konlpy, Korpora, pytorch를 이용한 question pair 문제 풀이 - hexists/konlpy GitHub Wiki
어떤 문장이 주어졌을 때, 해당 문장이 동일한 의도인지 판단하는 것은 다양한 곳에서 필요합니다. 예를 들어 질문과 답을 주고 받는 게시판에서 동일한 의도를 파악할 수 있다면 반복되는 질문의 답변을 연결할 수 있습니다.
영어의 경우 동일한 질문들을 모아놓은 Quora Question Pairs 말뭉치가 있습니다(다른 말뭉치도 많이 있습니다). Kaggle에서는 해당 말뭉치를 이용하여 이 문제를 다양한 방법으로 해결하고 있습니다.
한국어의 경우 적은양이지만 question pair 말뭉치가 있습니다. 일상 주제들의 문장들로 약 1만개의 데이터를 사용할 수 있습니다.
본 글에서는 한국어 question pair 말뭉치를 이용하여 동일 의도 문장 찾기 문제를 풀어봅니다. konlpy를 이용하여 형태소 분석을 하고, korpora에서 question pair 말뭉치를 다운 받습니다. 그리고, pytorch를 이용하여 Manhattan LSTM으로 siamese network를 구현합니다.
글에서 다루는 내용입니다.
- 문제 설명
- konlpy
- korpora
- pytorch
- question par 문제 풀이
question pair 말뭉치는 같은 질문인지 다른 질문이지 분류되어 있는 말뭉치입니다. 예를 들면, 아래의 질문은 같은 의도의 질문으로 볼 수 있습니다.
다른 생각하지 않고 공부하는 방법
잡념 없이 공부하는 방법
대표적인 한국어 자연어처리 분석도구입니다. kkma, okt, mecab 등 여러가지 형태소 분석기들을 제공하고 있습니다. python으로 손쉽게 설치하고 사용할 수 있습니다.

연구 목적으로 공유된 말뭉치들을 다운로드 받고, 사용할 수 있도록 기능을 제공합니다. 현재(2020.10.13)는 10개의 말뭉치를 다운로드 받을 수 있습니다.
지속적으로 데이터가 추가되고 있어 Korpora의 활용도가 점점 높아질 것 같습니다.
대표적인 딥러닝 도구로 python을 다룰 수 있다면 용이하게 사용할 수 있습니다.
물론 딥러닝에 대한 기초지식은 공부가 필요합니다.
문제를 풀기 위해서, Quora Question Pairs 문제를 해결한 블로그를 참고했습니다.
Manhattan Lstm Model을 사용하여 두 문장이 같은 의도를 가졌는지 판단합니다. 이 모델은 같은 LSTM을 사용하여 두 문장의 마지막 hidden을 구하고, manhattan distance로 유사도를 계산합니다. 두 문장을 학습시키는 lstm은 하나의 lstm을 공유하여 사용합니다.
참고: Siamese Recurrent Architectures for Learning Sentence Similarity
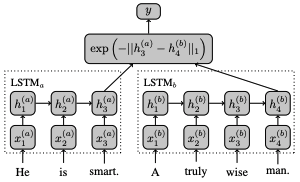
문제 해결은 아래 순서대로 진행했습니다.
전체 코드가 필요한 분은 github을 참고하시면 됩니다.
1) korpora 설치
2) konlpy 설치(mecab 설치)
3) pytorch 설치
4) step by step
1~3) 과정은 아래 명령으로 한번에 설치가 가능합니다.
다른 실험 환경과 충돌 될 수 있으니, pyenv, virtualenv 등을 사용하여 별도의 실험 환경을 구성 후 실행하는 것이 좋습니다.
requirements.txt : github
$ pip install -r requirements.txt
Korpora를 설치합니다. Kopora를 이용해서 Question Pair 말뭉치를 다운 받습니다.
$ pip install Korpora
설치가 잘 됐는지 테스트를 진행합니다.
question pair 말뭉치를 로드해서 일부를 출력하는 예제입니다.
$ python3
>>> from Korpora import Korpora, QuestionPairKorpus
>>> question_pair = Korpora.load('question_pair')
Korpora 는 다른 분들이 연구 목적으로 공유해주신 말뭉치들을
손쉽게 다운로드, 사용할 수 있는 기능만을 제공합니다.
말뭉치들을 공유해 주신 분들에게 감사드리며, 각 말뭉치 별 설명과 라이센스를 공유 드립니다.
해당 말뭉치에 대해 자세히 알고 싶으신 분은 아래의 description 을 참고,
해당 말뭉치를 연구/상용의 목적으로 이용하실 때에는 아래의 라이센스를 참고해 주시기 바랍니다.
# Description
Author : songys@github
Repository : https://github.com/songys/Question_pair
References :
질문쌍(Paired Question v.2)
짝 지어진 두 개의 질문이 같은 질문인지 다른 질문인지 핸드 레이블을 달아둔 데이터
사랑, 이별, 또는 일상과 같은 주제로 도메인 특정적이지 않음
# License
Creative Commons Attribution-ShareAlike license (CC BY-SA 4.0)
Details in https://creativecommons.org/licenses/by-sa/4.0/
>>> print(question_pair.train[0])
LabeledSentencePair(text='1000일 만난 여자친구와 이별', pair='10년 연예의끝', label='1')
>>> print(question_pair.train[0].text)
1000일 만난 여자친구와 이별
>>> print(question_pair.train[0].pair)
10년 연예의끝
>>> print(question_pair.train[0].label)
1
konlpy를 설치합니다. konlpy의 mecab 형태소 분석기를 사용하기 위해, mecab도 함께 실행합니다.
$ pip install konlpy
$ bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
형태소 분석기가 잘 설치됐는지는 테스트 해봅니다.
$ python3
>>> from konlpy.tag import Mecab
>>> mecab = Mecab()
>>> print(mecab.pos('가을 하늘 공활한데 높고 구름 없이'))
[('가을', 'NNG'), ('하늘', 'NNG'), ('공활', 'XR'), ('한', 'XSA+ETM'), ('데', 'NNB'), ('높', 'VA'), ('고', 'EC'), ('
구름', 'NNG'), ('없이', 'MAG')]
pytorch는 최신 버전인 1.6.0을 사용합니다. torch, torchtext, tensorboard를 함께 설치합니다.
본 글에는 torch cpu 버전을 설치합니다. gpu 버전 설치가 필요한 경우, pytorch 공식 문서를 참고하면 됩니다.
$ pip install torch torchtext tensorboard
여기서부터는 실제로 문제 푸는 과정에 대한 설명입니다. 처음 접하는 분들도 따라하기 편하도록 step별로 정리했습니다.
실행시 사용되는 기본 패키지를 로드합니다.
import os
import sys
from pprint import pprint
Korpora에서 question pair corpus를 불러옵니다.
from Korpora import Korpora
question_pair = Korpora.load('question_pair')
불러온 corpus를 형태소 분석합니다.
형태소 분석은 konlpy mecab을 이용합니다.
konlpy의 mecab을 불러오고 초기화합니다.
from konlpy.tag import Mecab
mecab = Mecab()
형태소 분석은 Korpora를 통해 불러온 question pair 데이터를 대상으로 합니다.
analyze_question_pairs() 함수를 정의하고 train, test에 대해서 형태소 분석을 합니다. 형태소 분석 결과 중 형태소 부분을 사용합니다.
question_pairs 데이터는 train, test 데이터를 제공하고 있습니다.
데이터는 LabeldSetencePair Object로 제공되며, text, pair, label이 있습니다.
# LabeledSentencePair(text='1000일 만난 여자친구와 이별', pair='10년 연예의끝', label='1')
def get_morph_tag(text):
morphs, tags = [], []
for morph, tag in mecab.pos(text):
morphs.append(morph)
tags.append(tag)
return morphs, tags
def analyze_question_pairs(question_pairs):
anal_question_pairs = []
for qp in question_pairs:
# print('text = {}'.format(qp.text))
# print('pair = {}'.format(qp.pair))
# print('label = {}'.format(qp.label))
text_morph, _ = get_morph_tag(qp.text)
pair_morph, _ = get_morph_tag(qp.pair)
anal_question_pairs.append((qp.text, qp.pair, qp.label, text_morph, pair_morph))
# pprint(anal_question_pairs)
return anal_question_pairs
train = analyze_question_pairs(question_pair.train)
test = analyze_question_pairs(question_pair.test)
train 데이터를 이용하여 vocab을 만듭니다.
<pad>, <unk>에 대해서는 index를 미리 지정합니다.
vocab2idx = {'<pad>': 0, '<unk>': 1}
idx2vocab = ['<pad>', '<unk>']
for _, _, _, text_morph, pair_morph in train:
for morph in text_morph:
if morph not in vocab2idx:
vocab2idx[morph] = len(idx2vocab)
idx2vocab.append(morph)
print('vocab2idx = {}'.format(len(vocab2idx)))
print('idx2vocab = {}'.format(idx2vocab[:10]))
print()
torch에서 사용할 패키지들을 로드합니다.
import torch
import torch.utils.data as data_utils
import torch.nn.utils.rnn as rnn
import numpy as np
pytorch에서는 reproductivity를 위해 가이드를 제공합니다. 실험시 랜덤으로 변하는 변수들을 고정하여 동일한 환경에서 실험할 수 있도록 합니다.
import random
random_seed = 111
torch.manual_seed(random_seed)
torch.cuda.manual_seed(random_seed)
torch.cuda.manual_seed_all(random_seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(random_seed)
random.seed(random_seed)
Custom Dataset을 생성합니다.
Map-style datasets 형태로,
__init__()에서 데이터를 로드하고,
__getitem__()에서는 index에 따라 데이터를 반환할 수 있도록 하고,
__len__()에서는 데이터의 크기를 반환하게 합니다.
class CustomDataset(torch.utils.data.Dataset):
def __init__(self)):
def __getitem__(self, index):
def __len__(self,):
Dataset에서는 앞서 생성한 vocab과 미리 로드한 train, test를 이용하여 data를 index로 변환합니다.
text2idx() 함수를 통해 text_morph, pair_morph 데이터를 변환하고, test 데이터의 경우 vocab에 단어가 없는 경우 를 할당합니다.
class QuestionPairDataset(torch.utils.data.Dataset):
def __init__(self, vocab2idx, data):
self.vocab2idx = vocab2idx
self.data = self.text2idx(data)
def text2idx(self, pairs):
# train, test 데이터를 index형태로 변환합니다.
# text_morph, pair_morph에 대해 index로 변환하고, 다른 데이터는 그대로 유지합니다.
question_pairs = []
for text, pair, label, text_morph, pair_morph in pairs:
text_idx, pair_idx = [], []
for morph in text_morph:
idx = self.vocab2idx[morph] if morph in self.vocab2idx else self.vocab2idx['<unk>']
text_idx.append(idx)
for morph in pair_morph:
idx = self.vocab2idx[morph] if morph in self.vocab2idx else self.vocab2idx['<unk>']
pair_idx.append(idx)
text_idx = torch.LongTensor(text_idx)
pair_idx = torch.LongTensor(pair_idx)
# label = torch.FloatTensor(float(label))
label = torch.as_tensor(float(label))
question_pairs.append((text, pair, label, text_idx, pair_idx))
# pprint(question_pairs)
return question_pairs
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
text, pair, label, text_idx, pair_idx = self.data[idx]
text_len, pair_len = len(text_idx), len(pair_idx)
return text, pair, text_idx, pair_idx, label, text_len, pair_len
train_dataset = QuestionPairDataset(vocab2idx, train)
test_dataset = QuestionPairDataset(vocab2idx, test)
validation data의 경우 train 데이터를 train:valid = 8:2로 나눠 사용합니다.
valid_len = int(len(train_dataset) * 0.2)
train_dataset, valid_dataset = data_utils.random_split(train_dataset, (len(train_dataset) - valid_len, valid_len))
dataloader를 통해 custom dataset을 사용할 때, collate_fn에서 사용할 batch sampler를 만듭니다.
본 실험에서는 lstm을 사용하는데, batch 단위 실행을 위해 sample의 max length를 기준으로 padding이 필요합니다.
이를 위해 batch sampler function을 별도로 지정합니다.
def make_batch(samples):
text, pair, text_idx, pair_idx, label, text_len, pair_len = list(zip(*samples))
text_len = torch.LongTensor(text_len)
pair_len = torch.LongTensor(pair_len)
padded_text_idx = rnn.pad_sequence(text_idx, batch_first=True, padding_value=0)
padded_pair_idx = rnn.pad_sequence(pair_idx, batch_first=True, padding_value=0)
batch = [
text,
pair,
padded_text_idx.contiguous(),
padded_pair_idx.contiguous(),
torch.stack(label).contiguous(),
text_len,
pair_len
]
return batch
batch_size = 64
train_loader = data_utils.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, collate_fn=make_batch)
valid_loader = data_utils.DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, collate_fn=make_batch)
test_loader = data_utils.DataLoader(test_dataset, batch_size=1, shuffle=False, collate_fn=make_batch)
# for i, vals in enumerate(train_loader):
# print(vals)
custom model을 생성합니다.
custom model은 __init__(), forward() 함수를 정의해야 합니다.
__init__()에서는 model 선언을 하고, forward()에서는 실행했을 때의 동작을 지정합니다.
class CustomModel(nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
def forward(self):
Mahanttan LSTM을 위해 __init__()에서는 Embedding Matrix 와 LSTM 모델을 선언합니다.
nn.Embedding을 통해 입력된 vocab의 embedding을 계산하고,
LSTM은 bidirectional lstm을 사용하기 위해 bidirectional=True를 설정합니다.
class TextSiamese(nn.Module):
def __init__(self, hidden_size, vocab_size):
super(TextSiamese, self).__init__()
...
self.embeddings = nn.Embedding(self.vocab_size, self.embed_size, padding_idx=0)
self.shared_lstm = nn.LSTM(self.embed_size, self.hidden_size, num_layers=self.num_layers, batch_first=True, bidirectional=True)
forward()는 아래 순서로 진행됩니다.
1) Embedding Matrix Lookup
2) packed sequence
3) biLSTM
4) biLSTM Hidden Concat(forward + backward)
5) Mahattan Distance 계산
- Embedding Matrix Lookup
- packed sequence
입력된 index에 대해 init에서 선언한 embedding에 넣어 embedding 값을 구합니다.
그리고, packed sequence 형태로 변환합니다. packed sequence는 lstm에서 batch 단위 학습시, <pad> 전까지만 학습하게 하는 기능입니다.
자세한 설명은 링크에 있습니다.
def input2packed_embed(self, inp, inp_len):
embed = self.embeddings(inp) # (Batch size, Max length, Embedding size)
packed_embed = pack_padded_sequence(embed, inp_len, batch_first=True, enforce_sorted=False)
return packed_embed
pack_text = self.input2packed_embed(text, text_len)
pack_pair = self.input2packed_embed(pair, pair_len)
- biLSTM
두 문장을 각각 shared_lstm에 입력하고 last hidden을 계산합니다.
# use zero init hidden, cell_state
_, (text_hidden, text_cell_state) = self.shared_lstm(pack_text, None)
_, (pair_hidden, pair_cell_state) = self.shared_lstm(pack_pair, None)
- biLSTM Hidden Concat(forward + backward)
bidirectional의 output hidden을 분리하고, 이를 concat 합니다.
자세한 설명은 링크에 있습니다.
# (num_layers, num_directions, batch, hidden_size) => (num_directions, batch, hidden_size) => (num_directions, batch, hidden_size * 2)
if self.bidirectional is True:
text_hidden = text_hidden.view(self.num_layers, self.direction, batch_size, self.hidden_size) # (num_layers, num_directions, batch, hidden_size)
text_hidden = torch.cat((text_hidden[:, 0], text_hidden[:, 1]), -1) # (num_directions, batch, hidden_size) => (num_directions, batch, hidden_size * 2)
pair_hidden = pair_hidden.view(self.num_layers, self.direction, batch_size, self.hidden_size)
pair_hidden = torch.cat((pair_hidden[:, 0], pair_hidden[:, 1]), -1)
- Mahattan Distance 계산
마지막으로 manhattan distance를 계산합니다. text, pair hidden을 입력받아 distance를 구합니다.
def exponent_neg_manhattan_distance(self, x1, x2):
''' Helper function for the similarity estimate of the LSTMs outputs '''
return torch.exp(-torch.sum(torch.abs(x1 - x2), dim=1)) # (batch_size)
distance = self.exponent_neg_manhattan_distance(text_hidden.permute(1, 2, 0).view(batch_size, -1), pair_hidden.permute(1, 2, 0).view(batch_size, -1)) # (batch_size, hidden_size)
모델 전체 코드입니다.
import torch.nn as nn
from torch.nn.utils.rnn import pack_padded_sequence
from torch import optim
from torch.utils.tensorboard import SummaryWriter
class TextSiamese(nn.Module):
def __init__(self, hidden_size, vocab_size):
super(TextSiamese, self).__init__()
self.embed_size = 300
self.num_layers = 1
self.bidirectional = True
self.direction = 2 if self.bidirectional else 1
self.hidden_size = hidden_size
self.vocab_size = vocab_size
self.embeddings = nn.Embedding(self.vocab_size, self.embed_size, padding_idx=0)
self.shared_lstm = nn.LSTM(self.embed_size, self.hidden_size, num_layers=self.num_layers, batch_first=True, bidirectional=self.bidirectional)
def forward(self, text, pair, text_len, pair_len):
pack_text = self.input2packed_embed(text, text_len)
pack_pair = self.input2packed_embed(pair, pair_len)
batch_size = text.size()[0]
# use zero init hidden, cell_state
_, (text_hidden, text_cell_state) = self.shared_lstm(pack_text, None)
_, (pair_hidden, pair_cell_state) = self.shared_lstm(pack_pair, None)
if self.bidirectional is True:
text_hidden = text_hidden.view(self.num_layers, self.direction, batch_size, self.hidden_size) # (num_layers, num_directions, batch, hidden_size)
text_hidden = torch.cat((text_hidden[:, 0], text_hidden[:, 1]), -1) # (num_directions, batch, hidden_size) => (num_directions, batch, hidden_size * 2)
pair_hidden = pair_hidden.view(self.num_layers, self.direction, batch_size, self.hidden_size)
pair_hidden = torch.cat((pair_hidden[:, 0], pair_hidden[:, 1]), -1)
distance = self.exponent_neg_manhattan_distance(text_hidden.permute(1, 2, 0).view(batch_size, -1), pair_hidden.permute(1, 2, 0).view(batch_size, -1)) # (batch_size, hidden_size)
return distance
def input2packed_embed(self, inp, inp_len):
embed = self.embeddings(inp) # (Batch size, Max length, Embedding size)
packed_embed = pack_padded_sequence(embed, inp_len, batch_first=True, enforce_sorted=False)
return packed_embed
def exponent_neg_manhattan_distance(self, x1, x2):
''' Helper function for the similarity estimate of the LSTMs outputs '''
return torch.exp(-torch.sum(torch.abs(x1 - x2), dim=1)) # (batch_size)
model 학습 과정입니다.
model을 선언하고,
optimizer를 선언하고,
loss function을 선언합니다.
그리고, 진행사항을 보기 좋게 표시할 progress bar 설정, acc 계산을 위한 binary_acc 함수를 정의합니다.
model = TextSiamese(hidden_size, len(vocab2idx))
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_func = nn.MSELoss()
progress bar 설정
def print_progress(msg, progress):
max_progress = int((progress*100)/2)
remain=50-max_progress
buff="{}\t[".format( msg )
for i in range( max_progress ): buff+="⬛"
buff+="⬜"*remain
buff+="]:{:.2f}%\r".format( progress*100 )
sys.stderr.write(buff)
binary acc 계산
def binary_acc(y_pred, y_test):
y_pred_tag = torch.round(y_pred)
correct_results_sum = (y_pred_tag == y_test).sum().float()
acc = correct_results_sum/y_test.shape[0]
acc = torch.round(acc * 100)
return acc
학습은 num_iters를 통해 지정한 횟수만큼 수행합니다.
학습시에는 model.train()을 통해 학습되도록 하고,
validation시에는 with torch.no_grad(), model.eval()을 통해 평가합니다.
for epoch in range(1, num_iters + 1):
# train
model.train()
for i, vals in enumerate(train_loader):
....
model.zero_grad()
scores = model(text_idx, pair_idx, text_len, pair_len)
loss.backward()
optimizer.step()
....
# valid
with torch.no_grad():
model.eval()
va_losses, va_accs = [], []
for i, vals in enumerate(valid_loader):
....
scores = model(text_idx, pair_idx, text_len, pair_len)
....
추가로 tensorboard에 학습과 validation 그래프를 출력합니다.
SummaryWriter를 지정하고, 이를 통해 tensorboard graph를 추가할 수 있습니다.
writer = SummaryWriter(file_name)
model 실행 전체 코드입니다.
hidden_size = 50
learning_rate = 0.001
num_iters = 1000
model = TextSiamese(hidden_size, len(vocab2idx))
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
loss_func = nn.MSELoss()
def print_progress(msg, progress):
max_progress = int((progress*100)/2)
remain=50-max_progress
buff="{}\t[".format( msg )
for i in range( max_progress ): buff+="⬛"
buff+="⬜"*remain
buff+="]:{:.2f}%\r".format( progress*100 )
sys.stderr.write(buff)
def binary_acc(y_pred, y_test):
y_pred_tag = torch.round(y_pred)
correct_results_sum = (y_pred_tag == y_test).sum().float()
acc = correct_results_sum/y_test.shape[0]
acc = torch.round(acc * 100)
return acc
from datetime import datetime
date_time = datetime.now().strftime('%Y%m%d%H%M')
writer = SummaryWriter('./runs/{}'.format(date_time))
for epoch in range(1, num_iters + 1):
model.train()
tr_losses, tr_accs = [], []
# train
for i, vals in enumerate(train_loader):
text, pair, text_idx, pair_idx, label, text_len, pair_len = vals
model.zero_grad()
scores = model(text_idx, pair_idx, text_len, pair_len)
loss = loss_func(scores, label)
acc = binary_acc(scores, label)
tr_losses.append(loss.item())
tr_accs.append(acc.item())
loss.backward()
optimizer.step()
progress = (i + 1) / float(len(train_loader))
print_progress('train', progress)
print(file=sys.stderr)
with torch.no_grad():
model.eval()
va_losses, va_accs = [], []
for i, vals in enumerate(valid_loader):
text, pair, text_idx, pair_idx, label, text_len, pair_len = vals
scores = model(text_idx, pair_idx, text_len, pair_len)
loss = loss_func(scores, label)
acc = binary_acc(scores, label)
va_losses.append(loss.item())
va_accs.append(acc.item())
progress = (i + 1) / float(len(valid_loader))
print_progress('valid', progress)
print(file=sys.stderr)
print('text : {}'.format(text[-1]), file=sys.stderr)
print('pair : {}'.format(pair[-1]), file=sys.stderr)
print('label = {:.4f}, score = {:.4f}'.format(label[-1].item(), scores[-1].item()), file=sys.stderr)
tr_loss, tr_acc = np.mean(tr_losses), np.mean(tr_accs)
va_loss, va_acc = np.mean(va_losses), np.mean(va_accs)
print("{} / {}\ttrain loss : {:.4f}, train acc: {:.4f}, valid loss: {:.4f} valid acc: {:.4f}\n".format(epoch, num_iters, tr_loss, tr_acc, va_loss, va_acc), file=sys.stderr)
writer.add_scalar('{}/{}'.format('loss', 'train'), tr_loss, epoch)
writer.add_scalar('{}/{}'.format('acc', 'train'), tr_acc, epoch)
writer.add_scalar('{}/{}'.format('loss', 'valid'), va_loss, epoch)
writer.add_scalar('{}/{}'.format('acc', 'valid'), va_acc, epoch)
writer.close()
마지막으로 학습이 완료된 모델을 이용한 test 데이터에 대한 평가입니다.
batch size를 1개로 지정하여 가 붙지 않도록 했고, pred_label과 label이 일치할 때 정답을 맞춘 경우입니다.
print(file=sys.stderr)
with torch.no_grad():
model.eval()
cor_count, fp = 0, open('log.{}'.format(date_time), 'w')
fp.writelines('{}\t{}\t{}\t{}\t{}\n'.format('T/F', 'LABEL', 'PRED', 'TEXT', 'PAIR'))
for i, vals in enumerate(test_loader):
text, pair, text_idx, pair_idx, label, text_len, pair_len = vals
scores = model(text_idx, pair_idx, text_len, pair_len)
pred_label = torch.round(scores)
if pred_label == label:
cor_count += 1
fp.writelines('{}\t{}\t{}\t{}\t{}\n'.format((pred_label == label)[0].item(), label[0].item(), pred_label[0].item(), text[0], pair[0]))
progress = (i + 1) / float(len(test_loader))
print_progress('test', progress)
te_acc = cor_count / i
print("\ntest acc: {:.4f}".format(te_acc), file=sys.stderr)
fp.close()
- step by step 과정을 통해 전체 과정을 실행하면, 총 175분의 시간이 소요됩니다(PC 사양에 따라 달라질 수 있습니다).
학습 그래프를 보면, train과 valid 학습이 잘 되는 것을 볼 수 있습니다. 하지만, 성능은 매우 안 좋습니다.
추측하기로는 학습 데이터가 충분치 않고, 말뭉치가 일상 주제들로 이뤄져 있어 동일 의도를 판단하는데 어려움이 있는 것 같습니다.
또한, 학습에 사용한 형태소 임베딩이 문장의 의미 정보를 충분히 임베딩하지 못했을 수도 있습니다.
마지막으로 LSTM 모델의 한계로 긴 문장에 대해 제대로 임베딩을 못했을 수 있습니다.
| 구분 | accuracy(%) |
|---|---|
| train | 84% |
| valid | 60.5% |
| test | 53.5% |
- 학습 그래프

- 실행 완료 상태

본 글에서는 konlpy + Korpora + pytorch를 이용한 question pair 문제 풀이를 해봤습니다.
konlpy의 mecab 사용 방법, Korpora에서 question pair를 다운 받는 방법 그리고 pytorch로 Mahattan LSTM 모델을 구현하고 실행하는 방법에 대해 다뤘습니다.
성능을 보면 매우 부족하지만, question pair 문제를 어떻게 해결할 수 있는지 조금이나마 도움이 되는 글이였으면 좋겠습니다.
감사합니다.