Transformer - glqglq/ml_dl_wiki GitHub Wiki
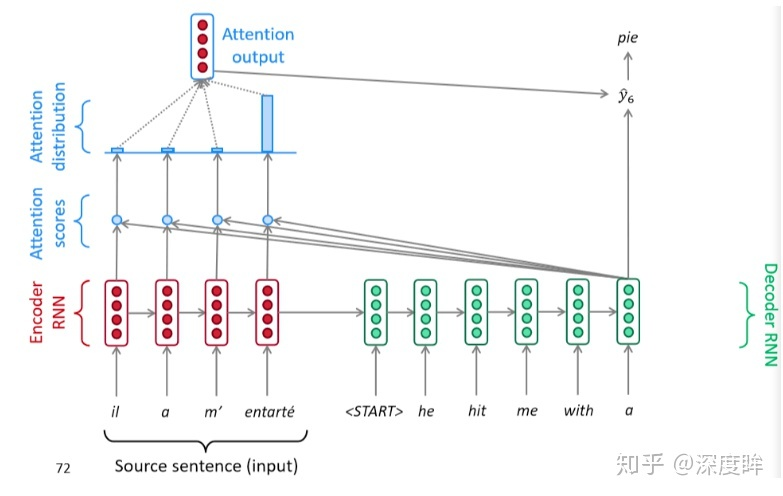
- 解码阶段会将第一个开启解码标志(也就是Q)与编码器的每一个时间步的隐含状态(一系列Key和Value)进行点乘计算相似性得到每一时间步的相似性分数,然后通过softmax转化为概率分布,然后将概率分布和对应位置向量进行加权求和得到新的上下文向量,最后输入解码器中进行解码输出。
- 优点:
- 在没有attention时候,不同解码阶段都仅仅利用了同一个编码层的最后一个隐含输出,加入attention后可以通过在每个解码时间步输入的都是不同的上下文向量。注意力显著提高了机器翻译性能。
- 注意力允许解码器以不同程度的权重利用到编码器的所有信息,可以绕过瓶颈。
- 通过检查注意力分布,可以看到解码器在关注什么,可解释性强。
- Motivation:
- 不管是采用RNN、LSTM还是GRU都不利于并行训练和推理,因为相关算法只能从左向右依次计算或者从右向左依次计算
- 长依赖信息丢失问题,顺序计算过程中信息会丢失,虽然LSTM号称有缓解,但是无法彻底解决
- 结构:
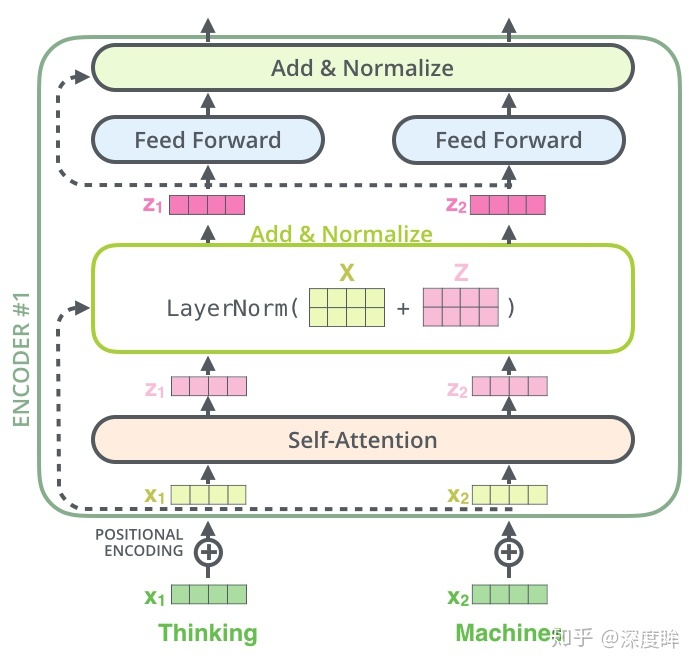
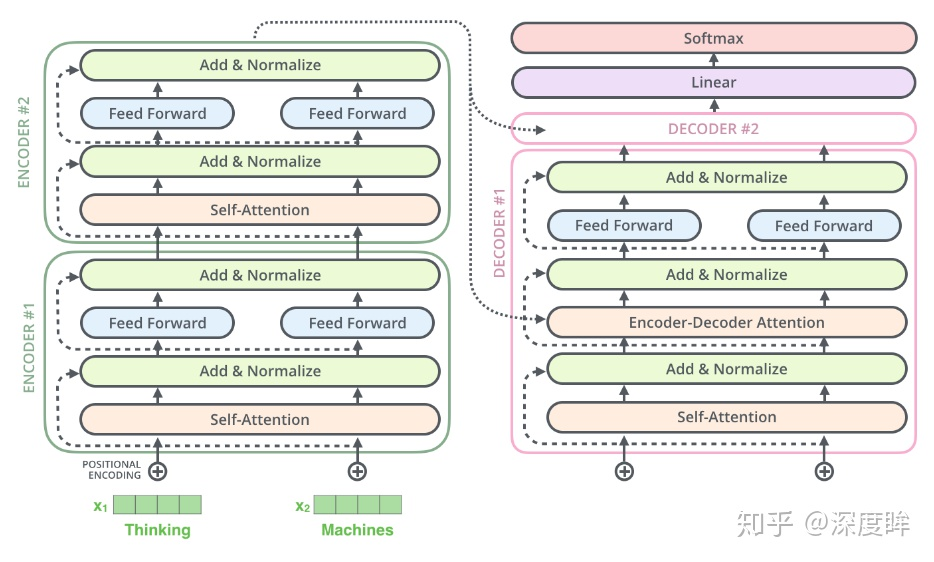
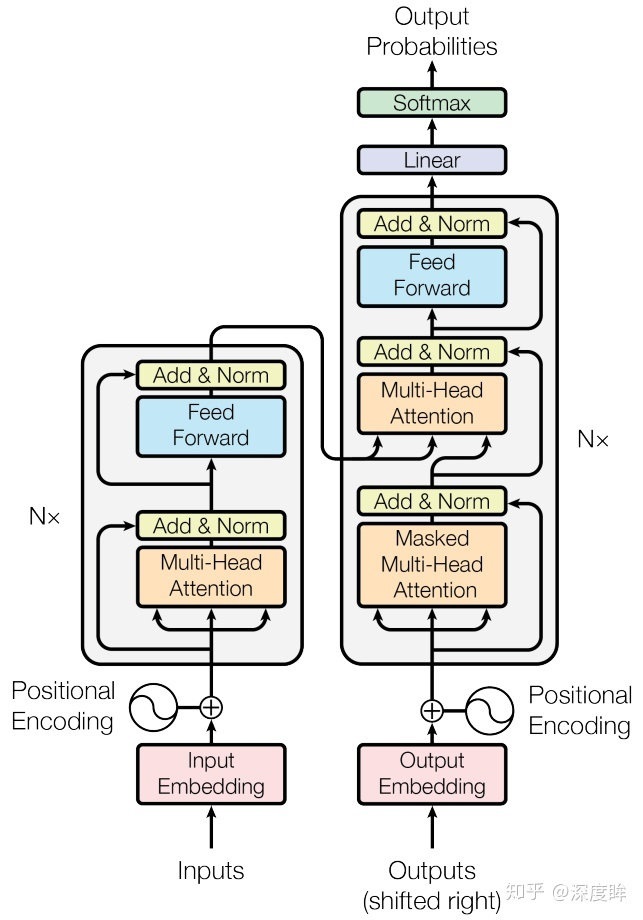
- 前向:
- encoder-输入:N×1。
- encoder-embedding:N×k_1。
- 输入Lembedding:N×k_1。假设统计后发现待翻译句子最长是10个单词,那么编码器输入是10x512,额外填充的512维向量可以采用固定的标志编码得到。
- 位置embedding:N×K_1。由于transformer内部没有类似RNN的循环结构,没有捕捉顺序序列的能力。position encoding向量表示两个单词i和j之间的距离。
- 网络自己学习:pos_embedding = nn.Parameter(torch.randn(bs, N, 512))
- 定义规则(sin-cos规则):
- 方法:pos即0~N,i是0-511。将向量的512维度切分为奇数行和偶数行,偶数行采用sin函数编码,奇数行采用cos函数编码,然后按照原始行号拼接。能够扩展到未知的序列长度。
- 图示:
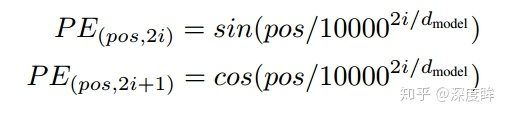
- why work:
sin和cos的如下特性:
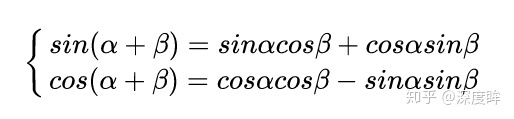
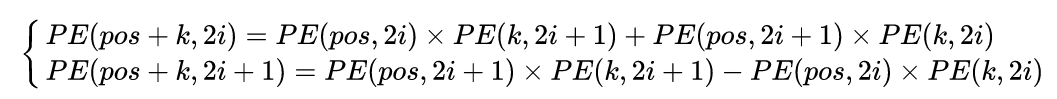 假设k=1,那么下一个位置的编码向量可以由前面的编码向量线性表示,等价于以一种非常容易学会的方式告诉了网络单词之间的绝对位置,让模型能够轻松学习到相对位置信息。
假设k=1,那么下一个位置的编码向量可以由前面的编码向量线性表示,等价于以一种非常容易学会的方式告诉了网络单词之间的绝对位置,让模型能够轻松学习到相对位置信息。
- encoder-自注意力层:N×k_2。
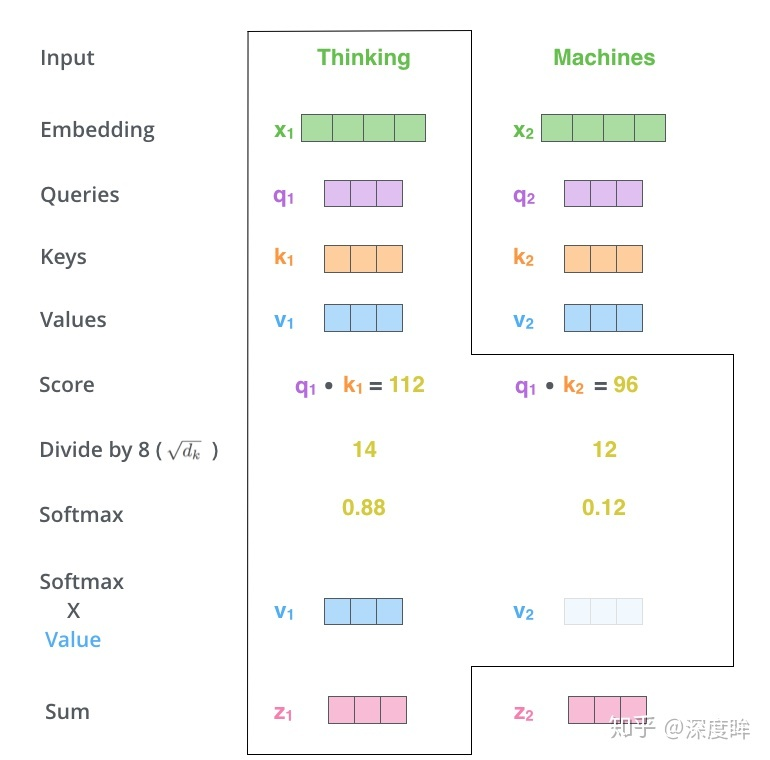
- 方法:将q1和所有的k进行相似性计算,然后除以维度的平方根(论文中是64)使得梯度更加稳定。多头注意力机制类似于分组操作,将输入X分别输入到8个attention层中,得到8个Z矩阵输出,最后对结果concat即可。
- 图示:
- why work:
- 它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
- 它给出了注意力层的多个“表示子空间",对于“多头”注意机制,有多个查询/键/值权重矩阵集(Transformer使用8个注意力头,因此我们对于每个编码器/解码器有8个矩阵集合)。
- encoder-残差:N×k_2。
- encoder-layer norm:N×k_2。
- encoder-前馈神经网络层:全连接。N×k_3。
- decoder-输入:
- decoder-embedding:
- decoder-masked自注意力层:解码器内部的带有mask的MultiHeadAttention的qkv向量输入来自目标单词嵌入或者前一个解码器输出,三者是相同的。
- why mask:每次解码都会利用前面已经解码输出的所有单词嵌入信息,这个测试过程是没有问题,但是训练时候我肯定不想采用上述顺序解码类似rnn即一个一个目标单词嵌入向量顺序输入训练,肯定想采用类似编码器中的矩阵并行算法,一步就把所有目标单词预测出来。要实现这个功能就可以参考编码器的操作,把目标单词嵌入向量组成矩阵一次输入即可,但是在解码am时候,不能利用到后面单词a和student的目标单词嵌入向量信息,否则这就是作弊(测试时候不可能能未卜先知)。
- 方法:引入mask,目的是构成下三角矩阵,右上角全部设置为负无穷(相当于忽略),从而实现当解码第一个字的时候,第一个字只能与第一个字计算相关性,当解出第二个字的时候,只能计算出第二个字与第一个字和第二个字的相关性。具体是:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置,在softmax步骤前,它会把后面的位置给隐去(把它们设为-inf)。
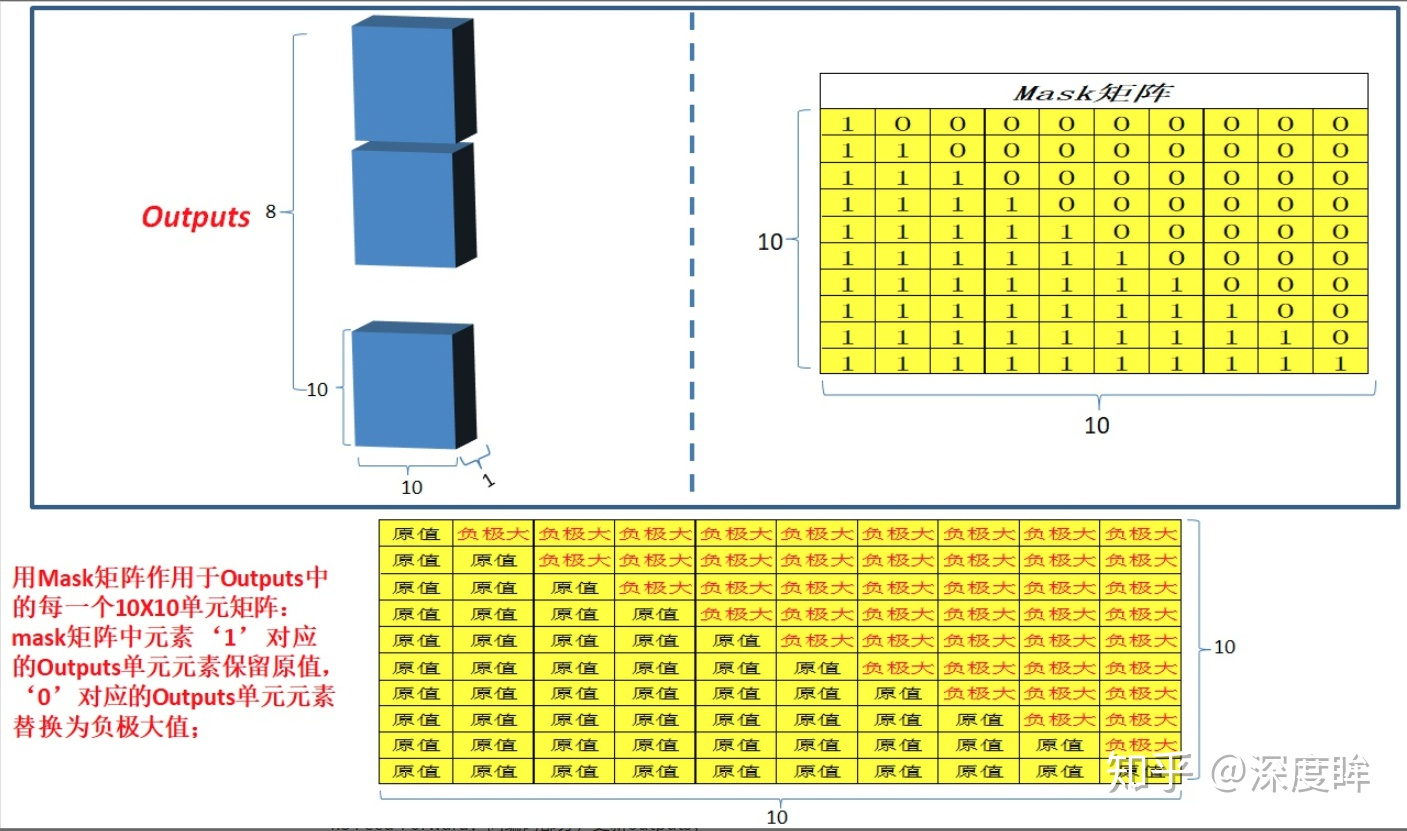
- decoder-残差:
- decoder-layer norm:
- decoder-自注意力层:MultiHeadAttention的qkv向量中的kv来自最后一层编码器的输入,而q来自带有mask的MultiHeadAttention模块的输出。
- decoder-残差:
- decoder-layer norm:
- decoder-前馈神经网络层:全连接。N×k_3。
- decoder-残差:
- decoder-layer norm:
- decoder-fc:
- decoder-softmax:
- Motivation:
- 一些替换cnn的attention网络模型加了一些模块没有很好的拓展性(scaled effictively)。
- Method:
- 结构:
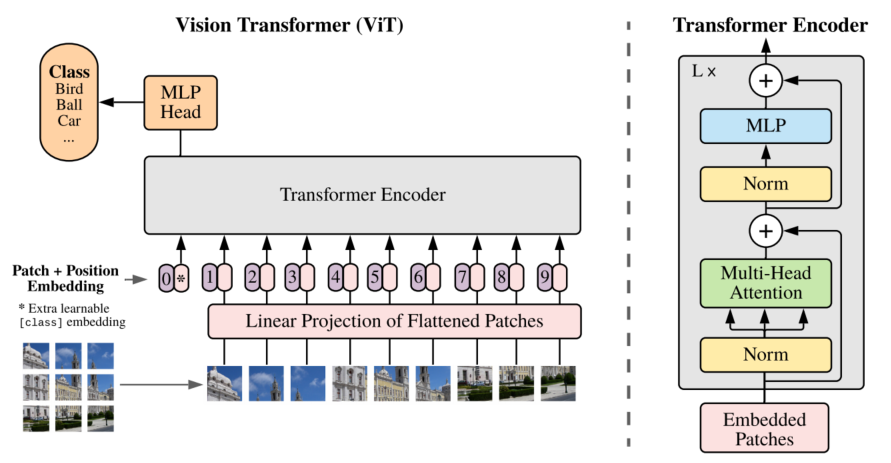
- 输入:(h,w,c)输入图像reshape为(hw/pp,ppc),其中pp为patch的像素量,切为hw/pp个小块(word),图像patch可以替换为CNN的中间层特征图。
- pos emb:使用1D位置embedding不用2D的,因为2D也不会提点。
- token:其transformer的输出表达输入到mlp里,作为最后的决策依据。
- fine-tune:在后续处理更大尺寸图片时,每个Patch的尺寸不变,序列长度增加。position embedding插值处理。
- 结构:
- Exp:
- comparsion to sota:达到sota,还能节约训练资源和时间。当用中小数据集(imagenet等)pretrain的时候ViT表现比当前sota差,由于其缺少平移不变性、获取局部信息的能力。大数据集(14M-300M)时反之。
- pretraining data requirements:当用中小数据集pretrain的时候,大ViT模型表现比小ViT模型差,用大数据集时反之。
- scaling study:Vision Transformer 在性能 / 算力权衡中显著优于 ResNet。hybird版本在小模型更好,大模型和ViT差不多了。
- INSPECTING VISION TRANSFORMER:更近的patch有更相似的pos emb,同行/列的patch有更相似的pos emb,大网络的sin结构是明显的(?)。自注意力使得可以得到低层图像信息。
- Advantage:transformer很少修改。
-
Motivation:
- 和文本比,图像具有高分辨率,现有的视觉transformer中,有一些dense prediction任务在做像素级别的预测,如分割,这使得vi transformer很难做,因为全局细粒度self-attention复杂度相对于图像尺寸是平方级别的。
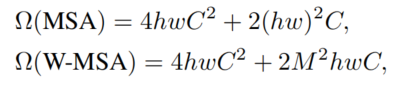
- 和文本比,图像有高像素scale,现有的视觉transformer中,token是固定的scale。
-
Method:
- 结构:一张图划分为若干个window,每个window有M*M个patch。每个window都有固定数目的patch,因此复杂性和图像大小成线性关系(主要看能分为多少个patch)。同时,同window内所有的query patch共享同样的key set,这在真实存储中也是连续内存。
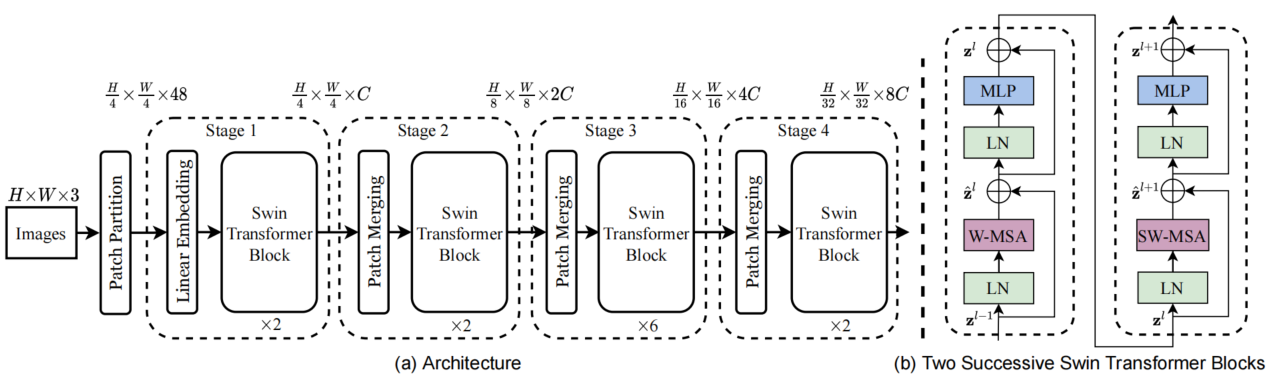
- hierarchical:上层patch多,下层patch少。merging layer实现,它将每22的patch都concate成一个新patch,再进行映射,使得patch数据量减半,数据量变化:C->4C->2*C。
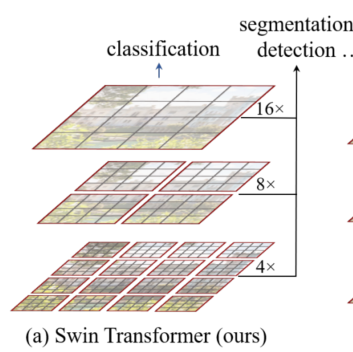
- sifted:解决window-based self-attention缺少window之间的联系。向左上移动图像即可。方法介绍、复杂度分析如下:
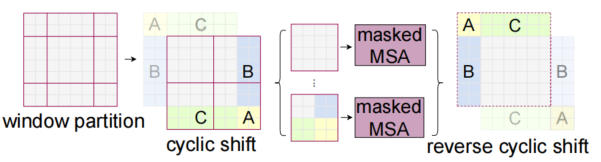

-
参考: