Git - hasselmonians/knowledge-base GitHub Wiki
Using Version-Control Software
One of the big advancements of computing in the 1970's was the implementation of almost all features of an operating system in human-readable code. Before this time, programs were generally written in extremely difficult to parse assembly code. With the advent of the programming language C and the implementation of the Linux kernel (the part of the operating system that interfaces with the hardware and allocates resources) in it, it became far more possible for humans to read and understand what a program was supposed to be doing.
Operating systems built on the Unix, Linux, or BSD-derivative kernels take this principle to its logical conclusion -- almost any setting, configuration, or otherwise, is specified in a text-file that is meant to be human-readable and human-editable. Open source, open code.
While this history lesson isn't necessary to learn how to use version-control software, it is important to remember that while your code is going to be (in most cases) compiled and executed by a machine, that humans are going to need to be able to read it and understand it. Good coding style is as important (if not more) than writing efficient, effective code.
This tutorial is about version-control software. Version control, or its close cousin, software configuration management (SCM), refers to the practice of keeping track of edits to a text file and the tools used to do so. Keeping track of edits to text files is important in order to understand what was changed when, why it was changed, and who changed it. This is especially important when multiple people are working asynchronously on text documents together, and rely on each other to make sensible changes.
While version control software, like git, works for any text document, one of the most important is source code, the human-readable text written in a programming language that consists of definitions and scripts meant to provide instructions to a computer to do computations. Since programming is hard work, involving a lot of thought and organization, keeping track of changes is extremely important, especially when other people rely on, or are collaborating, to make or use the software.
Introducing git
Git is a handy tool designed to streamline the version-control progress. Its name means nothing -- just three letters, unique enough to not be confused for something else, and short enough that it's quickly typed into a command line interface. Git can be accessed from a command-line interface, such as the shell scripting language BASH. There are also many graphical interfaces that implement git commands under-the-surface. Websites such as GitHub (owned by Microsoft) and GitLab (free and open source) allow code hosting for public and private viewing and interface with git commands.
Git is a tool with many commands. Some of the most commonly used are clone, add, commit, and push.
A location in data storage where code is stored is called a repository. A remote repository is one that exists on a server somewhere, such as one owned and maintained by Microsoft/GitHub or GitLab, an open-source code-hosting site. A local repository is one on the computer where you are working.
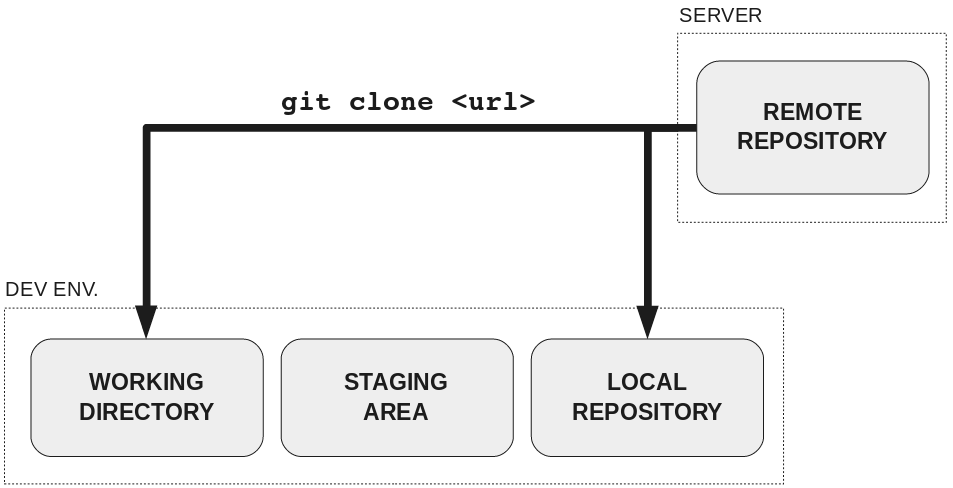
Cloning a Repository
When you clone a repository, you make a copy from the remote repository and save it as a local repository on your computer. This only needs to be done once, when you want to get code you want from the internet from the first time.
For example, to clone the RatCatcher repository, from GitHub into /home/alec/code/ I would do:
cd /home/alec/code
git clone https://github.com/hasselmonians/RatCatcher
Committing a change
The local repository is your pristine copy of the remote repository. Your working directory is your scratch space. When you open up a text file inside a local repository in your favorite text editor and start changing things, your changes are saved to your working directory.
When you want to save your changes to the local repository (so that you can update the remote repository), you will add and then commit your changes. Why are there two steps? It gives you more options. Add means, "please keep track of this file," whereas "commit" requires a short message explaining what was changed, such as, "Add function for Savitzky-Golay filter".
Once changes are committed, you can push to add them to the remote repository.
In order to get changes from the remote repository, you use pull instead.
If I were using the command-line to use git, my workflow would be something like this: I write some code, save it locally (Ctrl+S), then add the files I want to track, then commit my changes with a message, and then push to the remote repository.
git add . # add all files
git commit -m "Message about the thing I changed"
git push # update remote repository
What are branches?
Branches are a way of keeping breaking changes to your code separate. Say you're working on a project and you suddenly have an idea that you think will really help, but might break a lot of your extant code. You make a new branch, try things out there, see if it works. If it does, and you want it to become part of the master branch, you will merge the two branches together, adding all the commits from the new branch to the master branch. This is also great when multiple people are working on a project. It means that you can create your own branch and fiddle with things, and when you push to the remote repository, it won't overwrite what anyone else has done.
How do I use git?
You can use git from the command line (as shown above). Many text editors/interactive development environments (IDEs) have built-in graphical interfaces for using git (for example, Atom does). In addition, you can use GitHub Desktop if you're on Windows and your code is on GitHub.
Credit
Figures by Rachel M. Carmena.