Systems - foxymoron/test GitHub Wiki
Below are the 3 types of algorithms.
-
Round robin: distribute requests to each replica in turn. -
Least loaded: maintain a count of outstanding requests to each replica, and distribute traffic to replicas with the smallest number of outstanding requests. -
Peak EWMA: maintain a moving average of each replica’s round-trip time, weighted by the number of outstanding requests, and distribute traffic to replicas where that cost function is smallest.
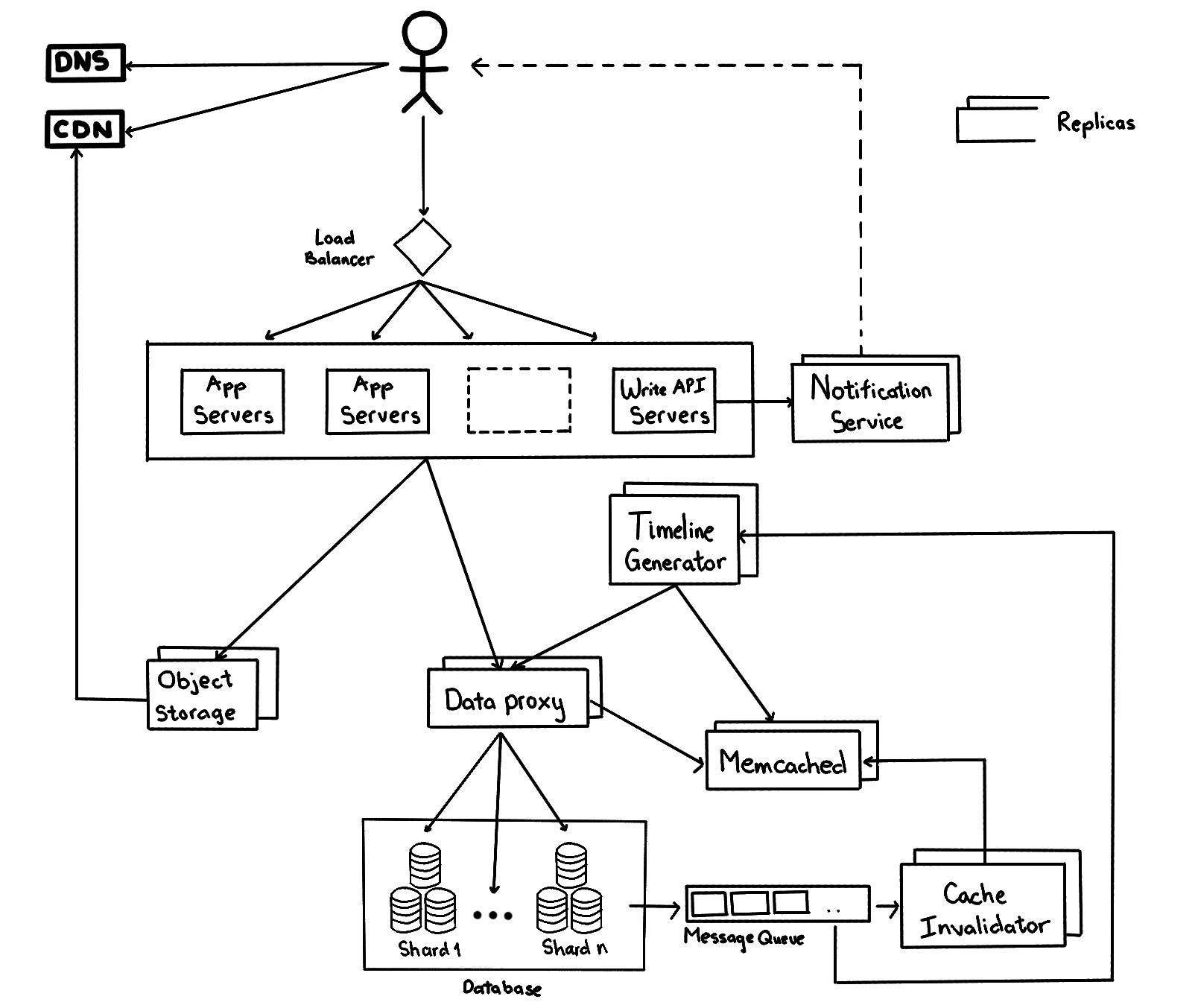
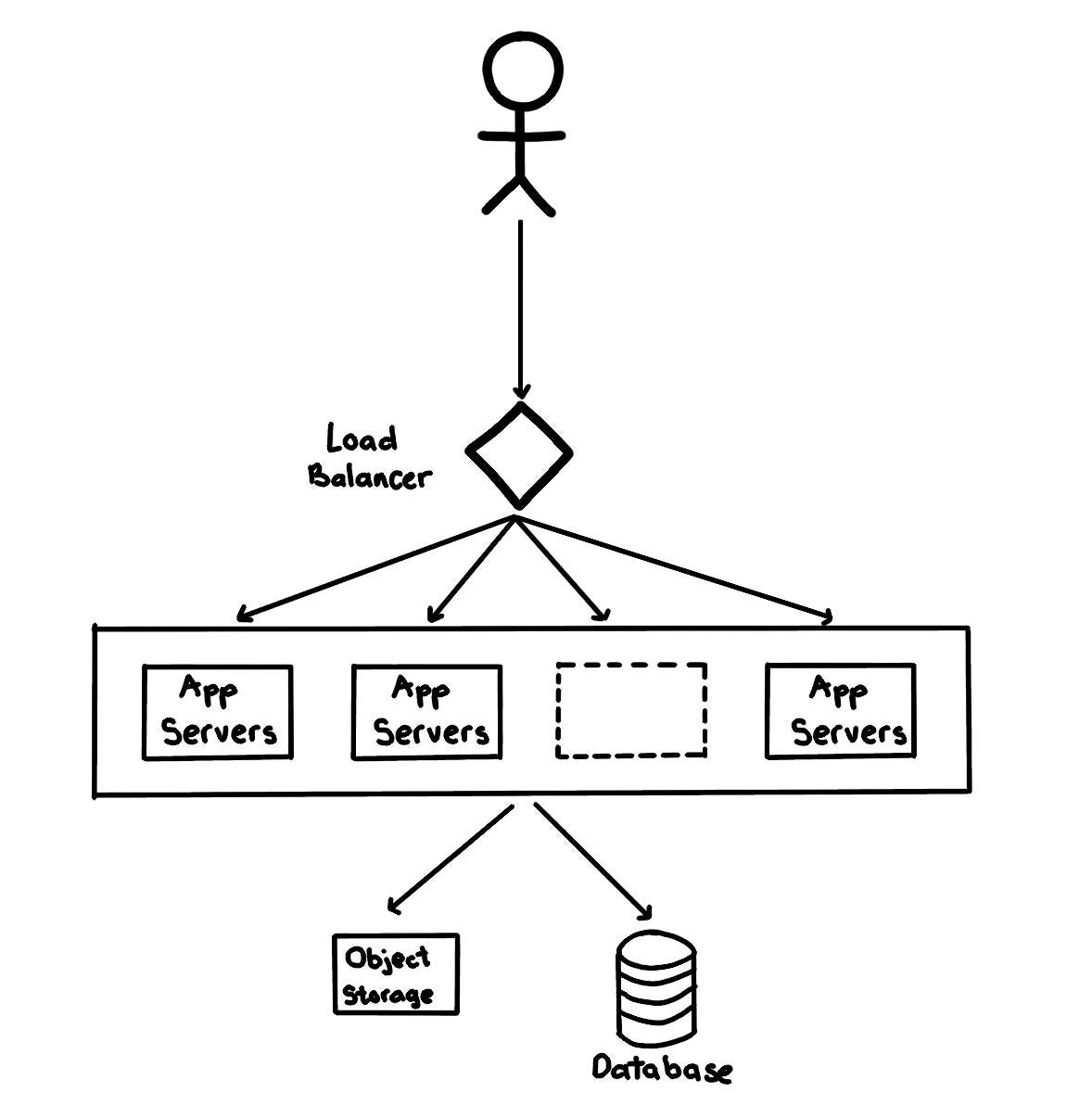
Step 1: clarify requirements (functional & non-functional) Step 2: define system APIs Step 3: sketch the high level system design Step 4: discuss database & storage layer Step 5: discuss core components Step 6: add in high availability considerations and finalise the design.
- user can post tweet
- user can follow people
- user must be notified of new tweets from their followees
- user timeline feed must be generated based on followees activities
- 1B total users, 200M daily active users
- 1 user posts 1 tweet/day and views 100 tweets/day
- 1 tweet contains upto 140chars. Avg. size is 0.3KB (2bytes per char + metadata eg. timestamp, userid etc...)
- 20% tweets contain photos (avg. size 200KB)
- 10% tweets contain videos (avg. size 2MB)
- 1 celeb may have 100M followers
- Timeline should be retrieved as fast as other requests. (Latency < 200ms)
- Service has high availability
- new tweets per day: 200M * 1 = 200M
- average size of a tweet: 0.3KB + 20%*200KB + 10%*2MB = 250KB
- storage per day: 200M * 250KB ~= 50 TB / day (5 years is about 91250 TB)
- keep 20% daily data in memory for caching: ~= 50TB * 0.2 = 10TB
- write bandwidth: 50TB per day ~= 500MB/second
- read bandwidth: ~= 100x write access ~= 50GB/second
- write rps: 200M / per day ~= 2.3k/second
- read rps: ~= 100x read rps ~= 230k/second
GET /api/users/<username>
GET /api/users/<username>/tweets?page=1&per_page=30
GET /api/users/<username>/followers?page=1&per_page=30
GET /api/users/<username>/followees?page=1&per_page=30
POST /api/users/<username>/tweets
POST /api/users/<username>/followers
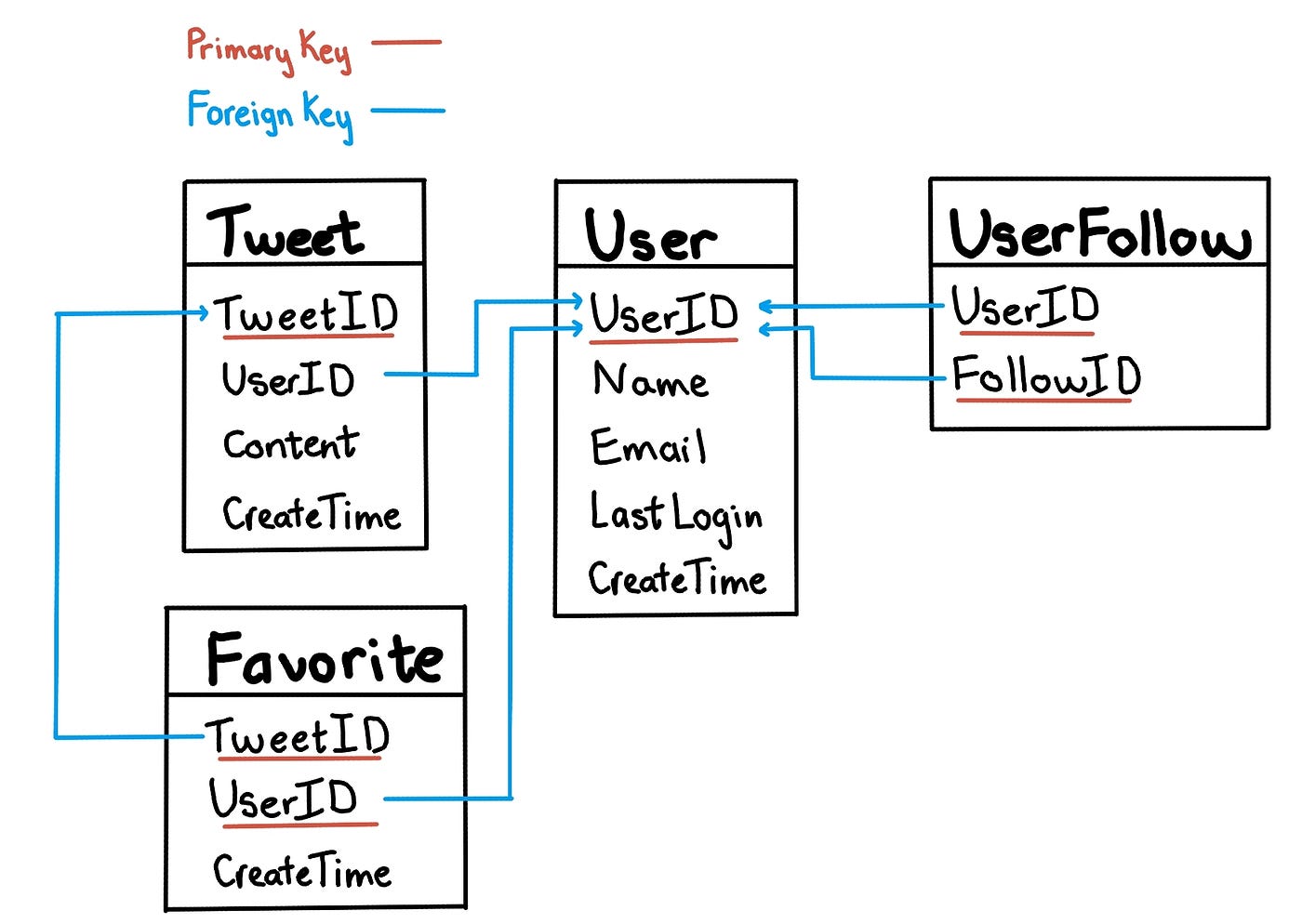
Straightforward option:
- Use MySQL
- But need to handle 2.3k rps write access and 230k read access, the performance will be an issue for SQL databases. Alternate option:
- Use NoSQL
- store the above schema in a distributed key-value store to enjoy the benefits (such as db-level sharding) For relationship b/w users & followers:
- use a wide-column datastore like Cassandra to keep the information,
- the ‘key’ would be ‘UserID’ and the ‘value’ would be the list of ‘FollowID’, stored in different columns
- Cons: difficult to handle complex relationship queries, storing redundant data and more expensive than relational databases Another option:
- keep using relational databases and add data sharding logic layer as well as data cache.
- Some famous companies like Twitter and Facebook manage to use relational databases for handling much bigger loads than what we have in this problem.
one single database server can’t handle the load, we need to distribute our data into multiple machines in order to read/write it efficiently
-
Sharding based on UserID: based on hashing UserID, we map each user to a server where stores all of the user’s tweets, favorites, follows, etc. This approach does not work well if users (such as celebrities) are hot and we end up to have more data and access on a group of servers compared to others. -
Sharding based on TweetID: based on TweetID, we map each tweet to a server which stores the tweet information. To search for tweets, we have to query all servers, and each server will return a set of tweets. This approach solves the problem of hot users, but, increase the latency as we need to query all servers. -
Sharding based on TweetID & create time: generating TweetId based on the create time (such as, a TweetID of 64-bit unsigned integer which has two parts, the first 32 bits is unix timestamp, the last 32 bits is an auto-incrementing sequence). We then shard the database based on TweetId. This approach is similar to the second approach and we still need to query all servers to search for tweets. However, the latency is improved as we don’t need a separated index for timestamp (we can just base on the primary key TweetId) when sorting tweets by create time.
230k rps of read access is a very large scale. Reduce the latency further by introducing a data proxy in front of database servers to cache hot tweets and users. Application servers query data from a data proxy which quickly check if the cache has desired tweets before hitting the database.
-
cache size: 20% of daily data (10TB) is a good starting point. When the cache is full and we want to replace a tweet with a newer/hotter tweet, so Least Recently Used (LRU) is a reasonable policy for this system. -
cache invalidation: we can monitor the changes in database (such as read the mysql bin logs), put the changes in a message queue, and design a service to pick up the queue message and clear the related data cache. For example, clear all cache with the prefix uid_1234_* when the user of UserId 1234 changes his nickname. There may be a short delay in the update, but it will be fine in most cases.

Tweets may contain media (photos and videos). While the metadata can be saved in the database, distributed object storages (such as HDFS or S3) should be used to store photo and video contents.
Timeline should contain most recent posts from all the followees.
-
It will be super slow to generate the timeline for users with a lot of follows as the system have to perform querying/merging/ranking of a huge number of tweets. Hence, the system should pre-generate the timeline instead of generating when user loads the page.
-
There should be dedicated servers that are continuously generating users’ timeline and storing them in memory. Whenever users load the app, the system can simply serve the pre-generated timeline from cache. Using this scheme, user’s timeline is not compiled on load, but rather on a regular basis and returned to users whenever they request for it.
-
With 1 billion users, if we pre-generate the timeline for all of them, the system needs a huge memory. Moreover, there are usually a lot of users that don’t login frequently, it is a waste to pre-generate timelines for them. One way to improve it is to pre-generate the timeline based on users’ action and history logs. We can build a simple machine learning model to figure out the login pattern of users and pre-generate their timelines.
If the system treats all users the same, the interval of timeline generation for a user will be long and there will be a huge delay in his timeline for new posts. One way to improve that is to prioritise the users who have new updates. The new tweets are added in the message queue, timeline generators services pick up the message from the queue and re-generate the timeline for all followers.

-
Pull model: clients can pull the data on a regular basis or manually whenever they need it. The problem of this approach is the delay in updates as new information is not shown until the client issues a pull request. Moreover, most of the time pull requests will result in an empty response as there is no new data, and it causes waste of resources. -
Push model: once a user has published a tweet, the system can immediately push a notification to all the followers. A possible problem with this approach is that when a user has millions of followers, the server has to push updates to a lot of people at the same time. -
Hybrid: we can combine both pull and push model. The system only pushes data for those who have a few hundred (or thousand) followers. For celebrities, we can let the followers pull the updates.
Instances of the app server might be located in different data centers at different physical locations. We can add geolocation-based policy DNS to provide the client with a server IP address that is physically located closer to the client.
A content delivery network (CDN) is a globally distributed network of proxy servers, serving content from locations closer to the user. We can serve tweet media contents via CDN to improve user experiences.
We need to ensure no data loss in the service. Hence, we need to store multiple copies of each file so that if one storage server dies we can retrieve it from the other copy present on a different storage server. The same principle can be applied to other parts. We can have multiple replicas of services running in the system, so if a few services die down, the system still remains available and running. If only one instance of a service is required to run at any point, we can run a redundant secondary copy of the service that is not serving any traffic, but it can take control after the failover when primary has a problem.