2015 11 02 scaling mongodb at kadira - giordanocardillo/kadira-server GitHub Wiki
title: Scaling MongoDB at Kadira category: other summery: Here's how we process data in Kadira. We also talk here about some of the issues we got and how we fix them.
At Kadira, we process a lot of metrics and application traces every day. We use several different data persistence technologies. MongoDB is at the heart of them. As I write this blog post, we are processing and storing around one billion metrics per day using MongoDB.
Of course, we are pushing MongoDB to its limits. But now we know how to do so correctly. Here's our story.
We collect system and application metrics from Meteor apps. We use MongoDB to store and process those metrics. Raw metrics come directly to MongoDB and we keep them in a set of capped collections.
Then we pre-aggregate that data into different time resolutions. By doing so, we can have very fast reads even for longer data ranges.
We don't store one metric as a single document. We group a few metrics into a single document and insert that document. But we never update documents. That makes our process very efficient. I will talk more about why.
We use Meteor for our dashboards and to manage apps. We love Meteor and use MongoDB oplog to make it reactive.
We knew Meteor wouldn't be able to handle the massive data load we process, due to its use of the MongoDB oplog. So, we maintain a separate MongoDB cluster for Meteor and its app state. Our meteor app also connects to our main MongoDB cluster without the oplog. It polls for data changes, and it's efficient. That's because, in time series apps we always have fewer reads than writes.
So, we never have to worry about Meteor.
We delete all the metrics we store with a TTL. So, we need to compact MongoDB to regain space. WiredTiger's database engine does this automatically; otherwise you need to do it manually, which is a pain. WiredTiger also comes with document level locking, compressions, and many other cool features.
There are a lot of ways to store time series data with MongoDB. Some patterns suggest doing in-place updates to make it faster. But with WiredTiger, both inserts and updates are the same. So, batching a few metrics together into a single document and then inserting that document is the optimal way to store metrics.
Before we talk about how we scale MongoDB, you need to know how we aggregate data.
As I mentioned before, we are writing raw data into a set of capped collections. Then we run incremental map reduce jobs on these metrics to pre-aggregate them into different time resolutions. After that, we store these aggregated metrics into a few different collections.
So, a bunch of very short lived map reduce jobs are always in our MongoDB cluster.
September was one of the worst months for us. There were multiple outages because our single MongoDB replica set couldn't handle the load. Actually, the problem was not the write load. It was that MongoDB can't process map reduce jobs properly. These jobs started queuing and taking a very long time to process.
That's why you may have seen a lot of empty charts in Kadira. We tried adding more CPU power, but that didn't help much.
So, we were looking to scale our MongoDB cluster horizontally with MongoDB sharding. But MongoDB sharding requires a lot of ops knowledge and we didn't have that.
Also, we didn't wanted to shard based on the DB size. We wanted to do it based on the document insert rate. That is something we can't do with built-in MongoDB sharding.
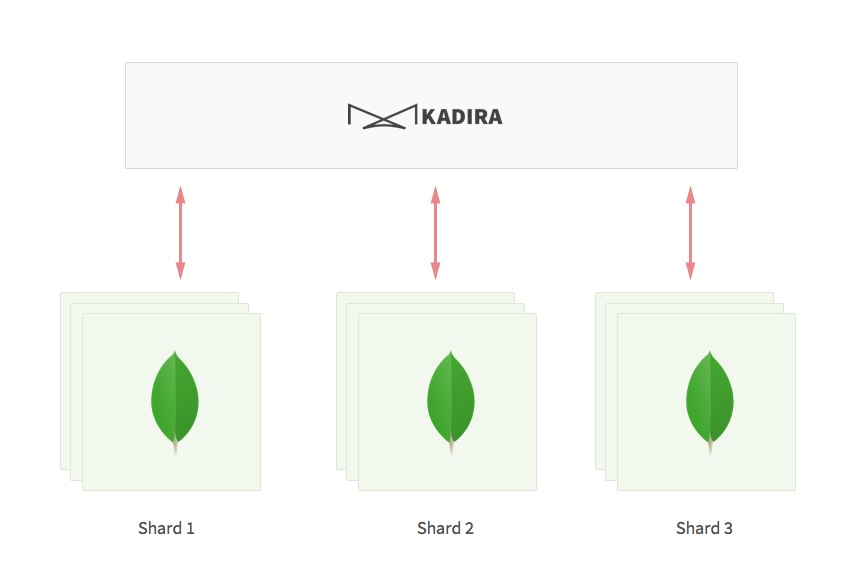
So, sharding MongoDB in the app layer was the only option we had. Actually, it was easier than we expected. Here's how we did it:
- We have multiple independent MongoDB replica sets. They are our shards.
- We run incremental map reduce jobs for each shard separately.
- When an app is created on Kadira, we assign a shard to that. We select the shard based on the lowest document insert rate.
- Then, all the metrics from that app will go into that shard.
- When reading metrics, we also select the shard based on the app.
We have written an Npm module to simplify our sharding process. Here it is: https://github.com/kadirahq/mongo-sharded-cluster
This works really well for us, and now we can add new shards without a zero downtime. Also, there is no additional ops works to do (rather than managing new replica sets).
On the other hand, now we can dynamically change the shard of any app if we need to. For example, if an app is sending too much data, we can move that app to a different shard very easily. You can't do something like that with the built in MongoDB sharding.
So, having done this, our problem went away and our map reduce jobs went smoothly.
We didn't get to keep enjoying our new sharded cluster. Map reduce jobs started queuing and delaying aggregations.
We tried using an aggregation pipeline instead of map reduce jobs. But that didn't help either. Some jobs (although they had a very small number of metrics) took quite a few hours to finish. In that time, we could have manually counted those metrics.
So, we tried out a different way to do aggregations. We implemented a map reduce job runner, which runs inside the Mongo shell. (Yeah, it's not running inside the DB.)
Here's how it works:
- It fetches the data we need to aggregate the Mongo shell.
- It runs map reduce jobs on the data inside the Mongo shell.
- It inserts the result using the MongoDB's bulk insert API.
Here's the our map reduce implementation, which runs on the Mongo Shell. Actually, it's simple Javascript function.
Surprisingly, this method was very successful. Now all our aggregation jobs get completed in under one second. We have been using this system for about a month and we haven't had a single issue so far.
So, running jobs inside the MongoDB sounds very cool in theory. But practically speaking, MongoDB can't handle them well. I'm not sure if the reason for that is a bug or a design decision, but that's reality.
Now we are processing around one billion metrics/dayapp very smoothly using a very small amount of computing power and ops.
We can use this system to scale even for 100 billion metrics/day. But we have an alternative data setup that could handle much more capacity than this.
Scaling is an art. Simply using technologies does not help you. We need to be smart about how we use the resources we have and always do experiments.
Also, you should be very careful when listening to someone's advice. It might work for that person, but it may not work for you because every system is different.
Finally, I should thank everyone who is using Kadira. You guys have stayed with us through all these downtimes and have always notified us if something went wrong. Thank you!