Finding and Connecting Separators - hcts-hra/ecpo-fulltext-experiments GitHub Wiki
NOTE: Due to image size this wiki is probably more convenient to read in a half-width window.
While the bottom-up approach described before removes separators and then relies on connecting text blocks through morphological operations , this approach works top-down by finding and connecting the page separators to create closed mask areas for text blocks. This is done by the following steps:
- Binarization
- Extracting contours that are likely to be separators
- Extending these contours to make them connect with surrounding contours
- Applying RLSA to close other small gaps
- Detecting and connecting corner points to make final connections
- Finding, filtering and smoothing white space contours
A representative crop from the 06/12/1923 issue of 晶報 shall serve to illustrate both the effectiveness and problems of the above procedure:

1. Binarization
Binarization is done by adaptive mean thresholding using a small kernel (e.g. 21x21 px) to compute the mean and a small positive constant c to prevent some of the noise (threshold = mean - c, lower threshold means less black pixels). The small kernel size serves to make thin separators more visible as even a thin separator is still darker than its direct environment, however it also causes some noise to be emphasized.

2. Separator Extraction
To close some potential small gaps within separators without closing gaps between text and separators, morphological opening is employed (2x2 kernel, 2 iterations). This closes gaps of 2 pixels width.
Separators are heuristically defined as contours (= connected black pixels) whose bounding box
- is taller or wider than a certain value (e.g. 300 px) and/or
- exceeds a certain ratio when dividing either height by width or width by height.
As can be seen, horizontal bars that arise from bad scan quality as well as other contours will cause unwanted noise:
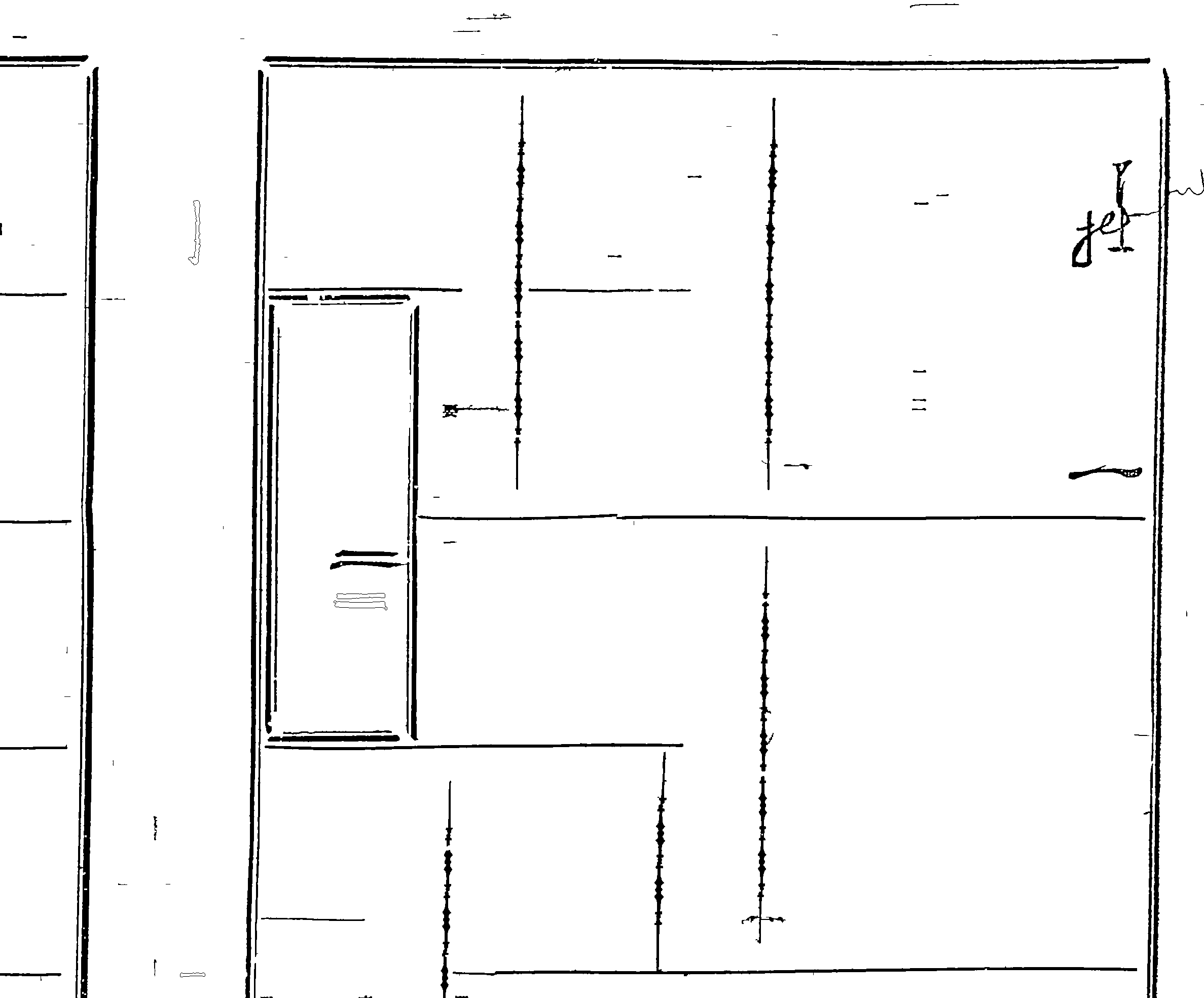
3. Separator Extension
Since the vast majority of separators in the corpus don't connect which would later cause text block masks to flow into each other, they are extended vertically or horizontally depending on their bounding box's aspect ratio. The example image shows the state after vertical and before horizontal extension. Vertical extension can be more aggressive (green boxes) as in no case text runs between them and the contours above or below, but if noise is in the way or the separator itself is polluted with noise this method is likely to fail (red boxes). Those cases will be dealt with further down. Horizontal extension has to be done more carefully, since only small gaps – mostly to the left – are to be closed, while large gaps on the right typically contain a heading (blue boxes):
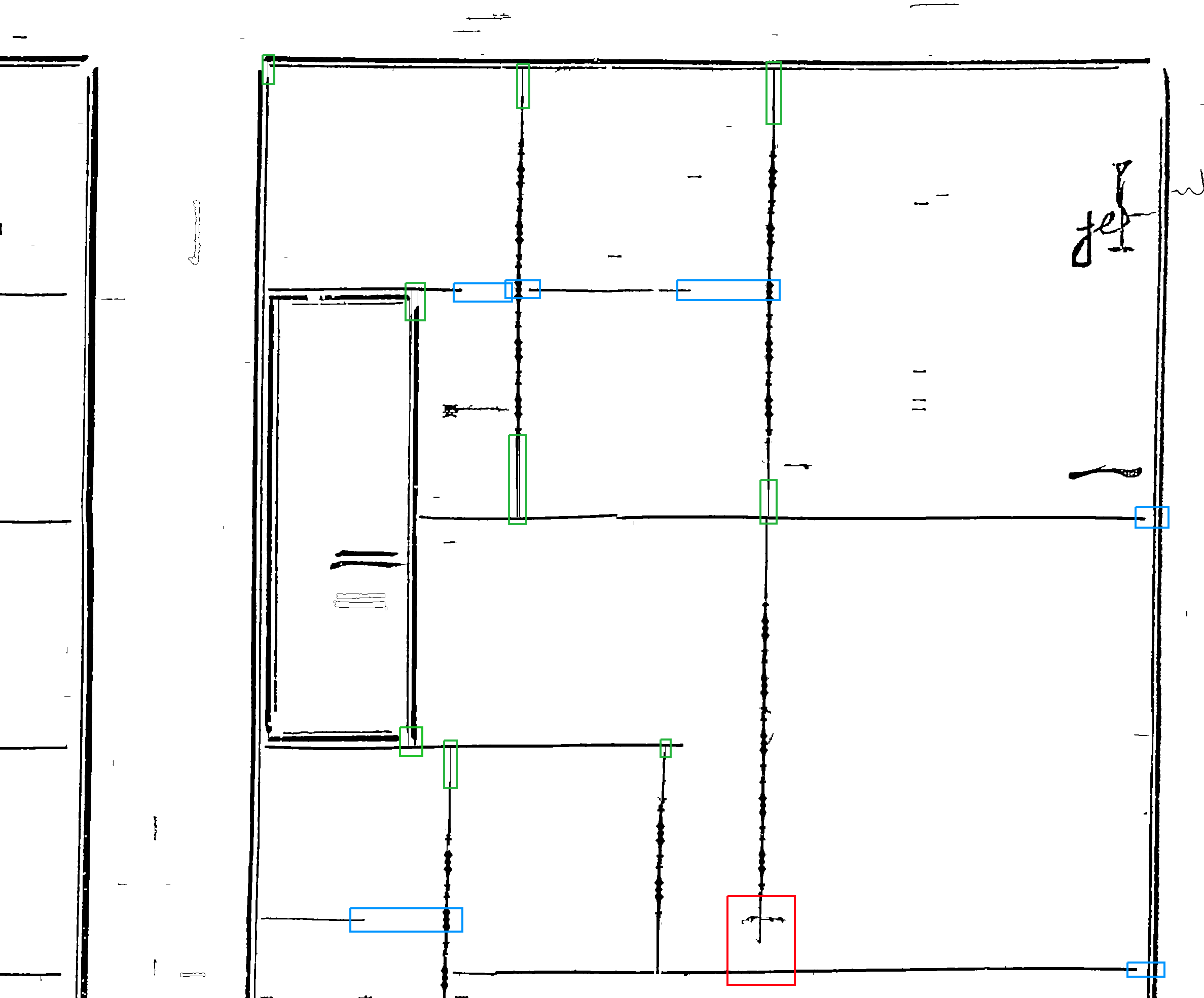
As explained above, some polluted or uniliterally connected separators' bounding boxes won't exceed the aspect ratio necessary for the step above. This can be countered with a less elegant approach employing a convolutional filter that will recognize open line-endings and extend them with the hope of hitting or getting sufficiently close to other contours. An exemplary filter to find bottom endings of vertical lines looks like this:
-10 -10 -10 1 1 1 1 -10 -10 -10
-10 -10 -10 1 1 1 1 -10 -10 -10
-10 -10 -10 1 1 1 1 -10 -10 -10
-10 -10 -10 1 1 1 1 -10 -10 -10
-10 -10 -10 1 1 1 1 -10 -10 -10
-10 -10 -10 -10 -10 -10 -10 -10 -10 -10
-10 -10 -10 -10 -10 -10 -10 -10 -10 -10
-10 -10 -10 -10 -10 -10 -10 -10 -10 -10
The margin (number of -10s, in the example 3) and the width and height of the line segment has to be heuristically chosen. Lines wider than the number of 1s will not be found. The filter is applied after eroding the inverted binary with a (in this case) vertical kernel (e.g. np.ones((50,1))) to remove noise and keep (in this case) vertical separators intact. The resulting mask can be vertically dilated to create the missing line segments. They are inverted back (= black line extensions on white ground) before bitwise conjunction with the original binary image. The gap in the red-boxed area of the above image is now almost closed:

4. RLSA
This algorithm makes adjacent white pixels in one row/column black if their number is below a certain value, which is effective for closing smaller gaps, e.g. between double-lined separators or other gaps the steps before have still left open (e.g. in the red-boxed area two images earlier). However, it has to be applied with care as a threshold chosen too high will result in single character columns (or lines) enclosed by separators getting closed up as well.

5. Corner Detection and Connection
All of the methods described above are only able to deal with perfectly vertical or horizontal gaps, however sometimes separators fail to connect in a diagonal way, such as the outermost frame at the top right. Other folds show cases of separators not connecting to very close image corners etc. As a final measure for these cases corner detection as described by Harris & Stephens (1988) is employed, with detected corners marked as grey dots for illustration:
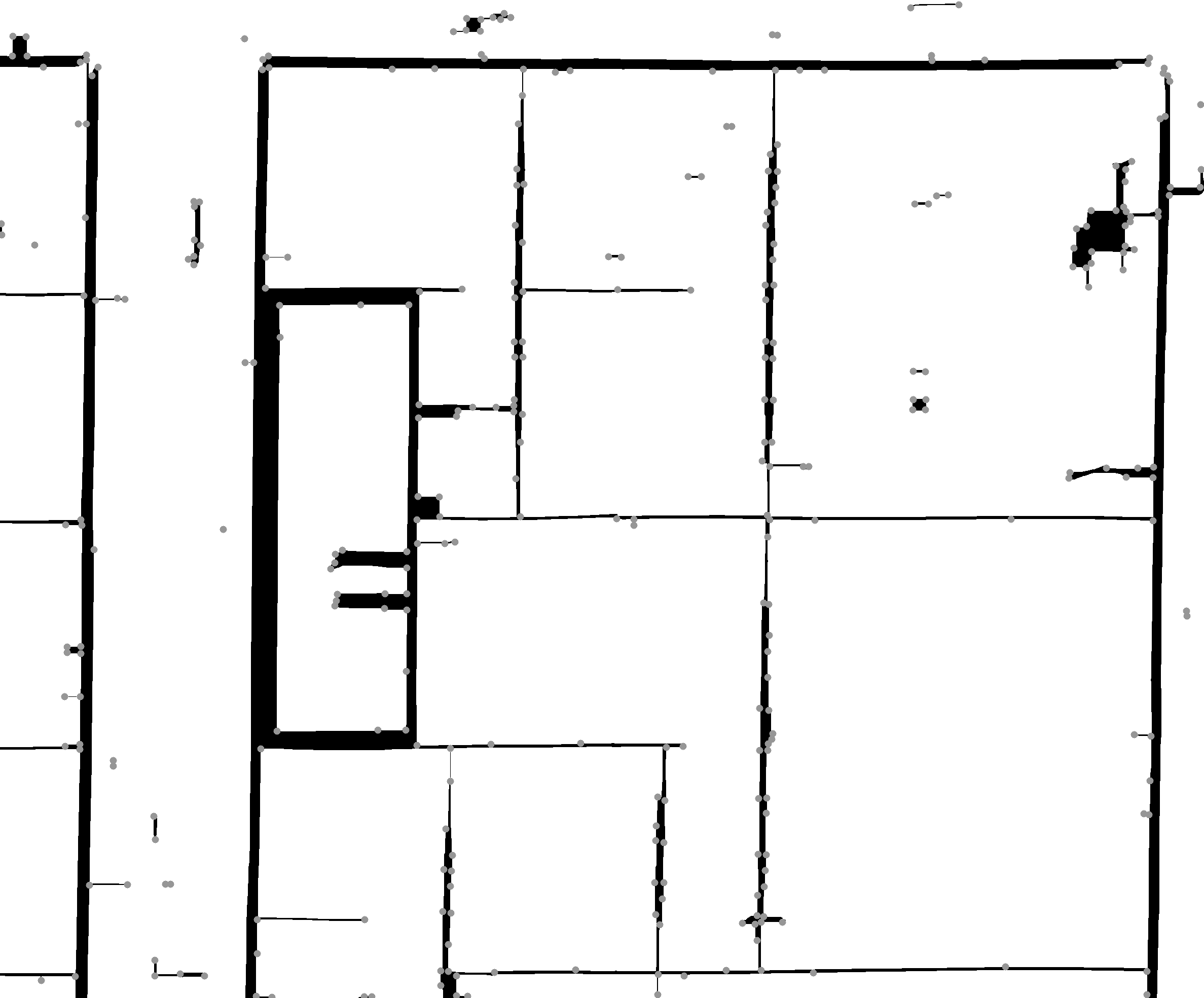
Finally, all corners in close proximity to each other are connected by a line. This, however, also causes more noise:
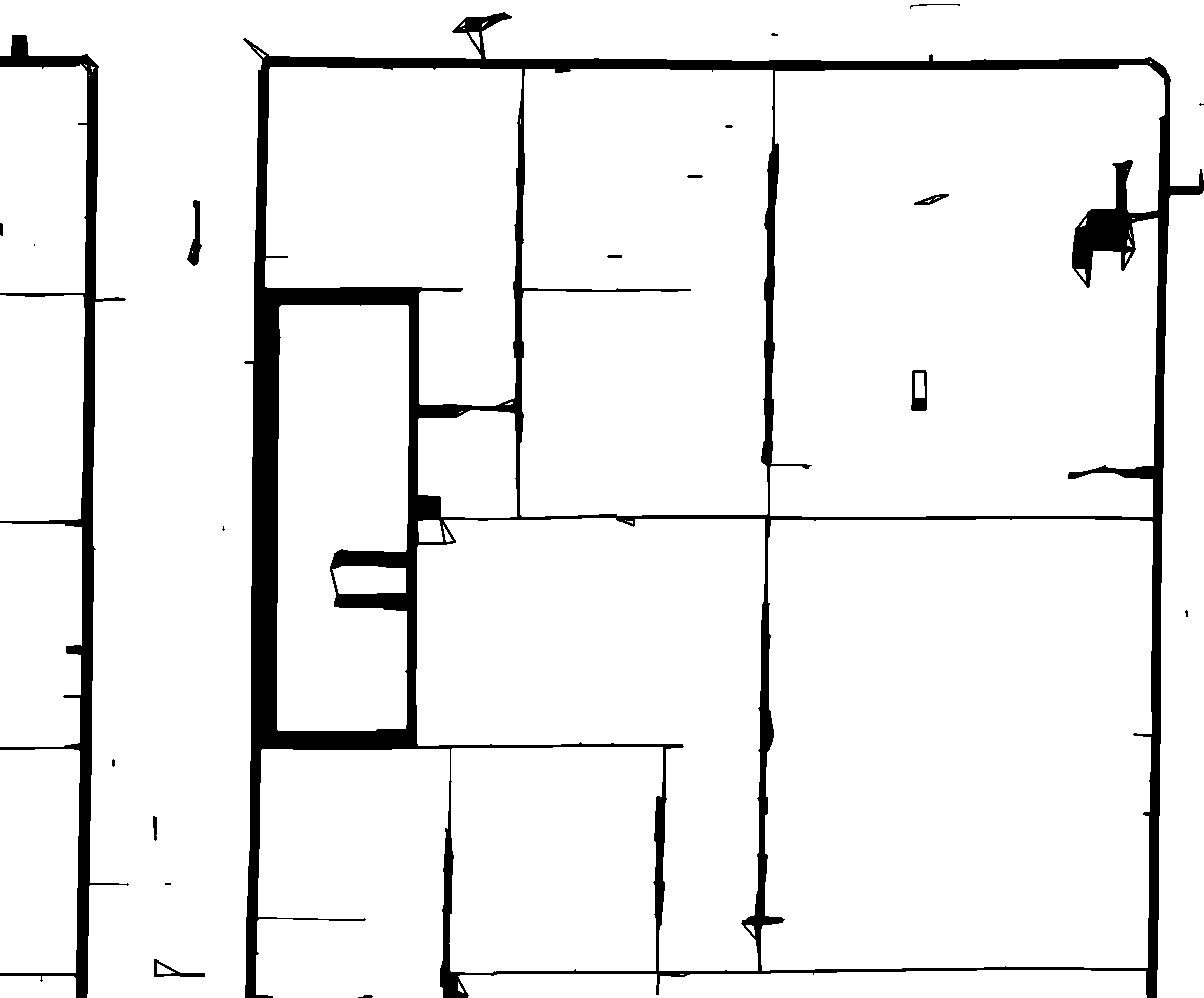
6. Finding, Filtering and Smoothing Contours
Every connected white space is extracted and separately morphologically closed using an 80x80 kernel to smooth out the edges. Finally, in order to only obtain contours of interest, the following size filtering is done (w meaning width and h height):
w < 2000 and h < 3000 and ((w > 20 and h > 100) or (w > 100 and h > 20))
The first part removes whole-page contours, the second part only allows for contours of certain minimum size: If it's slim, then it must be long. This leaves us with the final result of this method:

Problems:
The result is satisfactory considering low computation costs, especially compared to ML-based approaches, however exhibits different types of problems:
- Noise: As can be seen in step 2, the contour-based approach to extracting separators also causes some other small contours to be extracted, above all the Chinese character 「一」 "one". Raising the threshold for minimum contour size would however also lead to missing out on fragments of thin horizontal separators. Also, contours arising from image pollution such as visible tears, hairs, backside images shining through, horizontal bars due to bad scan quality etc. may wrongly be extracted, causing text blocks being cut into pieces (as can be seen in the image above where the lower part of the top-left article is split right amidst the expression 「一個重要材料」). This is by far the most severe problem. In the future, this could be addressed by prohibiting separators to cut through text areas recognized by either morphological operations or an OCR tool.
- Dog-ears: Noise close to the corners of a textbox is particularly likely to cause problems such as its corner being "folded in" (as in the middle-left article where its top-left corner excludes the character 「慚」). More effective noise treatment and remedies described in 1. above could help to reduce them.
- Too thin or missing separators: Wherever separators are too thin to be fully extracted (as in the top-left article) or are simply missing, this will cause multiple text blocks to connect, requiring further separation at a later stage.
Conclusion:
This approach is both more successful and more robust than solely relying on morphological text block connection. Its strength is its reliability, not least because it simply follows the intuition of a human reader considering framed layout elements to belong together. Consequently, headings are far more likely to be included, polygonal article shapes are effortlessly found and extracted text boxes are sure to be free of other surrounding layout elements. Still, a lot of hard-coded values have to be found by manual measuring and trial and error, after which they are not adjustable to a radical layout change. This is an aspect where rule-based approaches generally fall short of those involving neural networks.