TG Consultancy Checklist - fieldenms/tg GitHub Wiki
- Abstract
- What to do when starting consultancy
- Conventions and best practices
- What to do before creating a pull request
- What to do when reviewing a pull request
- TODO
This document provides some checklists in an environmentally friendly format for preparing and finalising TG-related consultancy activities.
Although some of the entries refer specifically to TG Air (TTGAMS), the document is applicable to all TG-based applications.
-
Update the TG source (if relevant - in general having the TG source is no longer required during development of TG-based applications, but is required if you are preparing for a release i.e. going to run vulcanisation):
-
Check the current branch and switch to
developif required:git status git checkout develop -
Pull the latest changes:
git pull -
Install the pulled version locally:
mvn clean install
-
-
Update TTGAMS or the relevant project to ensure all changes have arrived - start with the base branch, usually
develop, although if you are implementing changes on top of another branch that has not yet been merged, then use that branch as the base (this should be noted in the issue description):-
Check the current branch and switch to
developif required (substitute the appropriate base branch if notdevelop):git status git checkout develop -
Pull the latest changes:
git pull -
Start IntelliJ, select the project, and then try clicking the "m" button on the toolbar running down the right side of the window and clicking the "Reload All Maven Projects Incrementally" button on the toolbar on the popout window, although whether this works or not is another matter.

-
From the IntelliJ menu, select
Build-Rebuild Project. -
If that does not achieve the desired result (i.e. successful recompilation of the project) you can try selecting
File-Reload All from Disk, then try rebuilding the project again. -
If that still does not work, try selecting
File-Invalidate Caches..., probably select optionClear file system cache and Local History, and clickInvalidate and Restart; then repeat the rebuild.
-
-
Checkout or create the feature branch in, which you will be working.
-
(Recommended) Run all unit tests for the project in, which you are working. This will ensure that the project is clean and operational before you start making changes, and avoid confusion should you implement some changes and later run tests, which undergo upgrade for unrelated reasons. It will also provide a base reference for the current database schema, should any changes be implemented to the model resulting in the need to compare the old and new database schemas in order to write an SQL script to update the schema.
-
Prepare a medium for taking notes. A physical paper notebook was suggested, but an electronic version is also suitable (and would allow for easier copy/paste). A note should be made of the reasons for any significant refactoring so that it can be defended later on.
-
If schema changes are anticipated (such as adding a new entity or property, or adjusting an existing property), extract the current database schema. This will allow comparing the original schema with a schema extracted once changes are complete in order to craft an SQL script to include with the relevant release. Either use a database tool that can generate schema (such a DBeaver, or perhaps proprietary MSSQL tools) or run class
GenDdlto take a snapshot of the schema prior to implementing any changes. If you ran tests in the step above, using a schema extraction tool against the test database is an excellent idea as it exactly reflects the current model, whereas a development database might be a little out of date. -
Add the
In progresslabel to the GitHub issue being addressed.
-
-
 Ensure that the word "ensure" is not used in unit test names.
Ensure that the word "ensure" is not used in unit test names. -
Ensure that all field (property) names start with a lowercase character.
-
Ensure that all method names start with a lowercase character.
-
Do not use a
Headersuffix for entity names (e.g. useInvoiceinstead ofInvoiceHeader). Avoid, where possible, other syntactically sugary suffixes likeNo(e.g.Systeminstead ofSystemNo). -
 Private static final String variable names used as constants for various messages should have uppercase names starting with
Private static final String variable names used as constants for various messages should have uppercase names starting with ERR_(for errors),WARN_(for warnings) orINFO_(for informational/informative messages). An older convention of usingMSG_for informational/informative messages is deprecated, but historical variables named withMSG_are not required to be changed (see link). -
Naming of synthetic entities.
-
Synthetic entities, which represent separate concepts do not require any special prefixes. This includes reports and entities extending persistent entities. Examples:
WorkBoard,PmDashboard,Manpower,InventoryReorder,StockValue(instead of existingReStockValue),PmRoutineCalendar(instead of existingRePmRoutineCalendar). -
Synthetic entities, which extend persistent entities, add additional selection criteria and appear in standalone centres "in place" of persistent entities that they extend, should have prefix
Re. Examples:ReWorkActivity,ReWorkOrder,ReDocument,ReGlTransaction. -
All other synthetic entities should have prefix
Syn. This includes synthetic entities used as properties for special autocompletion logic (e.g.SynSupplierPartandSynReferToinstead of existingReReferTo) and synthetic entities used in embedded centres (e.g.SynRotableNote,SynLocationSubsystemCertificationandSynRotableAndRotablePartAttachment).
-
-
Design pattern for Synthetic Entities with multiple sources.
-
Such entities should have an origin property - refer entity
SynLocationSubsystemCertificationfor inspiration. -
Such entities should not attempt to remove duplicates - refer rows 79-82 in entity
SynLocationSubsystemCertificationfor anti-inspiration. -
Such entities should allow deletion with a meaningful error - refer
SynLocationSubsystemCertificationDao.batchDelete()`` for inspiration, but do not include@SessionRequired`. -
Editing should be possible for all origins - refer rows 444-447 in
LocationSubsystemWebUiConfigfor inspiration.
-
-
-
-
New
Stringproperties should be created including:@IsProperty(length = [positive integer]) @BeforeChange(@Handler(MaxLengthValidator.class)) -
Existing
Stringproperties should be updated to include the above length-related annotations, using the current column length in the database as a reference. -
When adding a new property, check if it would impact any rendering customisers. If so, enhance the rendering customiser/s.
-
When deleting a property, include an SQL script to delete any associated records from tables representing entities like
WaTypeDefault,WorkActivityStatusRequiredPropertyandWorkActivityStatusNotApplicableProperty.
-
-
-
@EntityTitleis necessary in most situations and should include a meaningful description:@EntityTitle(value = "Work Order", desc = "Work Order is usually a job that can be scheduled or assigned to someone.") public class WorkOrder extends ...
-
@Titleis necessary in most situations and should include a meaningful description:@IsProperty @Title(value = "Quality Inspector", desc = "The person performing quality inspection of the work order.") private Technician inspector;
-
All entity and most property titles (with the exception of boolean, refer to the point below) should follow capitalisation rules that are normally applied to titles of newspaper articles: http://grammar.yourdictionary.com/capitalization/rules-for-capitalization-in-titles.html
There is even a website, which does this automagically: https://capitalizemytitle.com/
Abbreviations GST, FX, PO, DC, etc. have to be fully capitalised in both entity and property titles.
-
Titles for boolean properties should avoid excessive capitalisation. Since they contain a question mark at the end, they need to be constructed in such a way that they can be read as a sentence.
@IsProperty @Title(value = "Preferred System only?", desc = "Specifies whether all Systems or only those indicated as Preferred in Rotable Part/System cross-references are used when selecting Rotables based on From/To System.") private boolean preferredSystemaOnly;
Entities titles contained within such titles (i.e.
System) should still be capitalised. -
Titles should not include single quotes (
') as they do not render as expected in the webui. Unicode character \2019 (right single quotation mark) should be used instead. On macOS this can be typed withOpt-Shift-]. On Windows perhaps try some of these suggestions. -
Double quotes should be replaced wtih unicode U+201C (“) and U+201D (”) (left and right, respectively) e.g.
desc = "The State where the “From Bulk Store” is located.". Note that while it is possible to include these characters into string constants using their Unicode codes (e.g.desc = "The State where the \u201cFrom Bulk Store\u201d is located."), it is preferred to include them explicitly, as above. On macOS these can be typed simply by pressing Opt-[ (“) and Opt-{ (”). The equivalent single quote values are typed with Opt-] (‘) and Opt-} (’). For those with a "compose" or "AltGr" key on the keyboard, this post provides a few alternatives to directly type them.
-
-
-
Check whether any data retrieval needs to be instrumental, or can be uninstrumented (i.e. change
co$(Something.class).findByKey(...)toco(Something.class).findByKey()- note the absence of the'$'. See also the page on Fetch Models. Validators and definers should always use uninstrumental versions. Companions should use uninstrumental versions too, unless they intend to modify or save some other entity as part of save(). -
fetchAll()should generally be avoided, unless you know a reason why it should be used.
-
-
-
Ensure that each decision path in the business rules is covered by a separate unit test.
-
Check that all assertions are appropriate, e.g.
assertTrue()is asserting a simple boolean value,assertEquals()is asserting an expected results is the same as an actual result. -
Check that arguments to assertEquals() are in the correct order i.e. expected value first, actual value second.
-
Ensure that
BigDecimalvalues are not compared withassertEquals(). Instead useassertTrue(EntityUtils.equalsEx(...)). This way the scale of values won't affect the comparison result e.g. 0.000 == 0. -
Ensure that
BigDecimalvalues, when compared withassertTrue(...)(as above), are constructed with strings representing the value rather than digits e.g.assertTrue(EntityUtils.equalsEx(new BigDecimal("12.34"), actualValue));. -
@SuppressWarnings("unused") should be avoided, and all warnings suppressed.
-
To avoid unit tests undergoing upgrade when run against an MSSQL database in particular (or PostgreSQL, if the application primarily connects to a PostgreSQL database), ensure that all properties that resemble a "transaction date" and are part of a composite key are populated.
-
Ensure that data population is not being saved to a script, or used from a previously saved script.
-
Ensure that the
constants.setNow(prePopulatedNow);approach is used to set datetime in unit tests. -
Endeavour not to populate fields in valuable (unit) test data that are populated as a result of execution of definers. For example if
Entity.amountis calculated by a definer asEntity.hours * Entity.rate, then by all means populateEntity.hoursandEntity.rate, but do not populateEntity.amount.
-
-
-
When composing a WebUI, ensure that
widthandminWidthare set in such way that column titles do not appear truncated, unless there are some special circumstances. The browser window should be reduced in size horizontally until the horizontal scroll bar just appears, and the column titles checked. -
Ensure that all standard actions are present (e.g. insert, delete, sort, export).
-
Ensure that the same master is displayed when clicking the insert button as when clicking the edit button for an existing row.
-
Ensure that desc is on a separate line in masters, especially when using a multi-line editor.
-
Double-check that small details, like spacing in menu and form titles, have been addressed.
-
When designing Webui layouts for smaller masters, which do not need to take the most of the screen width, please refrain from specifying width in % and specify in (logical) pixels instead - this will ensure that the desired layout is consistent regardless of the screen resolution and browser zoom.
-
Ensure that the centre webui layout dimensions are sufficient to display all criteria, and that there are no empty fields with "Element not found!" warnings.
-
When adding menu items to a compound master, ensure that the
Open<class>ActionDaoconstructor includes a call toaddViewBinding()for the new menu item (to ensure that the icons turn blue when the compound master is opened and there is data present). -
Ensure that custom SVG icons are optimised to keep the size of the vulcanised application at the absolute minimum. For example, using a service like SVGOMG!.
-
Do not include unused icons in the iconsets.
-
Access to entities with only simple masters is still primarily controlled via web menu invisibility.
Note that menu invisibility is per user, not per base user (since the implementation of https://github.com/fieldenms/tg/issues/1734).
If the users who will NOT have access to the menu item are known, list them as shown below. If the users who WILL have access to the menu item are known, make the condition below
AND KEY_ NOT IN ('USERNAME1', 'USERNAME2').For any new menu entries, create an SQL script in TTGAMS/releases with the date and issue number in the filename e.g. 20181101-#1395.sql and add a line like (for MSSQL):
INSERT INTO WEBMENUITEMINVISIBILITY_(_ID, _VERSION, OWNER_, MENUITEMURI_, CREATEDDATE_) SELECT (NEXT VALUE FOR dbo.TG_ENTITY_ID_SEQ), 0, _ID, 'Users%20%2F%20Personnel/Personnel/Person%20Replacement', GETDATE() FROM USER_ WHERE BASE_ = 'N' AND KEY_ IN ('USERNAME1', 'USERNAME2')
or (for PostgreSQL):
insert into webmenuiteminvisibility_(_id, _version, owner_, menuitemuri_, createddate_) select nextval('tg_entity_id_seq'), 0, _id, 'Users%20%2F%20Personnel/Personnel/Person%20Replacement', current_timestamp from user_ where base_ = 'N' and key_ in ('USERNAME1', 'USERNAME2')
The value for MENUITEMURI (sic) is determined from the full menu path (
Users / Personnel/Personnel/Person Replacementin this example), with some special characters replaced with their hex ASCII codes.Note that this populates menu invisibility for the specified users i.e. the named users will not be able to see the menu item.
Another example for TTGAMS/MSSQL, basing a new webui's invisibility on that of an existing webui (rather than based on user), is as follows:
INSERT INTO WEBMENUITEMINVISIBILITY_(_ID, _VERSION, OWNER_, MENUITEMURI_, CREATEDBY_, CREATEDDATE_, CREATEDTRANSACTIONGUID_) SELECT (NEXT VALUE FOR dbo.TG_ENTITY_ID_SEQ), 0, OWNER_, 'Equipment/Administration/Equipment%20Part%2FInventory%20Part', CREATEDBY_, GETDATE(), CREATEDTRANSACTIONGUID_ FROM WEBMENUITEMINVISIBILITY_ WHERE MENUITEMURI_ = 'Equipment/Administration/Rotable%20Part%2FInventory%20Part' GO
-
The following wiki page may be of some use when testing webui functionality: Window management test plan.
-
When testing mobile functionality, narrowing the browser window should trigger use of the mobile layout. However in order to test properly, and to ensure that all icons (in the popout sidebar menu of compound masters) are present, select mobile device emulation in a desktop browser (or test on an actual mobile device if available). Testing in both portrait and landscape modes should be considered.
-
When adding a summary to an EGI (typically with
.withSummary()), the artificial property name should not resemble a real property name. For example for a kount of all rows (when usingCOUNT(SELF)), the artificial property name should betotal_count_. For subtotals (SUM()), the property name should be, perhaps,total_time_instead oftimeTotal.
-
-
-
Ensure that method getAllEntities() is only used when it is certain that a limited number of entities will be returned. Otherwise use streaming (see Streaming Data).
-
The following anti-pattern should not be used:
try (final Stream<Something> stream = coSomething.stream(from(query).lightweight().model())) { final List<Something> things = stream.collect(toList()); if (!things.contains(newThing)) { return failure(newThing, ERR_NOT_ACCEPTABLE_THING); } }
Instead, check the existence of
newThingduring query generation and just check if query count equals 1.Alternatively use method
co.exists(query), for example:final EntityResultQueryModel<Rotable> qRotable = select(Rotable.class).where() .prop("rotablePart").eq().val(rotablePart012382).and() .prop("serialNo").eq().val(serialNo).model(); assertTrue(co(Rotable.class).exists(qRotable));
-
Most streams, and all streams involving database queries, must be wrapped in try (), for example:
try (final Stream<StocktakeDetail> stream = co(StocktakeDetail.class).stream(qem)) { stream.forEach(stocktakeDetail -> { // do something with stocktakeDetail }); }
-
-
Please note that security is not a dirty word.
Now that bulk of the security tokens have been created and mapped, each issue has to take care of its own.
-
Ensure that you are not committing any secrets - password, tokens, certificates, credentials, etc. - especially in
.propertiesfiles. -
In the dao, ensure that the save() method is overridden and has the appropriate CanSave token, e.g.:
@Override @SessionRequired @Authorise(GlTransactionType_CanSave_Token.class) public GlTransactionType save(final GlTransactionType entity) { return super.save(entity); }
-
If deletion is supported, do the same for the batchDelete() method with a CanDelete token, e.g.:
@Override @SessionRequired @Authorise(Address_CanDelete_Token.class) public int batchDelete(final Collection<Long> entitiesIds) { return defaultBatchDelete(entitiesIds); }
-
Implement a CanSave token, e.g. GlTransactionType_CanSave_Token.java:
package fielden.security.tokens.persistent; import [...] public class GlTransactionType_CanSave_Token extends AdministrationModuleToken { private final static String ENTITY_TITLE = TitlesDescsGetter.getEntityTitleAndDesc(GlTransactionType.class).getKey(); public final static String TITLE = Template.SAVE.forTitle().formatted(ENTITY_TITLE); public final static String DESC = Template.SAVE.forDesc().formatted(ENTITY_TITLE); }
-
If deletion is supported, implement a CanDelete token, e.g. Address_CanDelete_Token.java:
package fielden.security.tokens.persistent; import [...] public class Address_CanDelete_Token extends StoresAndPurchasingModuleToken { private final static String ENTITY_TITLE = TitlesDescsGetter.getEntityTitleAndDesc(Address.class).getKey(); public final static String TITLE = Template.DELETE.forTitle().formatted(ENTITY_TITLE); public final static String DESC = Template.DELETE.forDesc().formatted(ENTITY_TITLE); }
-
Create an SQL script in TTGAMS/releases with the date and issue number in the filename e.g. 20181101-#1395.sql
-
When migrating security functionality from T64 to TTGAMS, in T64 identify the relevant security string, and then the list of user classes allowed write access to that feature, for example:
SELECT * FROM USER_FUNCTIONS WHERE TF_REFNO IN (SELECT TF_REFNO FROM TRIDENT_FUNCTIONS WHERE TF_DESC = 'Personnel Utilities') AND ALLOW = 'w' ORDER BY USER_CODE
This example results in:
USER_CODE TF_REFNO ALLOW ADMIN 904 w SUPER_TI 904 w SUPERUSE 904 w TRIDENT 904 w -
In the newly created SQL script construct an SQL insert statement like this (specifying the new token and the list of user codes identified above) (for MSSQL):
INSERT INTO SecurityRoleAssociation_(_ID, _VERSION, SECURITYTOKEN_, ROLE_, CREATEDDATE_) SELECT (NEXT VALUE FOR dbo.TG_ENTITY_ID_SEQ), 0, 'fielden.security.tokens.persistent.PersonReplacement_CanSave_Token', _ID, GETDATE() FROM USER_ROLE WHERE KEY_ in ('ADMIN', 'SUPER_TI', 'SUPERUSE', 'TRIDENT')
or (for PostgreSQL):
insert into securityroleassociation_(_id, _version, securitytoken_, role_, createddate_) select nextval('tg_entity_id_seq'), 0, 'fielden.security.tokens.persistent.PersonReplacement_CanSave_Token', _id, current_timestamp from user_rolE where key_ in ('ADMIN', 'SUPER_TI', 'SUPERUSE', 'TRIDENT')
-
-
-
If a new entity is created, or if a new property is added to an existing entity or an existing property is altered, the corresponding database changes must be reflected in an SQL script to be included in the relevant release.
-
Create an SQL script in the
releasesdirectory at the project's top level, with the date and issue number in the filename e.g.20181101-#1395.sql -
Either use a database tool (e.g. DBeaver) or the
GenDdlclass to extract the relevant schema.GenDdl.javacan be modified to connect to the appropriate database by passing a suitableapplication.propertiesfile to it in the run configuration, and should have the relevant entity added to the.generateDatabaseDdl()call near the bottom of the ghoti. A sample run configuration for IntelliJ is as follows (adjust it as required to suit your environment):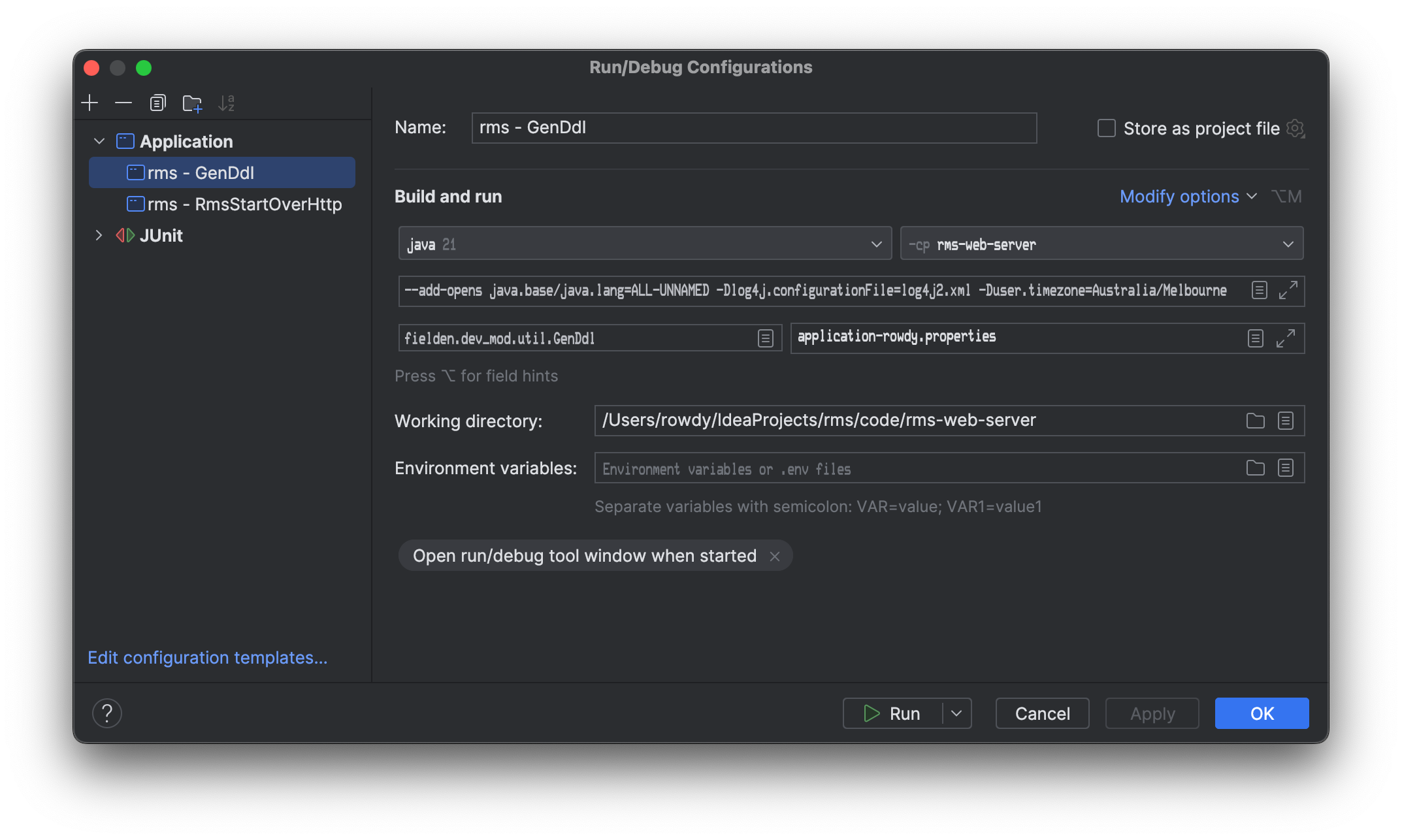
-
Compare the new SQL text with that captured before consultancy commenced, and remove the bits that have not changed. For example if you have added a new property to an existing entity, your final SQL script would simply be an
ALTER TABLE x ADD ystatement (and whatever else was added with it, such as an index or foreign key).
-
-
If activatable dependencies have changed, i.e.:
- Any properties are annotated with, or no longer annotated with,
@SkipActivatableTracking,@SkipEntityExistsValidation(skipActiveOnly = true) - Entities are added or removed from
@DeactivatableDependencies - Properties, which are instances of activatable entities, are added or removed to/from other activatable entities (without any of the above annotations)
Then an SQL script needs to be included to recalculate refcount.
For example, such an SQL script (for MSSQL; for PostgreSQL it would more closely resemble standard SQL) might resemble this:
BEGIN TRANSACTION; UPDATE ROTABLE_ SET REFCOUNT_ = 0; UPDATE ROTABLE_ SET REFCOUNT_ = REFCOUNT_ + (SELECT COUNT(*) FROM EQUIPMENT_ AS DEPENDENT_ WHERE DEPENDENT_.ACTIVE_ = 'Y' AND DEPENDENT_.Rotable_ = ROTABLE_._ID ) WHERE ACTIVE_ = 'Y'; COMMIT WORK; GO
The creation of such SQL scripts can be facilitated by the use of the
GenRefCountSqlclass. It can be run with a run configuration similar to the following:
- Any properties are annotated with, or no longer annotated with,
-
-
-
Any
Moneyproperties that are the subject of database migration must be annotated with.amount. For example, propertiesactualCostandestimatedCostare of typeMoneyand thus annotated with.amount:@Override public SortedMap<String, String> resultFields() { return map( field("workOrder.number", "T.WONO"), field("person.name", "T.CRAFT"), field("actualCost.amount", "COALESCE(T.COST, 0)"), field("actualHours", "COALESCE(T.HOURS_ACT, 0)"), field("estimatedHours", "COALESCE(T.HOURS, 0)"), field("estimatedCost.amount", "COALESCE(T.EST_COST, 0)") ); }
-
Entities with optional composite key members must have all members specified in the retriever, with the optional members yielding null where applicable. This is required because of reliance of the cache to match values by indexes of their key members.
-
Always provide a full field mapping in case of composite entities with a single key member, which effectively replaced
String-based keys.For example, migration of entities with a property of type
Vehicleshould specifyvehicle.numberinstead of justvehicle(because entityVehiclehas aDynamicEntityKeywith one composite key member -number).For another example, in the above ghoti extract can be seen references to
workOrder.numberandperson.name.
-
-
-
Ensure that you check for nulls in definers and validators that pertain to
@CritOnly(Type.SINGLE)properties. Invalid entities cannot be saved, including the cases of required properties having no values. However, entities representing selection criteria can be saved, even if some of the properties that model selection criteria (namely@CritOnly(Type.SINGLE)) are null — this is a feature, not a bug. Hence, when an entity withnullvalues in@CritOnly(Type.SINGLE)properties is loaded, definers for such properties get executed. -
Validators should
return failure(ERR_MESSAGE);rather thanthrow failure(ERR_MESSAGE);. This is partly because in general, if there are validators on a persistent entity, throwing a result from a validator would put that entity into an inconsistent state. -
Ideally validators will check for error conditions before warning conditions. I.e. any
return Result.failure(newValue, ...)should occur beforereturn Result.warning(newValue, ...). -
Validators return a
Result, such assuccessful()orwarningEx(). These support the passing of an extra parameter -instance, however when returned from a validator parameterinstanceis not used and should be omitted. Where aResultis returned from a non-validator,instancemight be used and in such cases should be included, but otherwise should also be omitted. See here for details.
-
-
Grouping properties are used to group the results of reports and analyses. They are typically implemented as entities with an
enumdefining a fixed list of possible values, and displayed to the user as selection criteria in the respective centres.Refer to commits in TG Fleet and TTGAMS for examples.
-
Such entities should be synthetic i.e. have a field
model_ormodels_. -
They should be annotated with
@SupportsEntityExistsValidation. -
The related matcher should always return all values.
-
-
-
"string".formatted(...)is preferred overformat("string", ...).Beware of using formatted on concatenated strings. For example:
final String suggestion = "Hello %s, " + "let's dance %s.".formatted("Friend", "together");may not provide the expected result, and is better implemented as:
final String suggestion = ("Hello %s, " + "let's dance %s.").formatted("Friend", "together"); -
Instead of inheriting a property (e.g.
active) from an ancestor class in order to apply a default, the default can be provided in methodnew_()in the dao. -
Instead of using
BigDecimal.multiply(new BigDecimal("-1.0"))it is possible to useBigDecimal.negate(). -
Ensure TODO items that are done have been removed from the ghoti.
-
Ensure that any
System.out.println();have been removed. -
Without attributing any specific ghoti to any specific consultant, the following pattern:
Eo eo = null; if (!locationSubsystemEoList.isEmpty()) { eo = locationSubsystemEoList.get(0).getEo(); } else { eo = rotableEoList.get(0).getEo(); }
should be replaced by something more like:
final Eo eo; if (!locationSubsystemEoList.isEmpty()) { eo = locationSubsystemEoList.get(0).getEo(); } else { eo = rotableEoList.get(0).getEo(); }
or even something like:
final Eo eo = (!locationSubsystemEoList.isEmpty()) ? locationSubsystemEoList.get(0).getEo() : rotableEoList.get(0).getEo();
-
Ensure that your ghoti complies with the SOLID principle.
-
Check that entitys are compared using
EntityUtils.areEqual()instead of, for example,wa.getWaType().equals(woTypeEO). -
Without attributing any specific ghoti to any specific consultant, the following pattern:
final WorkActivityStatus workActivityStatusF = fetchWorkActivityStatusUsingWaFetchProvider("F"); assertNotEquals(workActivityStatusF, workActivity189510.getStatus());
could be replaced with:
import static fielden.work.common.WorkActivityStatus.FixedStatuses.F; assertNotEquals(F.name(), workActivity101168.getStatus().getKey());
-
Instead of ghoti like
variable.equals(constant)it is safer to useconstant.equals(variable). -
Ensure that properties of type
Moneyare not annotated with(precision = 18, scale = 2)as this is the default. -
Endeavour to not do inside a loop anything that can be done outside a loop, especially database-intensive operations.
-
Ensure that
BigDecimalis never equated to0. Instead always use comparison with0(BigDecimal.ZERO.compareTo(value)). -
Particularly in @Calculated expressions, such as
ifNull().<some expression>.then().val(Money.zero), useMoney.zero(for Money) ornew BigDecimal("0.00")for non-Money i.e. do not useBigDecimal.ZEROas this has a precision of 0 and might not produce the intended result. -
Methods that are only called from one place do not need to be implemented in the dao - they can be implemented exactly (and only) where they are needed. This is to reduce the scope of the methods. Methods that are called from several different places (e.g. business logic and unit tests) should be implemented in the dao.
-
Sufficiently trivial methods can be implemented as a default methods in the companion object interface (e.g.
IWorkActivity) rather than being declared there and implemented in the dao (e.g.WorkActivityDao). This is to facilitate tracing the ghoti at a later date such as when performing criticism. -
It is generally not necessary to explicitly retrieve property.key in a fetch provider as it is implied that the key will be retrieved.
-
Injecting a companion into validators, definers and companions has apparently been deprecated. Instead the co() API should be used, as sort of documented in the respective TG issue. Note that matchers do not provide this functionality and thus may still use injected companions. Also see this commit.
-
Joda-Time's DateMidnight is @Deprecated. You are recommended to avoid DateMidnight and use toDateTimeAtStartOfDay() instead. For more information please refer Recommended use for Joda-Time's DateMidnight and Class DateMidnight.
-
If at all possible, ensure that there are not extra blank lines where they are not required, multiple consecutive blank lines or extraneous trailing spaces. Spaces are preferred over tabs - please ensure that tabs are not inserted and any tabs are converted to spaces.
-
Without attributing any specific ghoti to any specific consultant, when confronted with the following pattern:
final AlternateRotable contraryAlternativeRotable = co(AlternateRotable.class).findByKey(entity.getAlternatePart(), entity.getRotablePart()); if (contraryAlternativeRotable == null) { // do the needful }
it is better to simply do:
final boolean contraryExist = co(AlternateRotable.class).entityWithKeyExists(entity.getAlternatePart(), entity.getRotablePart()); if (!contraryExist) { // do the needful }
Note, however, that the default (platform) implementation invokes
findByKeyAndFetch()to determine if a suitable instance exists. In some casesfindByKeyAndFetch()might be overridden, for example TTGAMSBinDao, to either retrieve and return the existing instance or create a new instance if one does not exist. In those casesentityWithKeyExists()will always returntrue, which is unlikely to be the desired outcome. -
Instead of
if (predicate() == false)useif (!predicate())(and positive equivalent). -
Instead of
if (expression) return false else return trueusereturn !expression(and positive equivalent). -
Instead of
coPerson.currentPerson().getUser()usecoPerson.getUser().Or even
coPerson.currentPerson().orElseThrow(CURR_PERSON_IS_MISSING). -
When enhancing partial query conditions as part of query enhancers and value matchers, exercise caution and care when adding
.or()condition. Partial queries constructed outside these enhancers and matchers may already have some conditions constructed using.and()conditions - adding.or()condition is most likely to produce undesired results.Note that partial queries used as part of user-driven filtering are already enclosed in parentheses in the generated SQL.
-
Instead of declaring a new
ERR_REQUIRED = "Required property [%s] is not specified for entity [%s].", reuse the one now available inMetaPropertyi.e.MetaProperty.ERR_REQUIRED. -
Ensure that
@SessionRequiredannotations are not applied to methods, which areprivate- the methods must be at leastprotectedorpublic. -
Ensure that
@SessionRequiredannotations are not applied to methods of classes, which do not implementISessionEnabledinterface. -
Property bindings that have nothing to do with establishing a database connection should not be put into method
mkDbProps()(inH2DomainDrivenTestCaseRunner.java). Instead they should be put intoDaoDomainDrivenTestCaseConfiguration.java. -
When implementing complex logic as part of EntityDao.save(), especially if it involves modifying other entities, please consider starting with making sure that the entity to be saved is valid before you do anything else:
// Make sure that the entity to be saved is valid before we do anything else entity.isValid().ifFailure(Result::throwRuntime); -
Unless you really know what you are doing, custom matchers should extend
FallbackValueMatcherWith[Centre]Context. Typically, they should be overridingmakeSearchCriteriaModel()and ocassinonally other methods. Only in special cases custom matchers should be extendingAbstractSearchEntityByKeyWith[Centre]Context- in such cases you should really know why you are doing this and not extendingFallbackValueMatcherWith[Centre]Context. -
string.replace()is preferred instead ofstring.replaceAll()where no regular expression is involved - see Micro optimisation: calls to String.replaceAll need to be replaced for details. -
Modules.<MODULE>.newException(...)is preferred overnew <ModuleException>(...). -
CollectionUtil.setOf(...)is preferred over creation of aHashSetas a separate variable. -
Each new sentence in Javadoc and code comments should be placed on a new line. Long sentences can be split by comma where appropriate. This helps when dealing with conflict resolutions.
-
Tip
This section should be read in conjunction with section Preparing PR of the Code and PR reviews wiki page.
-
Do not commit any secrets - password, tokens, certificates, credentials, etc. - especially in
.propertiesfiles. Once committed, such information becomes part of the repository's history even if it is removed in a subsequent commit. Although most of FMS's repositories are private,tgis not, and in some cases other people may be granted access to private repositories. -
(If applicable, typically very early in an application's development cycle, before it has reached GA) Run
PopulateDbfor the project in, which you are working. Ensure it is successful. -
(If applicable i.e. retriever/s were modified and the project is still in the legacy data migration phase) Run
MigrateLegacyDbfor the project in, which you are working. Ensure it is successful.Note: Depending on retriever dependencies, some long-running retrievers can be omitted to optimise the pre-pull request process.
-
Run all unit tests for the project in, which you are working. Ensure they all pass.
At this stage it should be the case that the work you have done is successful in and of itself.
-
Merge from
develop(or from the appropriate ancestor branch).git merge --no-ff origin/develop- It is recommended to recompile (
Build-Rebuild Project) the project to ensure that all changes have been recognised and compiled.
- It is recommended to recompile (
-
(If applicable) Run
PopulateDbagain. Ensure it is successful.-
If it is not successful, it could indicate that some errors were committed into the
develop(or ancestor) branch, or that your changes are incompatible with other changes already committed/merged into thedevelopbranch. -
Any errors you are pretty sure you did not cause should be brought to the attention of the project (mis-)manager.
-
Any errors you probably did cause will need to be rectified before starting the commit process again.
-
-
(If applicable) Run
MigrateLegacyDbfor the project in, which you are working. Ensure it is successful.Note: Depending on retriever dependencies, some long-running retrievers can be omitted to optimise the pre-pull request process.
-
Run all unit tests again. Ensure they all pass.
-
If any do not pass, it could indicate that some errors were committed into the
develop(or ancestor) branch, or that your changes are incompatible with other changes already committed/merged into thedevelopbranch. -
Any errors you are pretty sure you did not cause should be brought to the attention of the project (mis-)manager.
-
Any errors you probably did cause will need to be rectified before starting the commit process again.
-
-
Perform front end testing - ensure it passes.
Note: This is a good opportunity to review the issue requirements and ensure that all have been met.
Note: This is also a good opportunity to capture screenshots of essential parts of the functionality for the preparation of the change overview (TG Air), or for the preparation of release documentation (TG Fleet and WAMS).
-
Double-check that all changes have actually been committed and pushed upwind.
-
For Airways (TG Air -
TTGAMS) - write thechange overviewsection of the issue description, including screen captures of the functionality (where relevant) and some notes that will assist both the pull request reviewer and the end user in assessing the functionality.Note: If the pull request reviewer implements changes during their review that affect the screen captures or the text, it is the responsibility of the pull request reviewer to update the change overview.
-
For SAAS (TG Fleet -
tgfleet) and Watco (WAMS -rms) - write release documentation based on the template in the respectivereleasesdirectory, like unto a change overview, including screen captures of the functionality (where relevant) and some notes that will assist both the pull request reviewer and the end user in assessing the functionality. The release documentation should be named following the patternincident #issue - short description.docx, for example20604 #812 - Support for reset of Rotable readings.docx, and committed into thereleasesdirectory.Note: If the pull request reviewer implements changes during the review that affect the screen captures or the text, it is the responsibility of the pull request reviewer to update the release documentation.
IMPORTANT: Remember to commit the release documentation and push it upwind before proceeding to create the pull request.
-
Create the pull request in GitHub, carefully selecting the base branch (usually it will be
develop, but perhaps not if your feature branch was created from some other branch). Ensure that the textResolve #nnn(referencing the issue number) is included in the pull request description. Nominate one or more reviewers for the pull request - those reviewers should automatically receive an email or other notification advising of their nomination, and the pull request should appear in their list of pending pull requests. -
Remove the
In progressGitHub issue label from the issue that was addressed and add thePull requestlabel. -
Send a more direct message (e.g. via Slack) to the nominated reviewer/s advising that their review of the pull request has been requested.
- Follow the steps in section Performing PR review of the Code and PR reviews wiki page.
If the change is approved:
- Follow the steps in section Approving and merging PR of the Code and PR reviews wiki page.
- Nothing much.