Билет 12 - honeycarbs/bmstu-os-6sem GitHub Wiki
Создание виртуальных файловых систем. Структура, описывающая файловую систему. Регистрация и дерегистрация файловой системе. Монтирование файловой системы. Точка монтирования. Кэширование в системе. Кэши SLAB, функции для работы с кэшем SLAB. Примеры из лабораторной работы. Функции, определенные на файлах (struct file_operations), функции, определенные на файлах, и их регистрация. Пример из лабораторной работы по файловой системе /proc.
ФС реализовывается в виде загружаемого модуля ядра. ФС становится доступной, если она подмонтирована. Функции суперблока выполняются при вызове mount, но описана также kill_sb. В ядре имеется список таких структур (поле next). В системе может существовать только один тип ФС, например, ext2. В это же время одна и та же ФС может быть подмонтирована много раз, причем к разным директориям, которые будут для нее корневыми.
struct file_system_type {
const char *name;
int fs_flags;
#define FS_REQUIRES_DEV 1
...
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
...
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
...
};Поле owner определяет кол-во ссылок на модуль. Он нужен для того, чтобы модуль не был выгружен, если ФС подмонтирована, т.к. это может привести к краху. Счетчик ссылок не 0 -выгрузить не удастся.
После объявления ФС, ее нужно зарегистрировать: register_filesystem() в функции init, unregister_filesystem() в функции exit.
Прежде чем мы сможем выполнить монтирование ФС, необходимо заполнить поля struct superblock и определить операции на суперблоке.
Монтирование файловой системы это – набор действий, в результате выполнения которых файловая система становится доступной. Когда файловая система монтируется, создается структура struct vfsmount, которая представляет конкретный экземпляр файловой системы, или, иными словами, точку монтирования. Точкой монтирования является обычная директория дерева каталогов.
После подключения файловой системы точка монтирования становится корневым каталогом смонтированной файловой системы.
Функция mount() служит для монтирования ФС, определенной конкретной структурой file_system_type, и заполнения суперблока соответствующими данными.
Когда ФС монтируется, создается структура struct vfsmount, которая представляет конкретный экземпляр ФС или, другими словами, точку монтирования.
struct vfsmount {
struct dentry *mnt_root; /* корень подмонтированного дерева */
struct super_block *mnt_sb; /* указатель на суперблок */
int mnt_flags; /*флаги монтирования*/
};Передаваемая функции mount() функция fill_super() заполняет поля структуры struct super_block. mount - команда монтирования файловой системы.
Если в системе присутствует некоторый образ диска "image", а также создан каталог, который будет являться точкой монтирования файловой системы "dir", то примонтировать файловую систему можно, используя команду:
mount -o loop -t myfs ./image ./dirПараметр -o указывает список параметров, разделенных запятыми. Одним из прогрессивных типов монтирования, является монтирование через петлевое (loop, по сути, это «псевдоустройство» (то есть устройство, которое физически не существует), которое позволяет обрабатывать файл как блочное устройство) устройство. Если петлевое устройство явно не указано в строке (а как раз параметр `-o loop' это задает), тогда mount попытается найти неиспользуемое в настоящий момент петлевое устройство и применить его.
Аргумент следующий за -t указывает тип файловой системы.
./image - это устройство. ./dir - это каталог.
umount - команда для размонтирования файловой системы:
umount ./dirЕсть dentry cach, но dentry не исчерпывает всех потребностей. В linux inode cach находится в файле fs/inode.c.
Inode cach представляет из себя:
- Глобальный хэш-массив inode_hashtable(), в котором каждый inode хэшируется по значению указателя на суперблок и номеру inode.
В случае отсутствия суперблока (inode_i_sb == NULL) вместо хэш-массива inode добавляется к двусвязному списку anon_hash_chain. Пример таких анонимных inode: сокеты, которые создаются функцией sock_alloc() (<net/socket.c>), которая вызывает функцию
get_empty_inode() из <fs/inode.c>.
-
Глобальный список inode_in_use, содержит inode, у которых i_count > 0 и i_nlink > 0. Inode-ы, созданные с помощью вызова функций get_empty_inode() и get_new_inode(), добавляются в этот список.
-
Глобальный список inode_unused, содержит правильные/допустимые inode, для которых i_count = 0.
-
Также для каждого суперблока имеется sb→dirty - список грязных inode (i_count > 0 и i_nlink > 0, но они помечены как модифицированные, т.е. как i_dirty). Такой грязный inode добавляется в список sb->dirty, если он кэширован. Это позволяет синхронизировать работу с inode.
-
Slab cache, который называется inode_cachep. Динамический (slab) кэш, в нем inode могут освобождаться, создаваться, вставляться и изыматься.
Все перечисленные списки защищены спин-локом inode_lock().
Слаб - «брусок», имеющий определенный размер. Подход был введен для OS SUN.
Идея: в ядре значительные объемы памяти выделяются на ограниченный и определенный набор объектов, таких как дескрипторы файлов, inode и т.д. При этом время для создания каждого такого объекта по меркам системы является значительным.
В результате для каждого такого объекты выполняется выделение памяти; когда объект уже становится ненужным, то выполняется освобождение объекта. При интенсивной работе в системе эти объекты постоянно создаются и освобожадются - это трата времени.
Поэтому, если такой объект был и создан и в нем на некоторое время отпала нужда, тем не менее не удалять его из памяти, то есть оставить соответствующий объем памяти, занимаемый объектом, причем оставить в проинициализированном состоянии, для того, чтобы в последующем этот проинициализированный объект использовать для объектов этого же типа.
ВНИМАНИЕ: дальше инфа не с лекций. Откопано в интернете
(инфы нет, в слаб кэше нет семафоров)
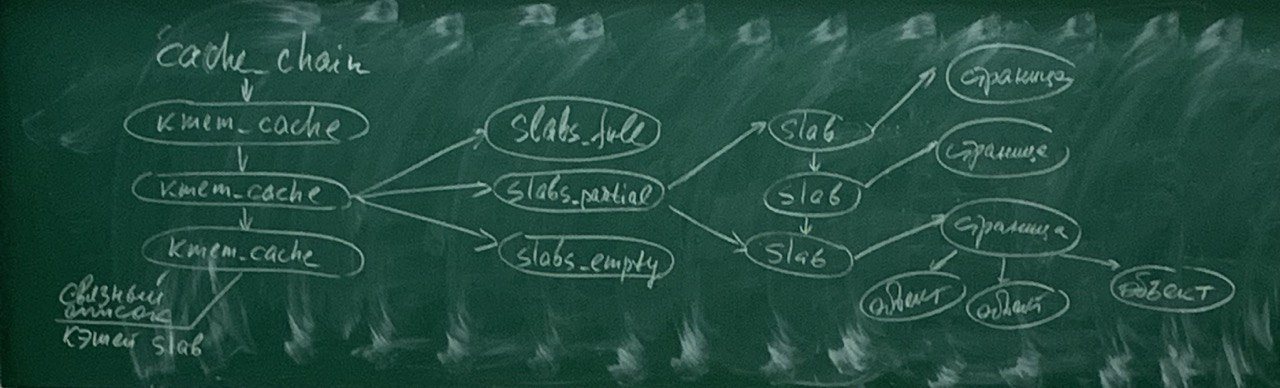
Связный список нужен для агоритма best_fit - самый подходящий, т.е. ищет кэш более всего соответстсвующий размеру нужного рапсределения.
Виды слабов:
- slab_full - распределен полностью;
- slab_partial - распределен частично;
- slab_empty - пустой, основной канд
идат на reaping(возвращение для дальнейшего использования).
Объекты - основные элементы, которые выделяются из соответствующего кэша и возвращаются в него.
В реализации слабов участки памяти, подходящие для размещения объектов данных определенного размера и типа, определяются заранее. Распределитель (аллокатор) слабов хранит информацию о размещении этих участков, которые также известны как кэш. В результате, если
возникает запрос на выделение памяти определенного размера, то он удовлетворяется быстро. Существует библиотека <linux/slab.h>. ВФС proc предоставляет информацию о слабе: cat /proc/slabinfo.
Функции для работы со слабом:
struct kmem_cache * kmem_cache_create(const char *name, unsigned int size, unsigned int align, slab_flags_t flags, void (*ctor)(void *));
void kmem_cache_destroy(struct kmem_cache *s);
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);
void kmem_cache_free(struct kmem_cache *s, void *objp);static struct kmem_cache *cache = NULL;
static int __init my_vfs_init(void){
...
if ((cache_mem_area = kmalloc(sizeof(void*), GFP_KERNEL)) == NULL)
{
printk(KERN_ERR "+ failed to allocate memory.\n");
return -ENOMEM;
}
...
return 0;
}
static void __exit my_vfs_exit(void)
{
kmem_cache_destroy(cache);
...
}Функции, определенные на файлах (struct file_operations), функции, определенные на файлах, и их регистрация. Пример из лабораторной работы по файловой системе /proc.
Для регистрации функций работы с файлами используется структура struct file_operations, чтобы назначить функции работы: open(), read(), write().
С некоторой версии ядра file_operations не поддерживается. Пример из лаб. раб. регистрации функций работы с файлами:
#if LINUX_VERSION_CODE >= KERNEL_VERSION(5,6,0)
#define HAVE_PROC_OPS
#endif
#ifdef HAVE_PROC_OPS
static struct proc_ops fileops = {
.proc_read = fortune_read,
.proc_write = fortune_write,
.proc_open = fortune_open,
.proc_release = fortune_release,
};
#else
static struct file_operations fileops = {
.owner = THIS_MODULE,
.read = fortune_read,
.write = fortune_write,
.open = fortune_open,
.release = fortune_release,
};
#endif
ssize_t fortune_write(struct file *filp, const char __user *buf, size_t count, loff_t *ppos) {
...
if (copy_from_user(&_cookie_pot[write_inx], buf, count)) {
return -EFAULT; // no space left on device
}
return count;
}
static ssize_t fortune_read(struct file *filp, char __user *buf, size_t count, loff_t *ppos) {
if (write_inx > 0) {
len = sprintf(tmp, "%s\n", &_cookie_pot[read_inx]);
copy_to_user(buf, tmp, len);
buf += len;
read_inx += len;
}
...
return len;
}