First Experiments - hcts-hra/ecpo-fulltext-experiments GitHub Wiki
First, some basic experiments on feasibility are conducted, which can be reproduced by running this code.
Data
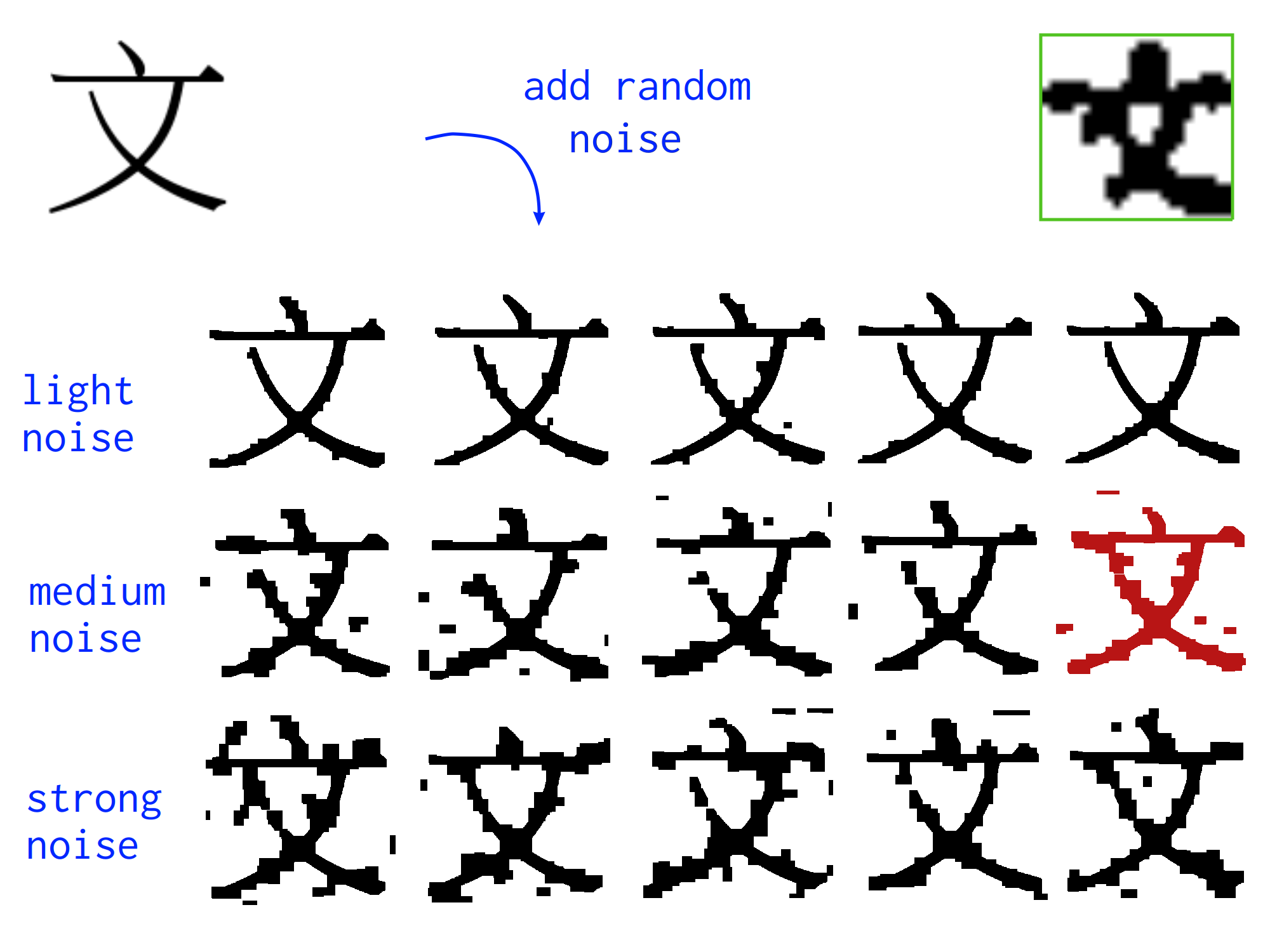
For the sake of small computational cost, the following experimental dataset was created: 256 character images from the Song typeface of the CNS11643 font set were extracted as png images and resized to 299x299 pixels. Inspired by an (equally scaled up) binarized image of a character cropped from the actual newspaper scans (green box in the top-right corner), randomized noise in three levels of intensity was added by random "peppering" and subsequently dilating, closing and opening* the image. Of the 15 images (5 per noise level), one image with medium noise is held out as validation data (marked in red below).
*since I worked with black content on white background, the operations have to be replaced by their counterparts in the actual implementation, i.e. dilation of black pixels means eroding the white ones.
Network Architecture
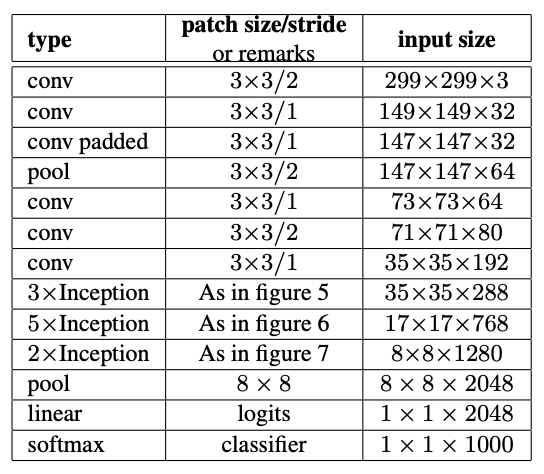
Since inception net has proven to work well for HCCR (hand-written Chinese character recognition), e.g. in this paper, I adapted it to deal with 1-channel inputs (grayscale instead of RGB) and trained it for 100 epochs as a classifier on the experimental 256 character dataset described above. The original architecture features a stride of 2 in multiple layers, leading to substantial dimension reduction in the 299x299 input as can be seen here (the jumps from 299x299 to 149x149, from 147x147 to 73x73 and from 71x71 to 35x35). Setting stride to 1 in these cases allows for an input image of size 45x45 instead of 299x299 without decreasing the number of parameters. Experiments show that since the amount of available information doesn't increase when scaling up a pixel image, those differences in model architecture are not of significant importance:
{kind=link}

(For the above experiments, every character image was first downsized to 40x40 before scaling it back up to different sizes. Thus, the same amount of information is ensured to begin with.)
Experiments also show that choosing a suitable batch size is not trivial (4 = best; 2, 8 are less good and 14 even worse; 1 doesn't converge at all):

A closer look at the training and validation error when training with batch_size=4 demonstrates the effects of a very easy validation set: 1. The validation error is even lower than the training error, which is due to the training set also containing "strong" noise and thus being harder.
2. The validation accuracy (% of correctly predicted among 256 images) reaches 100 % after 23 epochs with validation error approaching zero, suggesting overfitting.

Finally, a quick comparison to the GoogleNet architecture was done. In its adaption for grayscale images, GoogleNet has 5,857,057 trainable parameters, while Inception V3 has 22,311,585. This on the one hand means that GoogleNet converges a lot faster, reaching a 100% accuracy on the (very easy) validation set after only 20 min of training (vs. 69 min for the inception net, see plot below), but on the other hand fewer parameters might also entail performance loss on a harder validation set.

Conclusion
This experiment teaches us the following:
- The automatic generation and noisification of a character dataset from a font file is an effective and inexpensive approach to obtain large amounts of training data as needed.
- The inception net is suitable for training an OCR classifier with a big number of classes.
- In order for the validation set to be of any value, it should not be automatically generated along with the training set, but instead be as similar as possible to real test data.
The following questions remain open:
- How do other hyperparameters like momentum and learning rate influence the training process?
- Should the input image be binarized at all? Binarization comes with loss of information which might be fatal for the low-resolution characters in the newspaper. Idea: When applying thresholding for binarization, pixel values above the threshold are set to
255(white background) as usual, but pixel values below the threshold could keep their actual grayscale value. Inverting and normalizing the image will mean for the background to be "inactive" (0) and the remaining pixels to be of varying intensity (between0.0and1.0). - The inception net requires an input size of 299x299 px. What effect might modifying the first layer(s) to accept lower resolutions have on performance?