How to use it - gabriel-milan/smtr_challenge GitHub Wiki
In this section, for the sake of simplicity, I intend to describe ways of executing the provided code on a development environment. For deployment and use in production environments, please check the Deployment section on their docs.
There are some ways of executing Dagster code, I'll cover the one they've recommended (using Dagit) and my own favorite (using Dagster CLI).
The file you're looking for when doing this is on the root of this repository and it's called main.py.
Choose your favorite Python environment (conda, venv, ...) and then install all requirements at the requirements.txt file on the root of this repository. For that, you could do
pip install --prefer-binary -r requirements.txt
After that, you'll problaby be all set!
Dagit is a web-based interface for viewing and interacting with Dagster objects. For running your pipeline(s) using Dagit, assuming your environment is already set, you can do
dagit -f main.py
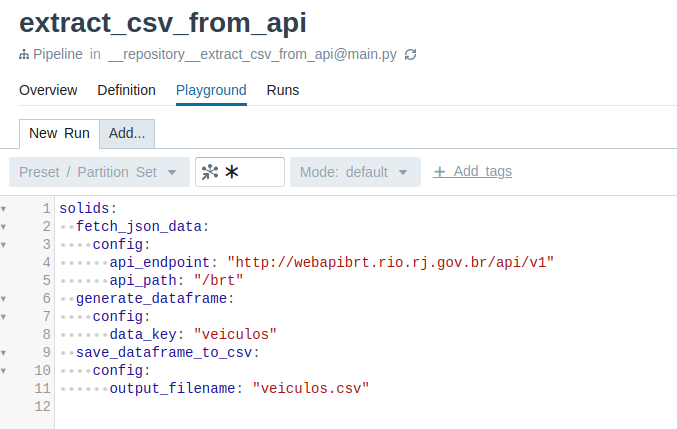
After that, navigate to http://localhost:3000/ in order to access the Dagit interface. Once there, click on the "Playground" tab and, before launching an execution, fill the configuration according to the How it works section. An example of configuration is the following:
solids:
fetch_json_data:
config:
api_endpoint: "http://webapibrt.rio.rj.gov.br/api/v1"
api_path: "/brt"
generate_dataframe:
config:
data_key: "veiculos"
save_dataframe_to_csv:
config:
output_filename: "veiculos.csv"It should look something like this:
After that, just click on the "Launch execution" button, and it should be alright. The output will look like this:
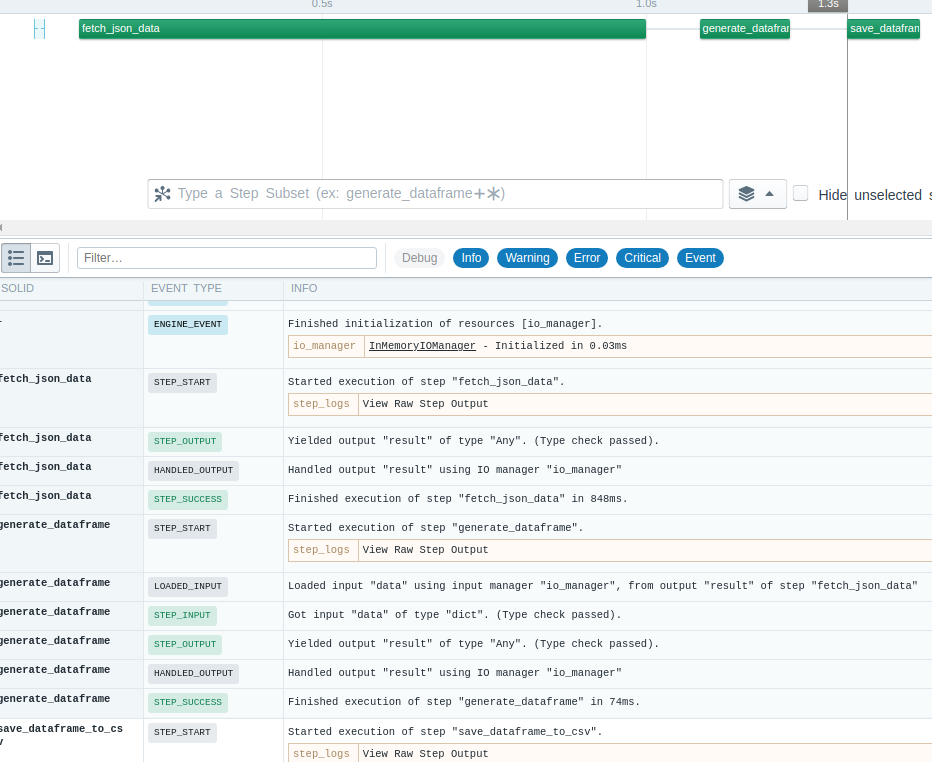
And you're done! The file veiculos.csv will be on the same directory from which you've executed the dagit command.
Again assuming that you have your environment set, you'll need a YAML configuration file for the execution. I've provided one on the root of this repository called sample_config.yml. If you desire to use it, just do (on the repository root directory)
dagster pipeline execute -f main.py -c sample_config.yml
The output's last line should look like this:
<date-hour> - dagster - DEBUG - extract_csv_from_api - 757fe10f-5436-4004-b940-128b243ddf0d - 15854 - PIPELINE_SUCCESS - Finished execution of pipeline "extract_csv_from_api".
And that's it! Again, the file veiculos.csv can be found on the same directory from which you've executed the command.