MachineLearning_Pandas - fsjames/FeliciaTalksTech-Academy GitHub Wiki
Pandas
Pandas is a library used for computation with tabular data. It allows you to put mixed types of data into a single table.
In pandas, a vector (1 dimension) is called a Series and an array (2 dimensions) is called a DataFrame
Series E.g.
import pandas as pd
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> ser = pd.Series(data=d, index=['a', 'b', 'c'])
>>> ser
a 1
b 2
c 3
dtype: int64
DataFrame E.g.
import pandas as pd
>>> d = {'col1': [1, 2], 'col2': [3, 4]}
>>> df = pd.DataFrame(data=d)
>>> df
col1 col2
0 1 3
1 2 4
You can use pandas read_csv() method to read data from a csv file and store the data into a dataframe
# importing pandas module
>>> import pandas as pd
# importing regex module
>>> import re
# making data frame
>>> data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
>>> print(data)
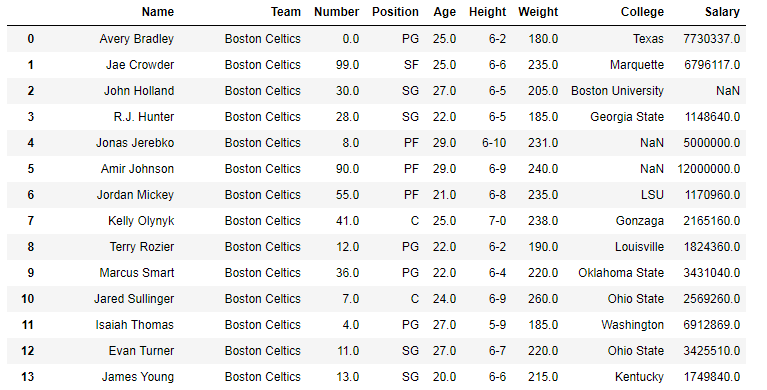
You can also perform statistical data analysis on a dataframe using the describe() method
# removing null values to avoid errors
>>> data.dropna(inplace = True)
# percentile list
>>> perc =[.20, .40, .60, .80]
# list of dtypes to include
>>> include =['object', 'float', 'int']
# calling describe method
>>> desc = data.describe(percentiles = perc, include = include)
# display
>>> desc
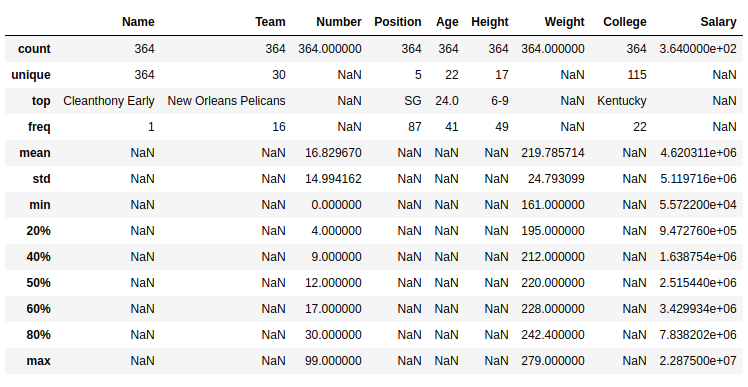
Source: (https://www.geeksforgeeks.org/python-pandas-dataframe-describe-method/)