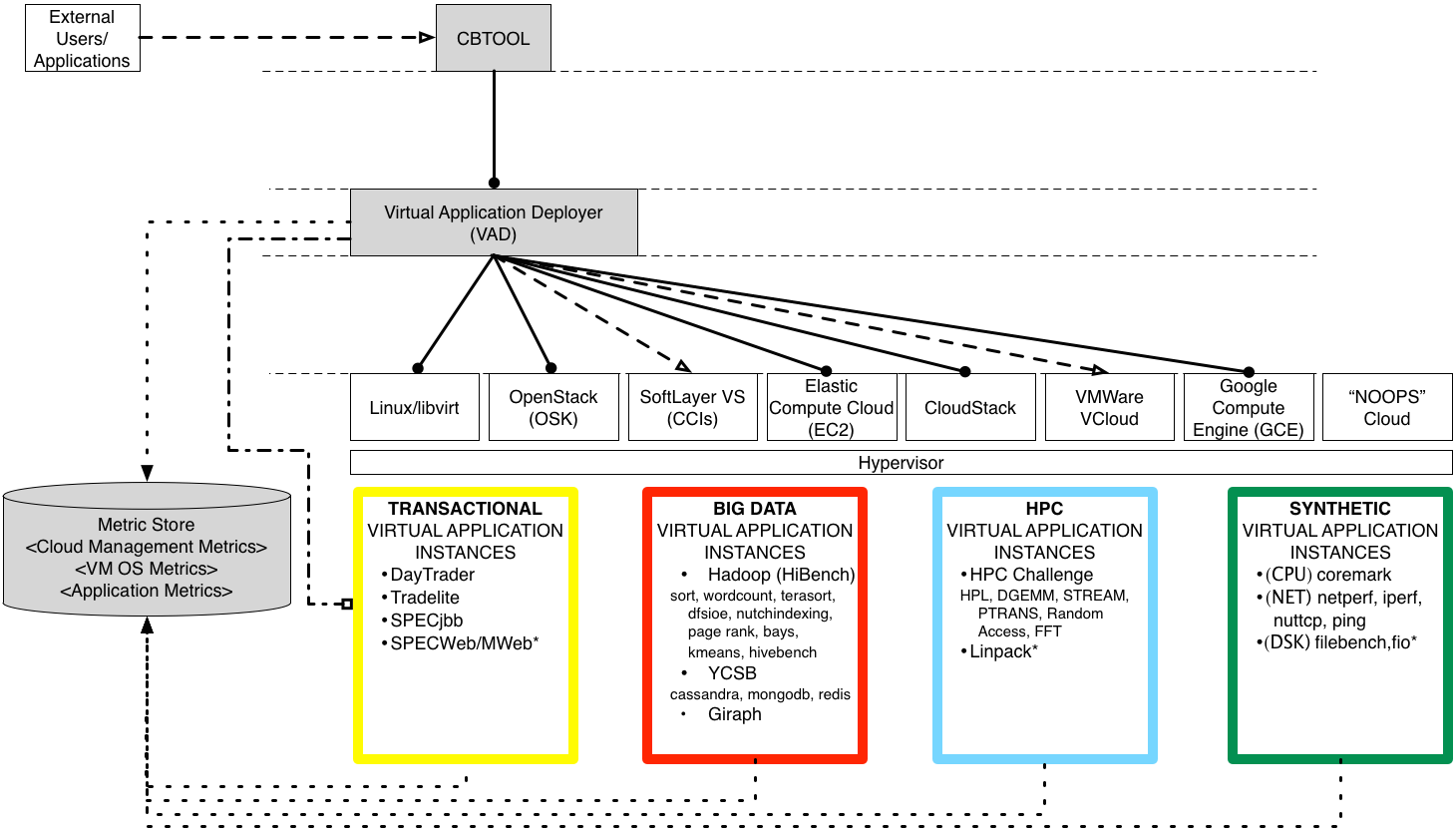
All the features and operational capabilities in the framework were designed to produce and collect metrics that are required for the determination of meaningful Figures of Merit, resulting in a cloud "report card".
| Feature\Figure of Merit | Scalability | Reliability | Stability | Efficiency | Agility |
|---|---|---|---|---|---|
| Dynamic Virtual Application Population | X | X | X | - | - |
| Provision Performance Monitoring | X | - | - | - | X |
| Application Performance Monitoring | X | - | X | X | - |
| Compute Node OS Performance Monitoring | X | - | - | X | - |
| VM image capture | - | - | - | - | X |
| Fault Injection | - | X | X | - | - |
| Virtual Application Resize | X | - | - | - | X |
The tool was written in Python (about 20K lines of code), and has only open-source dependencies. The main ones are Redis, MongoDB and Ganglia.