The MTHv2 Dataset - hcts-hra/ecpo-fulltext-experiments GitHub Wiki
As the grid-based approach described later will only work for a fraction of the Jingbao, we employ neural methods for character segmentation as well. We will rely on the readily trained HRCenterNet. In order to make it out-of-the-box usable for the Jingbao, we have to make sure the size ratio between input image and character bounding boxes match. The HRCenterNet was trained on the MTHv2 Dataset, were random crops of 500×500 px were used as input for the first layer. Consequently, the to-be-OCR'ed image segments of the Jingbao will have to be passed to the model in square tiles, too.
By determining the approximate bounding box size of the characters in the training images (i.e. the MTHv2 dataset), we can find out the most suitable tile size for the Jingbao. Below is a histogram of the heights and widths occuring in the 1,077,632 character-level bounding boxes annotated in the MTHv2 dataset:
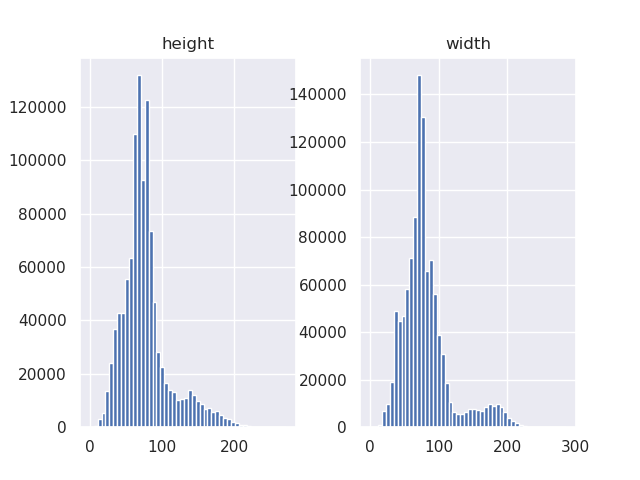
The medians are 74.0 for the width and 71.7 for the height. As we only need a rough estimate, I take it to be 73×73 px. The reason I chose the median to represent expected bounding box size instead of the mean, is that there are larger characters for headers etc. (as can be seen in the histograms) that lead to the mean being somewhat higher (81.2 (width) and 77.0 (height)). The median however can be safely assumed to represent the expected size of a character in the actual texts. By manual assessment I set the expected character size in the Jingbao scans as 25×25 px. The size s of one tile of the Jingbao needed to use the HRCenterNet right out of the box can thus be computed by:
500 ⋅ 25 : 73 ≈ 171.2
Again, only a rough estimate is needed, so I will continue with applying the HRCenterNet to tiles of size 170×170 px of the to-be-OCR'ed Jingbao segments.