SPARQLgraph Deeper Dive - ge-high-assurance/RACK GitHub Wiki
This page gives a deeper dive into some of the features in SPARQLgraph beyond what's covered in the Getting Started page.
Check Services
Select the menu Help > Check services... to check that all services are reached. Your popup dialog should look like this:
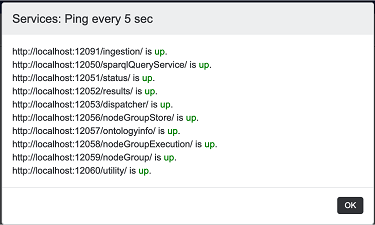
You may need to restart the container or VM if services continue to be down.
Set up a Graph Connection
You can set up a separate data graph to load your own data into. Choose Connection > Load from the menu and you will see a dialog that looks like this:
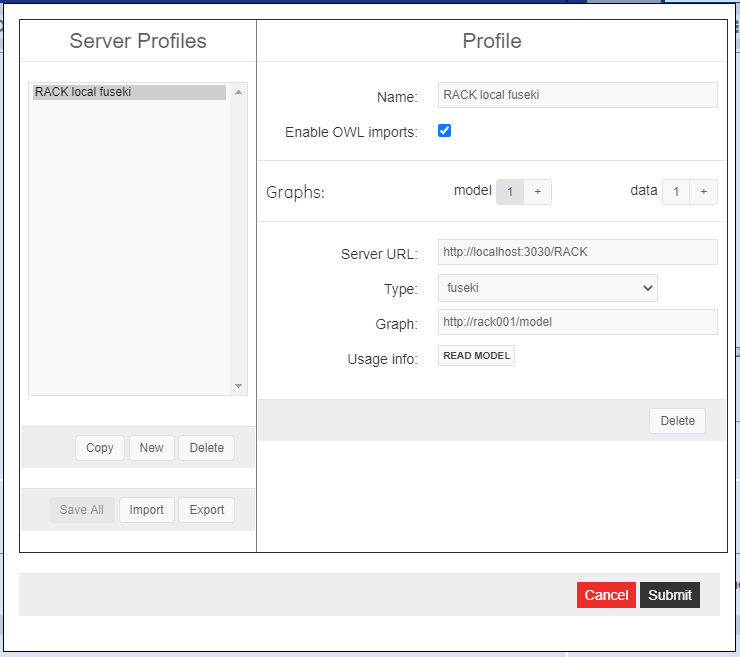
This dialog shows your named connections in the left panel, with fields at the right for configuring and building new connections. The most important features of a connection are the graph names and SPARQL endpoint(s) that specify where your ontology model and data are loaded.
These steps will create a new connection that shares the RACK ontology model, but has a clean data graph:
- on the left pane, hit "copy"
- enter a name like "RACK test data"
- click the "1" next to "data" about halfway down the right pane. This will show the connection to your data.
- change the "Graph:" entry for this data connection to
http://my/data - hit "Submit"
Load data
Data can be loaded into RACK using SPARALgraph. We'll demonstrate how to do this with existing data from the Turnstile example. Locate the following folder on your harddrive using a tool (e.g. Windows Explorer) that will allow you to drag and drop files into your SPARQLgraph web browser: RACK/Turnstile-Example/Turnstile-IngestionPackage/HazardAssessment
Choose nodegroup from the Query Tab
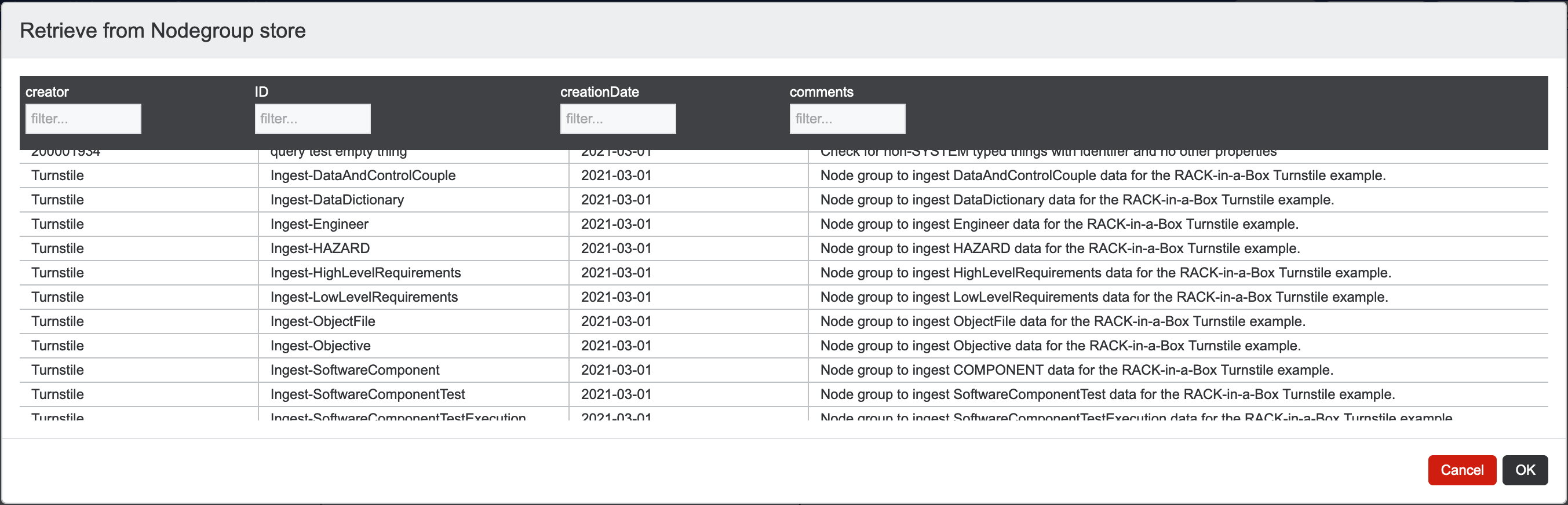
While on the Query tab, make sure your connection is to the "RACK test data" created following instructions from the previous section. This is displayed in the top-middle over the main canvas next to "Conn:". From the menu, choose Nodegroup > Open the store.... The dialog box will look something like the picture below. Pick the nodegroup ingest_HAZARD. Hit "Load"
You will see another dialog asking if you want to use the connection from the nodegroup file or the current one. Choose Keep Current
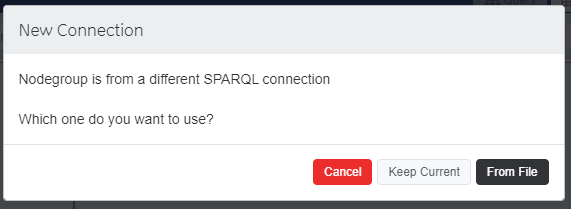
NOTE: Nodegroups in the store contain default connection information. Since you want to operate on your new connection, you want to "Keep the current connection" and not load the connection stored with the nodegroup.
Load data from the Import Tab
Now switch to the Import tab in SPARQLgraph and you'll see a screen like this:
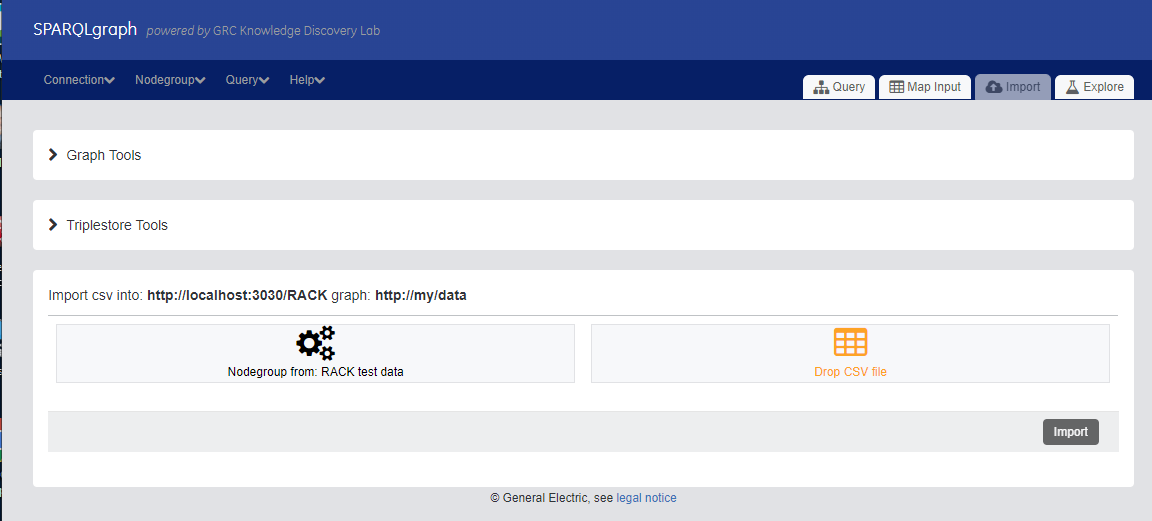
Using your local operating system tool (e.g. Windows Explorer), drag HAZARD1.csv to the dropzone marked "Drop CSV file" and hit "Import".
Errors
If you attempt to load bad data, you will receive an error table and no ingestion will occur. The table will show each row that failed ingestion and give at least one specific error message for a cell that failed.
The most common types of errors are:
- type parsing errors - a value can not be parsed to the indicated type, such as integer or date
- URILookup errors - attempting to link to a value that does not exist (e.g. while ingesting a test, referencing a requirement that has not been loaded)