1.03 Lezione 3 - follen99/ArchitetturaDeiCalcolatori GitHub Wiki
Memoria volatile: questo tipo di memoria, come la RAM è detta "volatile", proprio perchè nel momento in cui il dispositivo non è più alimentato i dati vengono azzerati.
Memoria non volatile: questi dispositivi sono detti "non volatili" perchè possono immagazzinare permanentemente (con la possibilità di sovrascrittura ed eliminazione) i dati; un chiaro esempio sono i dischi magnetici degli HD o gli SSD.
Con gli anni, la ram è andata aumentando precipitosamente.
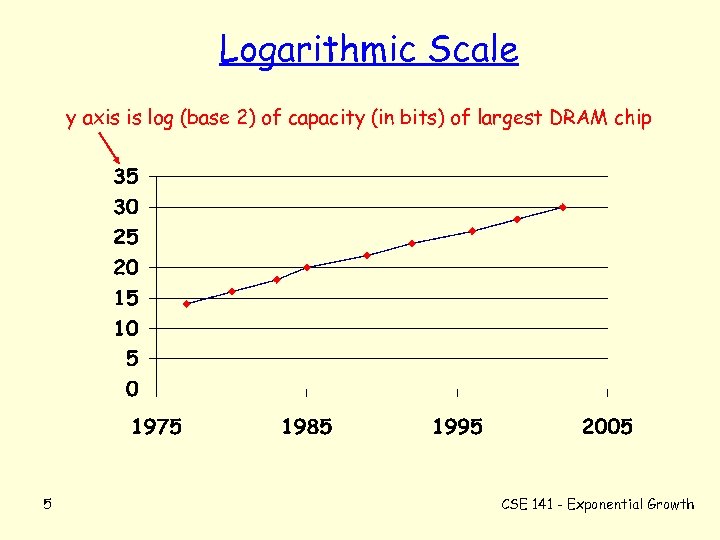
Questa figura mostra l'aumento dei chip di RAM dinamica negli ultimi anni; la scala sull'asse y è logaritmica, quindi anche se non sembra, l'aumento è esponenziale.
La velocità di accesso, invece, non è così impressionante; questa velocità è si aumentata, ma non esponenzialmente.
I produttori delle RAM hanno ritenuto che il miglioramento dei dispositivi risiedeva nella quantità, e non qualità. I dispositivi RAM che invece hanno aumentato la loro velocità sono i dispositivi di tipo SRAM.
Tutti i circuiti integrati utilizzati attualmente, sono basati sulla tecnologia del silicio. Questo materiale è abbondantemente presente in natura (non nel 2021 a quanto è sembrato), ed è un semiconduttore, nel senso che conduce o meno la corrente aggiungendo impurità in laboratorio; con questa tecnica è possibile creare i famosi circuiti integrati.
🏁 03-10 00:13
Il tutto parte da lingotti di silicio che sono di forma cilindrica. Successivamente lo slicer produce delle fettine sottilissime che vengono dette wafer.
Ognuna di queste fettine di silicio, viene opportunamente trattata, in modo da realizzare diverse zone.
Alla fine del ciclo di produzione abbiamo dei wafer sui quali sono già presenti dei chip che svolgeranno un compito.
Dopo aver ottenuto i vari wafer completi, questi vengono ulteriormente suddivisi in sezioni quadrate, ed il prodotto ottenuto è detto die, al plurale dies. Avviene molto spesso che questi dies siano malfunzionanti, ed è in questa fase che vengono testati, e nel caso, scartati.
Questi dies vengono posti in un contenitore (ovvero l'housing del processore) chiamato package, che contiene tutte le connessioni che dovranno essere esposte all'esterno tramite i pin.
I processori vengono ulteriormente testati, ed ancora una volta vengono scartati i processori malfunzinoanti.
Come abbiamo visto molti dei chip vengono scartati, inevitabilmente ci sono delle parti del wafer che non sono funzionanti.
Lo Yield è la proporzione dei dies funzionanti per wafer: se abbiamo una resa dell'80% vuol dire che il 20% del wafer va "buttato".
Più è grande il Chip finale, più lo Yield si abbassa, proprio per una questione di proporzioni.
Attualmente, la tecnologia è arrivata a creare dei chip a 7 nanometri, il che vuol dire che la dimensione più piccola che posso utilizzare su un wafer è proprio di 7 nanometri.
Ovviamente, più la tecnologia è piccola più transistor è possibile inserire all'interno del processore.
Come possiamo definire le prestazioni di un sistema di calcolo?
Ad esempio, se prendiamo in considerazione un aereo, possiamo scegliere vari parametri su cui "valutarlo", come ad esempio il numero di passeggeri, la velocità di crociera, range, ecc.
Quindi, a seconda di quello in cui siamo interessati, scegliamo di prendere in considerazione un parametro invece che un altro, anche nel mondo dell'informatica.
Il throughput descrive il numero totale di qualcosa eseguito in una certa unità di tempo, in altre parole, è il tasso di produzione. Esempio: sono un gommista; il mio throughput è il numero di gomme cambiate in un ora.
Per tempo di risposta, invece, si intende il tempo dall'inizio alla fine per fare qualcosa. Esempio: devo cucinare un piatto di pasta; il tempo di risposta sarà il tempo che impiego a prendere la pasta, scaldare l'acqua, bollire la pasta, ecc.
Se abbiao un programma di tipo scientifico, e dopo ore di calcolo restituisce un risultato.
In questo caso, a cosa siamo interessati, al tempo di risposta o al throughput?
Ovviamente in questo caso siamo ovviamente interessati al tempo di risposta, proprio perchè il risultato che ci interessa è singolo.
Poniamo invece il caso di essere su un sito web, dove è presente un server che esaudisce varie richieste. Un server web è sempre in attività, ed in questo caso ci interessa quindi il suo throughput, ovvero il numero di richieste che riesce ad esaudire per unità di tempo.
Possiamo definire le prestazioni come l'inverso del tempo di esecuzione.
Capiamo quindi che l'indice di prestazione è tanto più elevato quanto più è piccolo il tempo di esecuzione.
Una volta definite le prestazioni, come posso dire che questo sistema è n volte più veloce dell'altro?
Ovviamente devo eseguire il rapporto tra l'indice di prestazione di un sistema x e l'indice di prestazione di un sistema y. Questo significa fare il rapporto tra gli inversi, quindi il tempo di esecuzione su y è n volte tanto.
Esempio supponiamo che il tempo di esecuzione sia il tempo necessario per far girare un programma dall'inizio alla fine. Questo programma gira in 10 secondi su A ed in 15 secondi su B.
Il tempo di esecuzione su B, rispetto al tempo di esecuzinoe di A, è 15/10, possiamo quindi dire che, con questo indice di prestazione, A è 1.5 volte più veloce di B.
Non esiste un metodo di misurazione univoca del tempo di esecuzione di un programma.
Misuro il tempo da quando faccio partire il programma fino a quando questo termina. Questo viene detto tempo elapsed; Il sistema, però, aggiunge un overhead al tempo di esecuzione di un programma, quindi non è un tempo reale.
Misurare il tempo in questo modo a volte è necessario, ma bisogna scaricare il sistema da carichi esterni, altrimenti avremo un tempo non reale.
Questo tempo è il tempo speso solo ed esclusivamente quando il programma gira in CPU; non misura i tempi di I/O nè i tempi dove la CPU è impegnata ad eseguire altri programmi.
Misura tutto ciò che viene eseguito nella CPU per conto del programma, come ad esempio aprire files.
Come si misura il tempo di CPU? Ogni volta che un programma entre ed esce dalla CPU si misura il tempo di inizio e di fine e si somma la differenza agli altri tempi registrati fino a quel momento. Alla fine si ottiene il tempo di CPU totale.
L'unico tool che permette di misurare il tempo di CPU di un programma, è utilizzato dal sistema operativo, che raccoglie delle statistiche.
Come rispondere a questa domanda?
Il tempo di CPU è composto da due valori:
- Tempo speso nella CPU dal programma.
- Tempo speso dal sistema operativo per conto del programma.
Se stiamo tentando di ottimizzare il programma, non ci interessa ad esempio il tempo che comprende anche delle operazioni di I/O, ma ci interessa solo il tempo di CPU.
La maggioranza dell'hardware di tipo digitale funziona in maniera sincrona, ovvero abbiamo un segnale che temporizza tutte le operazioni che vengono eseguite.
Se le operazioni sono temporizzate sul fronte di salita del clock, si nota che abbiamo delle operazioni in concomitanza con il rising edge del clock, ed al prossimo ciclo di clock (ovvero la sequenza basso>alto, alto>basso) c'è una nuova operazione.
Come capire la frequenza del clock?
La frequenza è l'inverso del periodo;
Quindi, se abbiamo un clock a 4.0GHz, ovvero 10^9 cicli al secondo, che equivalgono a 4000 MHz;
Se vogliamo ottenere il periodo di clock basta fare l'inverso ed otteniamo 250ps.
Supponiamo di avere un computer A avente un clock della CPU a 2GHz, e che richieda 10 secondi di CPU per eseguire un programma.
A questo punto voglio progettare un computer che mi permetta di diminuire questo tempo di CPU a 6 secondi.
Se aumento la velocità del clock, sono costretto a moltiplicare per 1.2 il numero di cicli (imposto dal problema).
Come posso fare?
Rate di clock = (numero di cicli) / (tempo di CPU)
possiamo quindi calcolare:
cicli di clock A = (tempo cpuA) * (clock rate A)
ottenuti i cicli di clock possiamo calcolare il clock rate B:
[(1.2 * 20 * 10^9) / 6s] = 4GHz
Il numero di cicli di clock necessari per eseguire un programma, è dato dal numero di istruzioni del programma, moltiplicate per il numero di cicli di clock necessario per eseguire un'istruzione.
Cosa determina il numero di istruzioni necessarie per eseguire un programma?
Ovviamente dipende sicuramente dal programma. Un programma semplice avrà meno istruzioni di un programma molto complesso.
Dipende anche dall'architettura del processore, o meglio dal suo ISA, ovvero instruction set architecture.
Inoltre, non tutte le istruzioni hanno bisogno dello stesso numero di cicli di clock, ma si può fare una stima eseguendo una media.
Big picture
Il tempo di CPU dipende dal numero delle istruzioni eseguite dal programma, dal numero di cicli di clock per istruzione (CPI) ed il numero di secondi necessari per un ciclo di clock.
Se moltiplichiamo tutti questi fattori otteniamo il CPU time.
Inoltre le performance dipendono
- Algoritmo influenza il CPI, alcuni algoritmi potrebbero tendere a privilegiare delle istruzioni facilmente implementabili, altri invece no.
- Linguaggi di programmazione ovviamente influenza il tipo di istruzioni da eseguire, e quindi il tempo.
- Compilatore che ha influenza sia su CPI che sul conteggio del numero delle istruzioni
- Architettura del processore: ovviamente il più importante, influenza infatti tutto.
Con il passare degli anni, la frequenza dei processori è aumentata esponenzialmente, fino ad arrivare ai primi del 2000, dove la frequenza ha avuto un arresto (principalmente da Intel); questo perchè c'è stato un aumento di core, più che di frequenza. Questa soluzione ha generato una svolta nel settore informatico, con un aumento delle prestazioni impressionanti.
D'altra parte, la potenza consumata da parte di questi processori, è andata via via a diminuire, proprio per l'avvento dei dispositivi mobili.
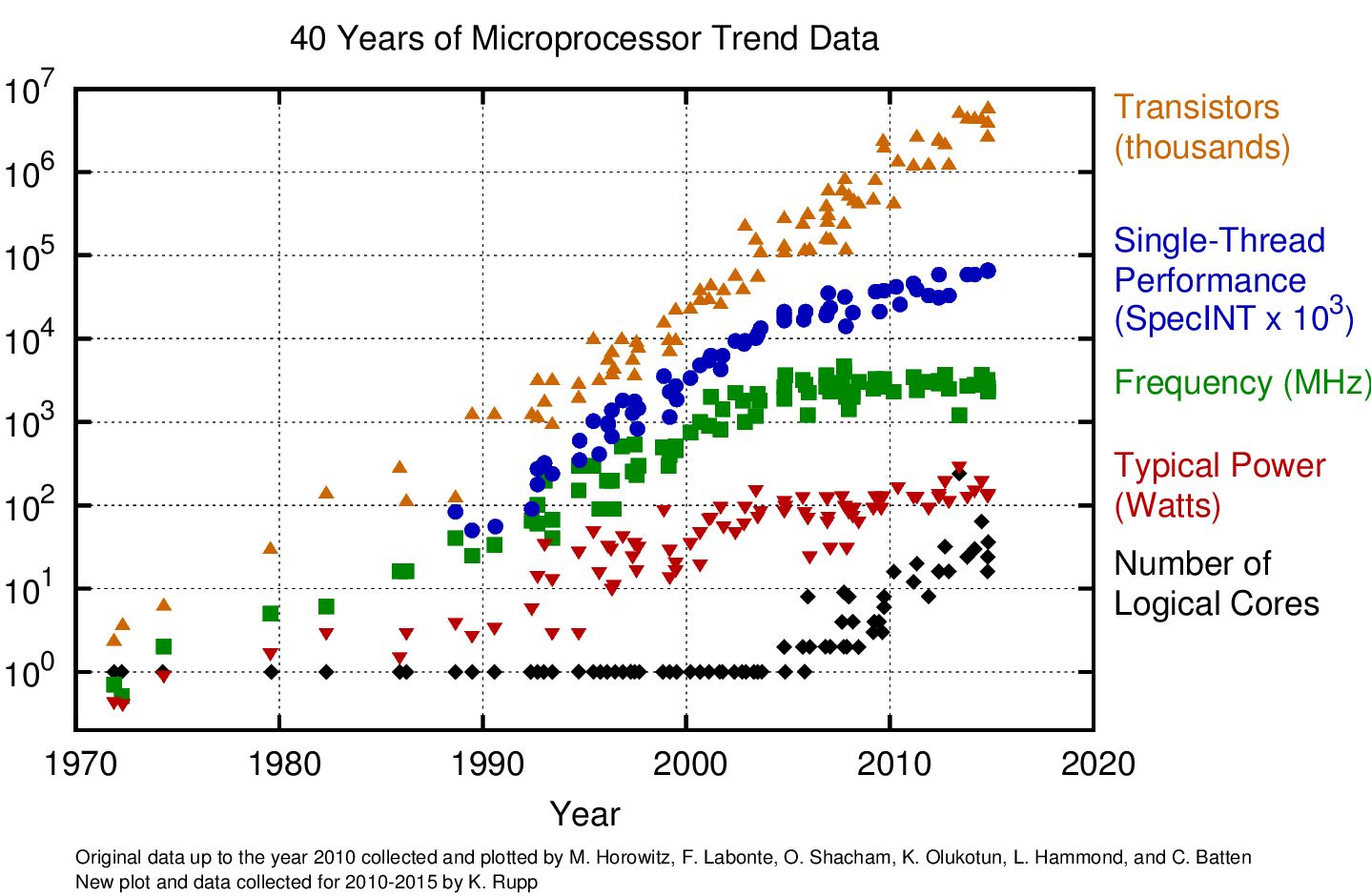
Il problema con l'aumento della frequenza, è la diminuzione della qualità dell'architettura. Questo vuol dire che si, il processore ha un clock enormemente più veloce dei vecchi processori, ma i cicli di clock richiesti per eseguire un istruzione sono di 2/3 volte maggiori.
Come risultato si ha un aumento delle prestazioni reali irrisorie.
L'arresto dell'aumento della frequenza dei processori (avvenuto circa nel 2005), è dovuto al fatto che si è preferito diminuire nuovamente il clock dei processori (non di troppo) e puntare sull'ottimizzazione dell'architettura dei processori.
Questo ha permesso anche la diminuzione della power consumption dei processori.
FINE LEZIONE 3