PL SQL Cursor Handling (Blog) - full360/sneaql GitHub Wiki
Migrating your Oracle data warehouse to Amazon Redshift can substantially improve data load performance, increase scalability, and save costs and of course faster queries , however these are non-procedural queries means with no if then else, iterative logic like looping through recordset in a cursor.
So ,How do you implement PL/SQL functionality in Redshift? This is where open source product called "SneaQL" offered by Full360 can fill the gap.
Let’s take this use case with the following oracle stored procedure and run
via simple to install SneaQL:

I have migrated an oracle table called demo_user into redshift (viewing in SQL Workbench/J)
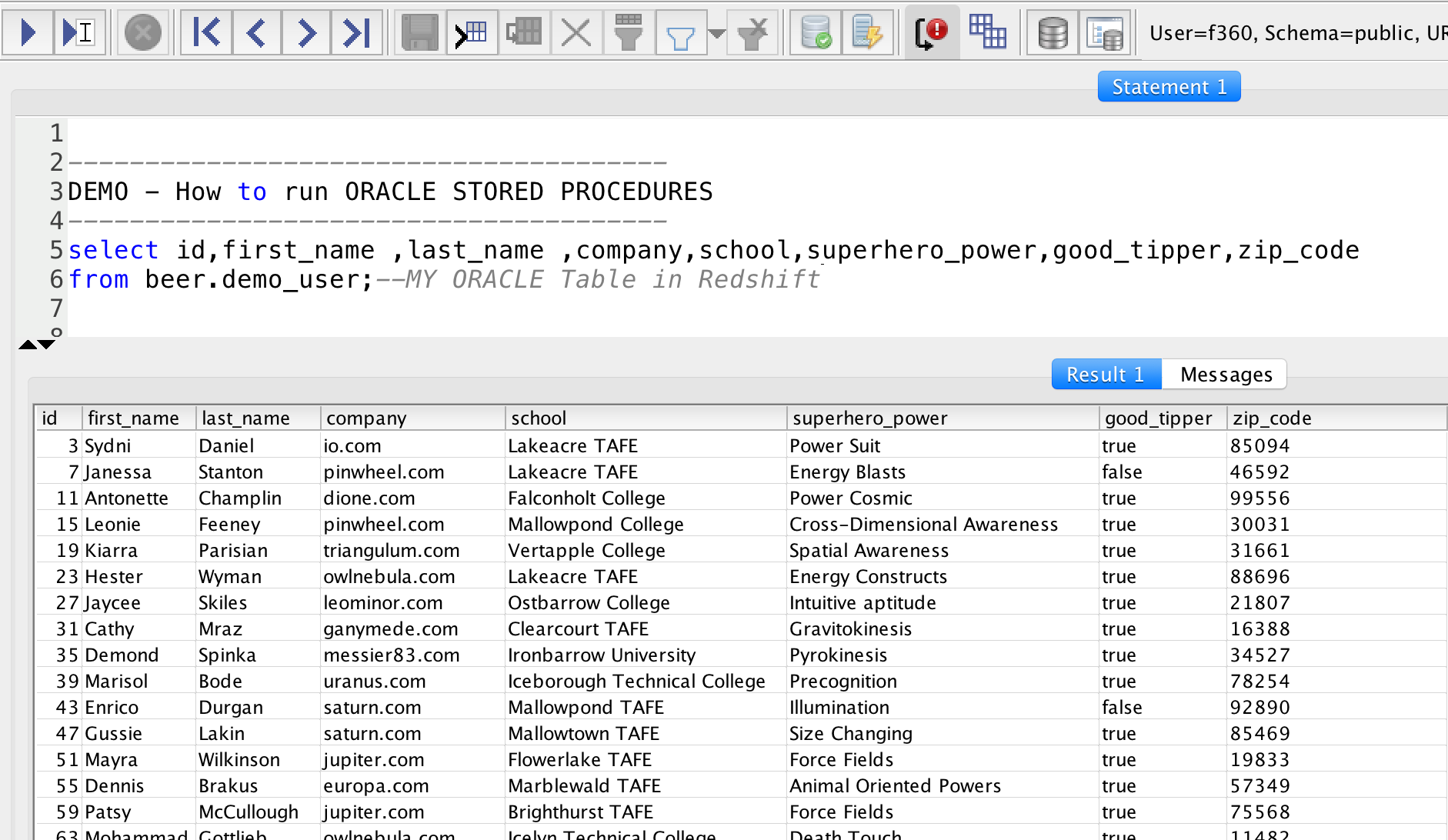
I wish to move records from here to another table called demo_experts as a result of executing the above oracle stored procedure. This stored Procedure creates a cursor to get all records starting with zip code 7,then it loops through each record and moves it into another table called demo_experts only if good_tipper attribute is true. There are two SQL query in this stored procedure which Redshift can just run in a blink of an eye and also there are two Redshift limitations as well , first creating a cursor , second looping through the cursor.
Let me walk you through how SneaQL will overcome this limitation with 2 simple instruction tags.And this is not a tested stored procedure .The focus here is not about PL SQL syntax but how SneaQL executes the procedural code in Redshift.
Lets copy these two sql queries into a file ,say demo.sql in a folder say 'Sneaql-Demo'
/*-recordset rs-*/
SELECT id,first_name ,last_name ,case when good_tipper = true then 'true' else 'false$
FROM beer.demo_user where zip_code like '7%';
/*-iterate rs include good_tipper = true -*/
insert into beer.demo_experts( id,first_name ,last_name,good_tipper ,zip_code )
values(:rs.id,':rs.first_name' ,':rs.last_name' ,':rs.good_tipper'::boolean $
now this first query is to create cursor, so we add the recordset tag just above it:
/-recordset rs-/
We are calling our SneaQL recordset (or cursor in PL/SQL) as ‘rs’
next is the query in the cursor loop with the condition for when or when not to insert the record in the demo_experts table.Will add following tag above this query: /- iterate rs include good_tipper = true -/
Recordset values in the insert would be referred as ‘:rs.field1’. Hence in our use case , it would be ‘:rs.id’ , ‘:rs.first_name’, ’:rs.last_name’ etc... You can also cast cursor fields on the fly like this ... ':rs.field1’::data_type. For instance in our use case , we used ':rs.good_tipper'::boolean to change good_tipper cursor field from string to boolean!
Unlike PL/SQL ,you don’t need to declare all the cursor field variables before hand for referring them later in the loop , SneaQL is very flexible and forgiving in this aspect.
So , include in iteration tag defines what to include and exclude define what to exclude , very simple ...right ? Let’s save the file and exit out.
SNEAQL needs just these three file from us in a folder to tell where and what to perform 1.demo.sql ( *.sql file , contains your code to run) 2.sneaql.env ( where to run , database connection info) 3.sneaql.json(list you all your .sql files in the order you wish)
We have created our demo.sql. Here is how sneaql.env looks like:
SNEAQL_JDBC_URL=jdbc:redshift://<cluster_name>.<master_node>.<region_name>.redshift.amazonaws.com:5439/<db_name>
SNEAQL_DB_USER=f360
SNEAQL_DB_PASS=Password1
SNEAQL_JDBC_DRIVER_JAR=/<local_jar_path>/RedshiftJDBC42-1.1.17.1017.jar
SNEAQL_JDBC_DRIVER_CLASS=com.amazon.redshift.jdbc42.Driver
SNEAQL_COMP = 100000
This is the third and final file 'sneaql.json' that SneaQL needs:
[
{"step_number" : 1, "step_file" : "demo.sql" }
]
since we kept it simple for this demo and have created only one single sql file which is demo.sql, so there is only one entry...we can add more and so on The purpose of this file is to accomplish batch processing and also in the specific order that we wish.If we have say 2 more files demo2.sql and demo3.sql and we wish to run demo.sql first , then demo2.sql and then demo3.sql We will simply add these entries in sneaql.json :
[
{"step_number" : 1, "step_file" : "demo.sql" }
{"step_number" : 2, "step_file" : "demo2.sql" }
{"step_number" : 3, "step_file" : "demo3.sql" }
]
So, now we know about all the three files in folder 'Sneaql-Demo'
so , let's execute our code.

I am running SneaQL from the current folder , so I would just type dot. You can always run SneaQL from anywhere and specify the path for your files as well.
Let's check the data we needed.
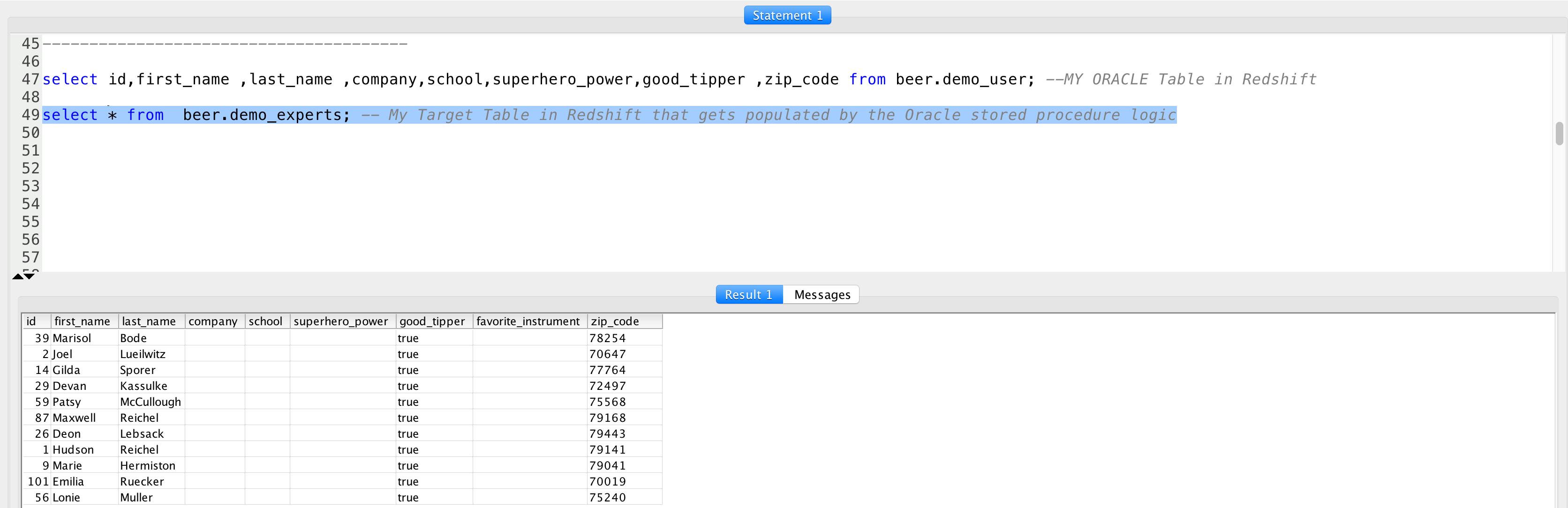
And here we have the data we needed... all records with zip code starting with number 7 and good_tipper = true.
There are only 9 simple Sneaql instruction tags that pretty much take care of all complex procedural logics you can think of.