1.04 Lezione 4 - follen99/ArchitetturaDeiCalcolatori GitHub Wiki
📅 03-12
Diversi computers hanno diversi insiemi di istruzioni (instruction set), ma hanno molti aspetti in comune; ad esempio, i primi computers avevano un instruction set molto semplice, oppure alcuni sistemi embedded non forniscono il supporto per le operazioni a virgola mobile, ecc.
I processori dei telefoni non hanno grandi capacità di gestire i numeri reali (floating point), e non hanno quindi un'unità hardware per l'utilizzo del FP.
I set di istruzioni sono proprietari, quindi non è possibile costruire un processore compatibile con intel senza pagare le cosiddette fees. Ultimamente l'open source è passato dal software all'hardware, quindi fornire l'intera documentazione del set di istruzioni e del processore stesso.
E' proprio in questo modo che è nata la fondazione RISC-V, dove è stato progettato un set di istruzioni moderno e completo, e sopratutto open source. Nei sistemi embendedd questo processore potrebbe facilmente essere diffuso, proprio perchè si presta bene all'apprendimento. Questo perchè è di una struttura molto semplice, e sopratutto modulare.
ADD a, b, c -> a riceve b + c
Questi operandi devono necessariamente di tipo registro; infatti i processori come il RISC hanno operazioni aritmetiche che lavorano solo ed esclusivamente su registri.
Il RISC ha un set di registri costituito da 32 registri; la versione più avanzata utilizza registri a 64 bit, mentre nella versione utilizzata in questo corso vengono usati registri a 32 bit.
Solitamente i registri a 32 bit vengono chiamati word, mentre quelli a 64 doubleword. I registri sono il dispositivo di registrazione più veloce che esista, proprio perchè sono situati proprio all'interno del processore, quindi non c'è bisogno di interfacciarsi con altri componenti del computer.

Chi ha realizzato il processore, ha avuto la cura di separarli in vari "blocchi", in modo che ogni blocco di registri possa essere utilizzato per una funzione diversa. Questo non vuol dire che i registri siano fisicamente diversi, ma è buona norma, per il programmatore, di usare i registri per quello che sono stati ideati.
Abbiamo anche dei nomi di tipo simbolico, come X1 -> ra; questi nomi vengono definiti nella ABI, application binary interface, trovabile quì.
Gli intervalli non sono stati scelti in modo adiacente per il semplice fatto di facilitare la programmazione a 16 bit.
- Registri S questi registri devono essere usati per memorizzare delle informazioni che vogliamo conservare. Ad esempio dobbiamo usare i registri S quando dobbiamo memorizzare il risultato di un'operazione (o ritornare da un jump).
- Registri T questi registri devono essere usati per memorizzare delle informazioni temporanee, informazioni che potrebbero essere sovrascritte senza problemi.
In C, ad esempio, possiamo utilizzare delle variabili globali (dichiarate in testa, fuori dalle funzioni) e sono visibili a tutte le linee di programma al di sotto della loro dichiarazione, e. sono poste in un'area in memoria detta globale; non hanno a che fare con lo stack, quindi quando entro ed esco dalle funzioni, il valore delle var globali rimane inalterato.
Le variabili che invece vengono dichiarate ed utilizzate dalle funzioni vengono ogni volta reistanziate sullo stack. Queste in C vengono dette variabili automatic che sono allocate sullo stack. Questa struttura dati ha un'organizzazione a pila, quindi lo stack si "gonfia" e "riduce" via via che le funzioni vengono chiamate. La struttura è di tipo LIFO.
Infine, abbiamo della memoria gestita dinamicamente, quindi quando avvio il programma non sono a conoscenza di quanta memoria avrò bisogno, quindi utilizzerò la funzione malloc, e questi dati verranno posti all'interno di un'altra area di memoria, chiamata heap. In questo caso, la malloc funziona in modo diverso dallo stack, proprio perchè possiamo allocare e deallocare memoria nell'ordine in cui vogliamo noi. In java ogni volta che creiamo un oggetto, quest'oggetto va a finire sull'heap, quindi tutta la gestione degli oggetti (tutti i new) creano oggetti che vengono posti nell'heap della mappa in memoria del programma in esecuzione; quando l'oggetto non serve più e viene deallocato, l'heap va opportunamente "pulito" (garbage Collection).
Il processore utilizzato nel corso, il RISC-V, è di tipo Load-Store; questo significa che per eseguire delle operazioni è necessario prelevare dalla memoria (caricare nei registri), eseguire, e poi caricare nuovamente in memoria il risultato. Quindi non è possibile eseguire operazioni (aritmetiche) direttamente nella RAM.
A differenza dei processori antichi, che leggevano dalla memoria un solo byte per volta (8bit), leggono a 4/8 byte per volta (32 o 64 bit). Siccome i byte in memoria sono sequenziali (almeno logicamente, hehe) devo specificare l'indirizzo di inizio, o quello di fine.
- Little endian questo modo di indicare l'indirizzamento proviene dal libro "i viaggi di Gulliver". Le popolazioni che lui incontrava, dibattevano sul modo con cui "rompere l'uovo", ovvero romperlo dalla parte più stretta o dalla parte più larga. Vengono chiamati "little endian" o "big endian". Quindi "little endian" vuol dire inserire nel registro i bit dalla parte meno significativa (la parte meno significativa è la parte dove ci sono i bit che valgono 1-2-4-8- ...) Il RISC-V utilizza la convenzione little endian, quindi il byte meno significativo viene posto all'indirizzo più piccolo di una word. Man mano che aumentiamo l'indirizzo della memoria troviamo valori sempre più grandi.
- Big Endian altri processori pongono il byte più significativo all'indirizzo più piccolo.
Il RISC V non richiede che le word siano allineate in memoria.
Molti processori "semplici" quando devono prendere una sequenza di 8 byte, possono prenderlo solo su un indirizzo che sia multiplo di 8, ad esempio non possiamo prelevare all'indirizzo 03, ma per forza agli indirizzi 07 o 15.
Tutto questo, quindi, NON E' richiesto l'allineamento. Possiamo quindi prelevare un po' dove vogliamo.
A[12] = h + A[8];In C è abbastanza chiaro che A, oltre ad essere un puntatore, è l'indirizzo di partenza dell'array. Supponiamo che h sia stato posto nel registro s5, ed in s6 è già stato caricato l'indirizzo di partenza dell'array.
Per accedere all'elemento A[8] in Assembly, e gli int siano rappresentati su 64 bit, devo moltiplicare 8 per lo spiazzamento di 8, ed ottenere quindi l'offset che indica dove si trova A[8]:
- A[0] = A
- A[1] = A + 8
- A[2] = A +16
- A[8] = A + 64
Quindi essendo ogni posizione 8 byte, dobbiamo andare a pescare alla posizione 64.
Per caricare la posizione in un registro, usiamo l'istruzione Load (ld); inoltre lo spiazzamento viene posto davanti al registro dove è contenuto l'indirizzo di memoria all'inizio dell'array (puntatore all'array).
ld s1, 64(s6) # Carico nel registro S1 il contenuto di A[8]
add s1, s5, s1 # sommo in s1 il contenuto di s1 + s5
sd s1, 96(s6) # salvo in a[12]
sdsta perstore doubleword
Siccome il RISCV utilizzato durante il corso funziona a WORD e quindi 32bit, verranno usati lw e sw; inoltre, gli offset dovranno essere moltiplicati per 4, e non 8.
🏁 1:05
I registri sono ovviamente molto più veloci della memoria RAM. Se devo operare su variabili presenti sulla RAM, devo effettuare dei caricamenti e dei salvataggi, quindi load e store. Un utilizzo intensivo dei registri può evitare di accedere troppo spesso alla memoria.
Se ho delle variabili semplici, il compilatore può tentare di mantenerle permanentemente in uno dei registri disponibili, in modo di evitare gli accessi in memoria.
Come visto precedentemente, possiamo utilizzare delle istruzioni per rendere più velece l'utilizzo di costanti piccole:
addi s6, s6, 4 # eseguo una somma tra il registro s6 e '4'Con questo sistema 4 non deve essere preso dalla memoria, e può essere direttamente scritto all'interno dell'istruzione
Nei calcolatori si utilizza praticamente sempre la rappresentazione per complemento a due; è una tecnica che permette di rappresentare i numeri interi negativi senza usare il segno, e consente di rendere più semplici i circuiti addizionatori.
Possiamo quindi utilizzare lo stesso circuito addizionatore sia per le somme che per le sottrazioni.
L'unica differenza tra la rappresentazione binaria e quella a complemento a due, è quella che il bit più significativo funziona da segno. Nel momento in cui quel bit è zero è un numero binario normale; quando invece esso è uno, allora il numero è negativo.
Con questa notazione è possibile rappresentare -2n-1 fino a 2n-1-1 (per via dello zero), ovvero tutti i bit tranne quello più significativo utilizzato come segno.
Come cambiare di segno un numero?
Basta semplicemente complementare le cifre bit a bit e sommare 1. Complementare significa cambiare il bit: 0->1 e 1->0.
Poniamo il caso di dover copiare un numero a 32 bit in un registro a 64, come faccio?
- Se il numero è positivo pongo tanti zeri davanti al numero fino a riempire tutti i 64 bit
- Se il numero è negativo questa tecnica non è fattibile, proprio perchè il numero diventerebbe positivo; La tecnica è la seguente: bisogna prendere il bit più significativo ed estenderlo. Quindi, se il bit è zero riempio con degli zeri, se è uno riempio con tanti "uni".
L'instruction set del RISC fornisce due istruzioni:
-
lb"load byte", serve per caricare un byte in un registro (8bit). In questo caso avviene l'estensione del segno. -
lbu"load byte unsigned", se ad esempio nel char (1 byte) è presente un carattere, va caricato dalla memoria al registro con lbu.
Quindi Per caricare in memoria qualcosa che proviene da una stringa di caratteri va utilizzata quindi lbu.
Quando il programma va in esecuzione, come saranno rappresentate le istruzioni in memoria?
Le istruzioni vengono ovviamente codificate in binario, in particolare questo tipo di codice viene detto codice macchina, e le istruzioni del RISC sono a 32 bit. Ci sono processori che utilizzano una lunghezza variabile delle istruzioni, ma non è questo il caso.
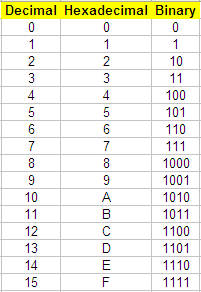
Invece di utilizzare una lunghissima (32 bit) sequenza di numeri binari, possiamo raggruppare in 4 cifre binarie, e rappresentarle in esadecimale.
1110 1100 1010 1000 0110 0100 0010 0000 Binario
E C A 8 6 4 2 0 Esadecimale

Noi studiamo l'R-type o R-Format
Un'istruzione del tipo add s1,s4,s5 diventa codificata in bit:
000 0001 0101 1010 000 0100 1011 0011
| func7 | rs2 | rs1 | Funct3 | rd | opcode |
|---|---|---|---|---|---|
| 0000000 | 10101 | 10100 | 000 | 01001 | 0110011 |
| 0 | 20 | 20 | 0 | 9 | 51 |
Cosa significano questi valori?
- l'opcode è 51
- rd corrisponde al registro s5, che è anche noto come X5
- ...
FINE LEZIONE 4