Machine Learning Notes - fcrimins/fcrimins.github.io GitHub Wiki
COlah's blog (todo: read more here)
Wild ML (todo: read more here; kws: reinforcement)
Neural Network Zoo (also in ~/Documents)
{kind=link}
Scikit-Learn Algorithm Cheatsheet (in ~/Documents)
- "Following Microsoft’s vision that AI shall be accessible for all instead of a few elite companies, we created the Microsoft Cognitive Toolkit (CNTK), an open source deep learning toolkit free for anyone to use. Today, it is the third most popular deep learning toolkit in terms of GitHub stars, behind TensorFlow and Caffe, and ahead of MxNet, Theano, Torch, etc."
- "Synthetic gradients are an attempt to ‘unlock’ the layers of a neural network. It works by training a second model to predict the gradients of the first. Clever, right? This means you actually can cut and paste a layer from a different model."
- "Batch normalization is normalization applied to the input. It works on batches of training samples, where it computes the mean and variance of each batch, which are then used to scale the input values. This significantly reduces the training time in feed-forward neural networks."
- The differences were that the MNIST example initializes its hidden layers with truncated normals instead of normals divided by the square root of the input size, initializes biases at 0.1 instead of 0 and uses ReLU activations instead of tanh. By switching to Xavier initialization (using Delip’s handy function), 0 biases, and tanh, everything worked as in the WildML example. (It turns out that what matters most is the initialization of the weights.) This is a simple example of what is often discussed with deep learning methods: they can work amazingly well, but they are very sensitive to initialization and choices about the sizes of layers, activation functions, and the influence of these choices on each other. They are a very powerful set of techniques, but they (still) require finesse and understanding, compared to, say, many linear modeling toolkits that can effectively be used as black boxes these days.
- Mentioned on slide 17
- "Category Embedding" (one-hot dimension reduction) of this Presentation on Feature Engineering
- Faster model training. Less memory overhead. Better accuracy than 1-hot encoding.
- Slide 25 mentions Consolidation Encoding: map different categorical variables to the same varible (e.g. to handle spelling errors!)--real data is messy, free text especially
- Slide 46 mentions Projecting to a Circle: turn single features like <day_of_week> into two coordinates on a circle (FWC - brilliant!)
- Slide 56 NLP: Deep learning (automatic feature engineering) is increasingly eating this field but shallow learning with well-engineered features is still competitive.
- "Entity embedding not only reduces memory usage and speeds up neural networks compared with one-hot encoding, but more importantly by mapping similar values close to each other in the embedding space it reveals the intrinsic properties of the categorical variables"
- "helps the neural network to generalize better when the data is sparse and statistics is unknown. Thus it is especially useful for datasets with lots of high cardinality features, where other methods tend to overfit."
- "'Why is minimizing the negative log likelihood equivalent to maximum likelihood estimation (MLE)?' or, equivalently, in Bayesian-speak: 'Why is minimizing the negative log likelihood equivalent to maximum a posteriori probability (MAP), given a uniform prior?'"
- From Bart
deeplearning.net: Another RBM Tutorial (2/23/17)
- "Because of the specific structure of RBMs, visible and hidden units are conditionally independent given one-another." i.e.
p(h|v) = product_i[p(h_i|v)]and vice versa - "For RBMs,
Sconsists of the set of visible and hidden units. However, since they are conditionally independent, one can perform block [FWC - alternating] Gibbs sampling. In this setting, visible units are sampled simultaneously given fixed values of the hidden units."h_{n+1} ~ sigm(W'*v_{n} + b_v)andv_{n+1} ~ sigm(W*h_{n+1} + b_h) - This article has Theano code attached.
- Gaussian initialization s.t. "With each passing layer, we want the variance to remain the same. This helps us keep the signal from exploding to a high value or vanishing to zero."
- The Xavier initialization formula:
var(w_i) = 1/N_in
- "The reality is very different. Someone willing to employ neural network technologies at the moment (as of January 2017) is forced to do scientific work or at least have an in-depth understanding of neural network methods, despite a number of publicly available technologies created by the brightest and most resourceful minds of our age."
- "After two months of trial and error and parallel experiments with a well-known Python-based framework, we decided to switch to that Python framework and suspend work on the dl4j -based network implementation."
- "At that time, a colleague of mine, Wolfgang Buchner , mentioned that he has recently saw that dl4j had undergone a major re-vamp. We immediately attempted to build an experimental model with dl4j Version 0.7.2 , and within two weeks, we actually succeeded."
- "Dl4j has two strengths when it comes to helping someone at the start: [documentation and community]."
- "In general, I have the feeling that the intention of the dl4j community is to build real applications. Based on my experience with other deep learning communities I feel that their intention is to discuss topics of their PhD thesis, or prove this or that theorem."
- "the dl4j User Interface, or UI. It is a web page automatically created by the framework (with minimal configuration, literally five lines of code) that shows graphs of some parameters during network training"
- (12:28) generative network: <man w/ glasses> - <man> + <woman> = <woman w/ glasses>
- this all done in the latent/encoded vector space and then passed through the generator
- this could also be done for various stock/company characteristic scenarios
- company about to blow up in 1999 + company that didn't blow up in 99 + company in 2017 ... ???
- "What's next is that we want to do better prediction of what happens next, and use that in supervised tasks." (as he showed an image of next frames in a movie, but could just as well be future stock prices I suppose, FWC)
- "Identifying flavors is a process of elimination" [Conversations with Tyler: Mark Miller]
- "It's not about figuring out what flavors you taste; you always start with which flavors you don't taste." Just like learning starts from everything and works towards specifics.
- Everything "learned" in nature is adversarial
- HMOs in breast milk act as decoys for pathogens to attach to thus preventing diseases even as severe as HIV [I Contain Multitudes, p. 96]. The previous page discusses the size of the brain. But why does h. sapiens have so many HMOs? Are they the cause or the effect? Generally speaking, our microbes are our biggest adversaries.
- "Even the most harmonious of symbioses are tinged with antagonism." [I Contain Multitudes, p. 159]
- since accessing hardware resources like GPUs from Docker was difficult and required hacky, driver specific workarounds, the machine learning community has shied away from this option
- we ended up with a solution that was not portable and required that the host’s NVIDIA driver was identical to a second copy of the driver installed within the container
- Thankfully, the nice folks at NVIDIA have rectified this problem by releasing nvidia-docker, a tool for configuring docker to allow GPU access from within containers.
- Practical advice for getting started with RL: Highlights of NIPS 2016: Adversarial learning, Meta-learning, and more [Sebastian Ruder]
- Reinforcement Learning as a Service
- David Silver lectures
- CNN is merely a NN where the operations performed by each layer is a discreet convolution. Architecture is inspiried (imprecisely) by neuroscience (Hubel & Wiesel, 1962 and Fukushima, 1982, Neocognitron)
- 3 main revolutionary ideas: ReLUs (instead of sigmoid), dropout regularization, and GPUs
- Overfitting used to be a big word, but all of those ideas, that the network should be relatively small if you don't have a lot of data, were essentially wrong. (kws: Bayesian, Frequentist)
- The world is compositional: pixels combine to form edges, edges combine to form motifs, motifs assemble to form parts of objects, parts of objects -> objects, etc.
- Johns Hopkins dude: The reason it's good that the world is compositional is because it is understandable. The world is either compositional, or there is a God.
- Differentiable Memory: for question answering, similar to logic programming (Prolog)
- Also: Entity Recurrent Neural Net - each cell represents an (entity in the text) which get updated when an event occurs (or text is fed)
- AI Obstacles: machines need to (1) perceive, (2) update, (3) remember, (4) reason and plan
- Common sense example:
- "The trophy doesn't fit in the suitcase because it's too small."
- "The trophy doesn't fit in the suitcase because it's too big."
- What does 'it' pronoun refer to?
- We aren't born with "object permanance" or understanding of gravity (6-8 months)
- Unsupervised learning
- Cake analogy (in terms of the amount of information per environment): Reinforcement learning (cherry) < Supervised learning (icing) < Unsupervised (cake)
- All the successes in RI are in games but it falls on its face in the real world.
- Intelligence: We want the cherry on top of our cake, but it's not going to solve the problem by itself.
- Personal definition of Unsupervised Learning, contrast functions
- learning a manifold, and distance from that manifold [FWC - this is why RBMs are involved]
- pick a point on the manifold and lower its energy (push down)
- pick a point away from the manifold and increase its energy (push up)
-
You can reformulate a lot of classical learning algorithsm in terms of a contrast function where you want to take low values on the [real] data and high values everywhere else (41:03)
- build the machine so that the volume of low energy stuff is constant
- PCA, K-means (doesn't work well in high dim), GMM, square ICA
- push down of the energy of data points, push up everywhere else
- max likelihood (needs tractable partition function)
- push down of the energy of data points, push up on chosen locations
- contrastive divergence, Ratio Matching, Noise Contrastive Estimation, Minimum Probability Flow
- minimize the gradient and maximize the curvature around data points
- score matching
- train a dynamical system so that the dynamics goes to the manifold
- denoising auto-encoder
- use a regularizer that limits the volume of space that has low energy
- sparse coding (union of planes), sparse auto-encoder, PSD
- if E(Y) = |Y-G(Y)|^2, make G(Y) as "constant" as possible
- contracting [sic?] auto-encoder, saturating auto-encoder
- "but the best idea ever: Adversarial Training"
- "the coolest idea in machine learning in the last 20 years"
- tell the machine that it got an answer wrong, but don't punish it too much for selecting something on the set/manifold of plausible outputs (future states) ... manifold of possible futures
- classical supervised learning that trains to produce a specific point is not sufficient, because in a circular/shell/ribbon manifold the average point won't be on the manifold -- so how do you characterize such a manifold
- answer: train a second NN to figure out what the manifold looks like
- energy based view of adversarial training (Goodfellow et al NIPS 2014): generator picks points to push up
- generator generates points closer and closer to manifold until the discriminator can't tell the difference (sort of a Nash equilibrium)
- eventually generator generates the manifold
- holy grail: give me a way to parameterize a very complex surface in a high dimensional space
- GANs use auto-encoders to generate negative samples
- file:///home/fred/Documents/articles/adversarial_training/unsupervised_repr_learning_with_GANs_1511.06434v2.pdf
- FWC - distance from the manifold (the "energy") is the information that's desired for finance perhaps?
- learning a manifold, and distance from that manifold [FWC - this is why RBMs are involved]
- "Why aren't machines capable of learning the concept of depth? => There must be something missing in our understanding of learning."
- "I could retire if I could train a net with a bunch of physical processes and come up with Newton's Law."
- Combine networks when possible: It's better to train a single network with multiple heads than 2 separate networks, e.g. one to translate to one of each of 2 different languages.
- GANs not clearly useful in language models where the (discrete) distribution over next words can relatively easily be represented.
- They don't work so well in discrete spaces for one reason because it's easy to discriminate between a real input (one-hot vector) and a fake/generated input (softmax), but there are fixes
- w/in 3s of uploading an image to Facebook it gets run through 3 CNNs
- object recognition
- face recognition (turned off in Europe)
- content filtering
- "we really don't care about these values. We will call a and k our nuisance parameters as a result. We will end up including them in our model but only so we can get to the value of h."
- "What did we gain from MCMC? While we kept the hypothesis ranges the same we could expand the ranges if we wanted. We also were able to look at all of the values in each range and not just a discrete list of values. If you tried to tackle this with the naive solution, your code would never finish. Relative to that benchmark, PyMC3 runs extremely quickly."
- "You don't need MCMC in the truest sense of the word. You almost certainly want it though. ... choose an MCMC library and start learning it."
Neural Ficticious Self-Play (NFSP)
- Deep Reinforcement Learning from Self-Play in Imperfect-Information Games
- FWC - One thing that's unique about financial markets is that "memory" isn't necessarily short-term. Regimes can switch and, all of a sudden, memories from the past can come flooding back while recent memory can become instantly irrelevant. Think Poisson jumps layerd on top of a Gaussian distribution.
- "FSP replaces the best response computation and the average strategy updates with reinforcement and supervised learning respectively"
- file:///home/fred/Documents/articles/game_theory/semantics_reprs_and_grammars_for_DL_Balduzzi_1509.08627.pdf
- "Game theory provides tools for analyzing distributed optimization problems where a set of players aim to minimizes losses that depend not only on their actions, but also the actions of all other players in the game [30,31]"
- "Definition 4 proposes that a representation is a function that is a local solution to an optimization problem.... Indeed, recent experience shows that global solutions are often not necessary practice [1-5]. The local solution has similar semantics to--that is, it represents--the ideal solution."
- "a function is a representation if[f] it is selected to optimize an objective"
- "In short, representations are functions with useful semantics, where usefulness is quantifed using a specific objective"
- FWC - you optimize until (local) convergence and the output is a representation (by definition 4 at least)
- FWC - Take for example the number of solutions to 'NN vs. Exponential'--they're all good solutions even though none are global. An important point, perhaps, is that the exact solution manifold isn't the piece of interest; distance from the solution manifold is what's important and all solutions provide approximately that.
- Guarantees fall under the following broad categories:
- Exact gradients. Under error backpropagation the Response graph implements the chain rule, which guarantees that Players receive the gradients of their loss functions; see section 2.1.
- Surrogate objectives. The variational autoencoder uses a surrogate objective: the variational lower bound. Maximizing the surrogate is guaranteed to also maximize the true objective, which is computational intractable.
- Learned objectives. In the case of generative adversarial network and the DAC-model, some of the players learn a loss that is guaranteed to align with the true objective, which is unknown.
- Estimated gradient. In the DAC-model and kickback, gradient estimates are substituted for the true gradient.
- Deviator, Actor, Critic (DAC, kws: reinforcement learning)
- actor-critic algorithms decompose the reinforcement learning problem intotwo components: the critic, which learns an approximate value function that predicts the total discounted future reward associated with state-action pairs, and the actor, which searches for a policy that maximizes the value appoximation provided by the critic
- Two appealing features of the algorithm are that (i) Actor is insulated from Critic, and only interacts with Deviator and (ii) Critic and Deviator learn different features adapted to representing the value function and its gradient respectively
- Kickback computes an estimate of the backpropagated gradient using the signals generated during the feedforward sweep
- Unfortunately, at a conceptual level kickback, target propagation and feedback alignment all tackle thewrong problem. The cortex performs reinforcement learning: mammals are not provided with labels, and there is no clearly defined output layer from which signals could backpropagate. A biologically-plausible deep learning algorithm should take advantage of the particularities of the reinforcement learning setting.
- Adversarial networks consists of competing neural networks, a generator and discriminator, the former tries to generate fake images while the later tries to identify real images. The interesting feature of these systems is that a closed form loss function is not required. In fact, some systems have the surprising capability of discovering its own loss function! A disadvantage of adversarial networks are they are difficult to train. Adversarial learning consists in finding a Nash equilibrium to a two-player non-cooperative game. Yann Lecun, in a recent lecture on unsupervised learning, calls adversarial networks the "the coolest idea in machine learning in the last twenty years."
- What we see in these 3 players are 3 different ways game theory plays in Deep Learning. (1) As a means of describing and analyzing new DL architectures. (2) As a way to construct a learning strategy and (3) A way to predict behavior of human participants. The last application can make your skin crawl!
- eXtreme Gradient Boosting
- bias related errors handled by
- adaptive boosting (adaboost)
- gradient boosting
- variance related errors are handled by
- bagging
- random forest
- bottom line best: xgboost^0.65 * lasagne_nearest_neighbor^0.35 * 0.85 + adaboost_et * 0.15
-
More on XGBoost (3/3/17)
- In pseudocode:
- Fit a model to the data,
F_1(x) = y - Fit a model to the residuals,
h_1(x) = y - F_1(x) - Create a new model,
F_2(x) = F_1(x) + h(x)
- Take a second to stand in awe of what we just did. We modified our gradient boosting algorithm so that it works with any differentiable loss function.
- The Code
- https://github.com/dmlc/xgboost
- https://github.com/Microsoft/LightGBM (similar, and gaining recent attention, from MSFT)
- Deep learning methods require a lot more training data than XGBoost ... we have large pre-existing research communities working on computer vision, speech recognition, and NLP. On the other hand, if you have a specialized/exotic problem, then it takes a lot more effort to come up with good deep architectures [which is why XGBoost is good]. On Kaggle competition kind of short timelines, there just isn't enough time to invest in exploring new deep architectures suited to an exotic problem
- When you do have "enough" training data, and when somehow you manage to find the matching magical deep architecture, deep learning blows away any other method by a large margin. Thus for image or speech recognition or even some reinforcement learning problems, deep learning methods have resulted in such a huge boost in performance that decades of domain-specific research hasn't been able to rival it.
- "Automated decision-making is appealing to businesses as it can save time and eliminate human emotional volatility. People have a bad day and it then colors their perception of the world and they make different decisions."
- "the same learning rate applies to all parameter updates. If our data is sparse and our features have very different frequencies, we might not want to update all of them to the same extent, but perform a larger update for rarely occurring features"
- "Another key challenge of minimizing highly non-convex error functions common for neural networks is avoiding getting trapped in their numerous suboptimal local minima. Dauphin et al. 19 argue that the difficulty arises in fact not from local minima but from saddle points"
- FWC - It seems that this depends on the "coarseness" of the optimal surface. The relative size of the jumps provided by the stochastic walk compared to the size of the local minima "pools." I wonder if there's a way to estimate the number of local minima in a surface; e.g. how many convex surfaces need to be combined to construct the bumpy surface.
- "We will not discuss algorithms that are infeasible to compute in practice for high-dimensional data sets, e.g. second-order methods such as Newton's method."
- Nesterov accelerated gradient
- "We know that we will use our momentum term γv_{t−1} to move the parameters θ. Computing θ−γv_{t−1} thus gives us an approximation of the next position of the parameters (the gradient is missing for the full update), a rough idea where our parameters are going to be. We can now effectively look ahead by calculating the gradient not w.r.t. to our current parameters θ but w.r.t. the approximate future position of our parameters"
- "significantly increased the performance of RNNs on a number of tasks [8]"
- Adagrad
- "well-suited for dealing with sparse data" (e.g. word-vectors which have frequent and infrequent words)
- "eliminates the need to manually tune the learning rate"
- Adadelta - "seeks to reduce [Adagrad's] aggressive, monotonically decreasing learning rate"
- "RMSprop in fact is identical to the first update vector of Adadelta"
- "Adam also keeps an exponentially decaying average of past gradients mt, similar to momentum"
- "In summary, RMSprop is an extension of Adagrad that deals with its radically diminishing learning rates. It is identical to Adadelta, except that Adadelta uses the RMS of parameter updates in the numinator update rule. Adam, finally, adds bias-correction and momentum to RMSprop. Insofar, RMSprop, Adadelta, and Adam are very similar algorithms that do well in similar circumstances. Kingma et al. [15] show that its bias-correction helps Adam slightly outperform RMSprop towards the end of optimization as gradients become sparser. Insofar, Adam might be the best overall choice."
- "The following are algorithms and architectures that have been proposed to optimize parallelized and distributed SGD."
- A distributed version of TensorFlow has been released.
- "Generally, we want to avoid providing the training examples in a meaningful order to our model as this may bias the optimization algorithm. Consequently, it is often a good idea to shuffle the training data after every epoch."
- "According to Geoff Hinton: "Early stopping (is) beautiful free lunch" (NIPS 2015 Tutorial slides, slide 63). You should thus always monitor error on a validation set during training and stop (with some patience) if your validation error does not improve enough."
- Gradient Noise - "added noise gives the model more chances to escape and find new local minima, which are more frequent for deeper models"
This AI Boom Will Also Bust (Robin Hanson, 12/20/16)
- "Most firms that think they want advanced AI/ML really just need linear regression on cleaned-up data."
- "A hedge fund tried to hire me on the spot when I suggested a regression instead of using IBM Watson on their dataset."
- "Statistically speaking, you and your company really don't need machine learning."
- John picked up the ball and handed it to Mary. Mary walked into the room. Where is the ball?
- Traditional NNs combine memory and processing in the same structure. [FWC - they combine mutation and computation!!!] A new paper out a few months ago tries to separate the two.
- DMNs ("episodic memory") iterate over input multiple times and use state from previous iter as next iter's starting point. Just like a human may have to re-read something a few times to understand it.
- http://stats.stackexchange.com/questions/90874/how-can-stochastic-gradient-descent-avoid-the-problem-of-a-local-minimum
- Especially see section 4.2 of this nimes-1991.pdf which is linked to from the above.
-
Learning Polynomials with Neural Nets
- "we can not use this theorem to conclude that gradient descent plus random perturbation will always converge to the global optima from any initial neural network initialization; nevertheless, this provides a rigorous, and conceptually compelling explanation for why the existence of local optima do not deter the usage of neural networks in practice."
- "While a more common
phi_activation_fnis the sigmoid function, the particular form ofphi_activation_fnis not that important as long as it has 'good' coverage of all the degrees in its Taylor series"
AdaBoost (12/14/16)
- mentioned in the Conformal Prediction article below
- "information gathered at each stage of the AdaBoost algorithm about the relative 'hardness' of each training sample is fed into the tree growing algorithm such that later trees tend to focus on harder-to-classify examples"
- "The individual learners can be weak, but as long as the performance of each one is slightly better than random guessing (e.g., their error rate is smaller than 0.5 for binary classification), the final model can be proven to converge to a strong learner."
Conformal Prediction (12/14/16)
- machine learning with confidence intervals
- 2 flavors:
- "transductive conformal prediction"; leave one out; not computationally efficient
- "inductive conformal prediction"; split the dataset in 2, train on first have and estimate confidence interval given the residuals from the second half
- FWC idea: predict stdev-neutralized forecasts so that what is being predicted is homoskedastic (i.e. predict stdev first, then neurtralize outcomes wrt it)
- the applications and extensions of the idea are what really tantalizes me about the subject. New forms of feature selection, new forms of loss function which integrate the confidence region, new forms of optimization to deal with conformal loss functions, completely new and different machine learning algorithms, new ways of thinking about data and probabilistic prediction in general
- "Here is a presentation with some open problems and research directions if you want to get to work on something interesting."
- "In theory, architectures like LSTMs should be able to deal with this, but in practice long-range dependencies are still problematic."
- "A big advantage of attention is that it gives us the ability to interpret and visualize what the model is doing"
- "An alternative approach to attention is to use Reinforcement Learning to predict an approximate location to focus to. That sounds a lot more like human attention, and that’s what’s done in Recurrent Models of Visual Attention."
- "In Show, Attend and Tell the authors apply attention mechanisms to the problem of generating image descriptions. They use a Convolutional Neural Network to “encode” the image, and a Recurrent Neural Network with attention mechanisms to generate a description" [FWC - this is my stock encoding -> forecast idea]
- Neural Turing Machines - "The challenge is that we want to make them differentiable. In particular, we want to make them differentiable with respect to the location we read from or write to, so that we can learn where to read and write." "There are a number of open source implementations of these models..."
- Attention Interfaces - "We’d like attention to be differentiable, so that we can learn where to focus. To do this, we use the same trick Neural Turing Machines use: we focus everywhere, just to different extents." [FWC - Just like unsupervised learning has been applied to images (e.g. recognition of a concept called "cat") has it been applied to text? E.g. recognition of parts of speech, verbs, nouns, etc. If this could be performed on a known language perhaps it could be performed on the voynich manuscript]
- Addaptive Computation Time - one should think more when things are hard, different amounts of computation each step, In order for the network to learn how many steps to do, we want the number of steps to be differentiable, ACT is a very new idea, but we believe that it, along with similar ideas, will be very important.
- Neural Programmer - learns to generate such programs without needing examples of correct programs, Instead of running a single operation at each step, we do the usual attention trick of running all of them and then average the outputs together, weighted by the probability we ran that operation.
- The neural programmer needs to answer questions like “How many cities have a population greater than 1,000,000?” given a table of cities with a population column. To facilitate this, some operations allow the network to reference constants in the question they’re answering, or the names of columns. This referencing happens by attention, in the style of pointer networks (Vinyals, et al., 2015). [FWC - this is like my idea to have a computer program automatically confirm the results of a research paper]
- We think that this general space, of bridging the gap between more traditional programming and neural networks is extremely important.
- Conclusion
- A human with a piece of paper is, in some sense, much smarter than a human without. A human with mathematical notation can solve problems they otherwise couldn’t. Access to computers makes us capable of incredible feats that would otherwise be far beyond us.
- In general, it seems like a lot of interesting forms of intelligence are an interaction between the creative heuristic intuition of humans and some more crisp and careful media, like language or equations. Sometimes, the medium is something that physically exists, and stores information for us, prevents us from making mistakes, or does computational heavy lifting. In other cases, the medium is a model in our head that we manipulate. Either way, it seems deeply fundamental to intelligence.
- chapter 1 of this "book" was my first real exposure to NNs, just as I was leaving HBK
- "But I think it was much more difficult than it might seem. You see, at the time backpropagation was invented, people weren’t very focused on the feedforward neural networks that we study. It also wasn’t obvious that derivatives were the right way to train them. Those are only obvious once you realize you can quickly calculate derivatives. There was a circular dependency."
- "Worse, it would be very easy to write off any piece of the circular dependency as impossible on casual thought. Training neural networks with derivatives? Surely you’d just get stuck in local minima. And obviously it would be expensive to compute all those derivatives. It’s only because we know this approach works that we don’t immediately start listing reasons it’s likely not to."
Understanding Convolutions (12/6/16)
- "Max-pooling layers kind of 'zoom out'. They allow later convolutional layers to work on larger sections of the data, because a small patch after the pooling layer corresponds to a much larger patch before it. They also make us invariant to some very small transformations of the data."
- "For us, convolution will provide a number of benefits. Firstly, it will allow us to create much more efficient implementations of convolutional layers than the naive perspective might suggest."
- "In fact, the use of highly-efficient parallel convolution implementations on GPUs has been essential to recent progress in computer vision."
Neural Networks, Manifolds, and Topology (12/5/16) (and this similar demo from Karpathy: ConvnetJS)
- "As mentioned previously, classification with a sigmoid unit or a softmax layer is equivalent to trying to find a hyperplane (or in this case a line) that separates A and B in the final represenation. With only two hidden units, a network is topologically incapable of separating the data in this way, and doomed to failure on this dataset."
- "The manifold hypothesis is that natural data forms lower-dimensional manifolds in its embedding space. There are both theoretical3 and experimental4 reasons to believe this to be true. If you believe this, then the task of a classification algorithm is fundamentally to separate a bunch of tangled manifolds."
- "The natural thing for a neural net to do, the very easy route, is to try and pull the manifolds apart naively and stretch the parts that are tangled as thin as possible. While this won’t be anywhere close to a genuine solution, it can achieve relatively high classification accuracy and be a tempting local minimum. It would present itself as very high derivatives on the regions it is trying to stretch, and sharp near-discontinuities. We know (Szegedy, et al, slight modifications cause best image classification nets to misclassify) these things happen. Contractive penalties (Rifai, et al, 2011, Contractive Autoencoders), penalizing the derivatives of the layers at data points, are the natural way to fight this."
- "The more I think about standard neural network layers – that is, with an affine transformation followed by a point-wise activation function – the more disenchanted I feel. It’s hard to imagine that these are really very good for manipulating manifolds."
- "K-Nearest Neighbor Layers: I’ve also begun to think that linear separability may be a huge, and possibly unreasonable, amount to demand of a neural network. In some ways, it feels like the natural thing to do would be to use k-nearest neighbors (k-NN). However, k-NN’s success is greatly dependent on the representation it classifies data from, so one needs a good representation before k-NN can work well." [FWC - whatever the representation, it needs to be logarithmic and based on matrix multiplication, perhaps something like a random forest mixed with logistic units]
- "As a first experiment, I trained some MNIST networks (two-layer convolutional nets, no dropout) that achieved ∼1% test error. I then dropped the final softmax layer and used the k-NN algorithm. I was able to consistently achieve a reduction in test error of 0.1-0.2%. Still, this doesn’t quite feel like the right thing. The network is still trying to do linear classification, but since we use k-NN at test time, it’s able to recover a bit from mistakes it made." [FWC - this is another way to generate an encoding, as opposed to negative sampling]
Deep learning, model checking, AI, the no-homunculus principle, and the unitary nature of consciousness
- "Lots has been written on 'machine learning' but in practice this often captures just part of the process. Here I want to discuss the possibilities for automating the entire process."
- "posterior distribution—the conditional probability distribution of the unobserved quantities of ultimate interest, given the observed data."
- "The third step--identifying model misfit and, in response, figuring out how to improve the model--seems like the toughest part to automate. We often learn of model problems through open-ended exploratory data analysis, where we look at data to find unexpected patterns and compare inferences to our vast stores of statistical experience and subject-matter knowledge. Indeed, one of my main pieces of advice to statisticians is to integrate that knowledge into statistical analysis, both in the form of formal prior distributions and in a willingness to carefully interrogate the implications of fitted models. How would an AI do [this step]? One approach is to simulate the human in the loop by explicitly building a model-checking module that takes the fitted model, uses it to make all sorts of predictions, and then checks this against some database of subject-matter information. I’m not quite sure how this would be done, but the idea is to try to program up the Aha process of scientific revolutions."
- "All that is left, then, is the idea of a separate module that identifies problems with model fit based on comparisons of model inferences to data and prior information. I think that still needs to be built."
- RL == "the science of decision making"
- http://www.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
- http://groups.google.com/group/csml-advancted-topics
- The seminal book on RL: http://webdocs.cs.ualberta.ca/~sutton/book/the-book.html
- What makes RL different from other ML paradigms?
- There is no supervisor, only a reward signal. There is nobody saying "that was the best thing to do in this scenario" -- [FWC - no labels, only relative rewards]
- Feedback is delayed [maybe many steps later, e.g. positive rewards for many steps followed by a catastrophic negative]
- Time really matters (sequential, non-i.i.d. data) e.g. robot moving through a world, in RL the agent gets to take actions, the agent influences the data [path dependencies] "optimize a sequence of decisions"
Understanding LSTM Networks (11/17/16)
- "LSTMs were a big step in what we can accomplish with RNNs. It’s natural to wonder: is there another big step? A common opinion among researchers is: “Yes! There is a next step and it’s attention!” The idea is to let every step of an RNN pick information to look at from some larger collection of information. For example, if you are using an RNN to create a caption describing an image, it might pick a part of the image to look at for every word it outputs."
- All of the other posts on this guy's (colah!) blog seem to be really clear also.
- Yes, this particular post is referenced from everywhere including IBM and TensorFlow documenation.
- [–]kkastner 3 points 3 months ago - KNN, K=1 is a great benchmark and also a good way to detect if you have accidentally had overlap between train and test sets. Downside is that KNN scales horribly in number of samples without a lot of custom work to do the search part, and also doesn't work well in high dimensional spaces. If you engineer a small feature space and have limited data it can be very useful, though.
- [–]orangeduck 2 points 3 months ago - NN/KNN is a great sanity check just make sure your data is all set up right and all your code is working before you jump in and replace it with something more complex. It requires no real training phase and you know it will literally only return data from the training set - it wont do any weird extrapolation or create any crazy outputs if it is configured wrong.
- But NN/KNN is also a prop - because if your dataset grows and you start having to do things like built kd-trees or other spatial acceleration structures you are in for a real headache. You can think of it like this: NN/KNN has a very low initial complexity but the complexity grows at a horrible rate with respect to the size/difficulty of the problem, and actually Guassian Processes and other kernel based methods, which are not so different in many respects, tend to have exactly the same problems.
- This is partially why Neural Networks and Deep Learning have seen such success recently - it seems their complexity growth is quite shallow with respect to larger problems - you don't need to use any special data structures or complex algorithms - just continue to tweak parameters, add more layers, and train using more powerful GPUs
The original NTM paper, key takeaways
- There are limits to how well LSTMs generalize beyond their training size. We've kinda seen this empirically, but Graves and company show this on a number of tasks. NTMs seem to do better in this respect.
- NTMs will converge much faster for some class of problems and the external memory allows them to use fewer parameters than an LSTM (which as we've seen, grows quadratically).
- I'm not sure why I had this expectation, but I'd thought NTMs were similar to DNMs. That is absolutely NOT true! They are in fact the evolutionary precursor to DNCs. There are some differences in how memory is addressed and tracked that makes DNCs supposedly work a little better. But these are very similar architectures.
- There seem to be a fairly finite number of constructs used to assemble NNs.
-
https://www.quora.com/What-is-negative-sampling
- The end result is that if cat appears in the context of food, then the vector of food is more similar to the vector of cat (as measures by their dot product) than the vectors of several other randomly chosen words (e.g. democracy, greed, Freddy), instead of all other words in language. This makes word2vec much much faster to train.
- "In both cases, you want to contrast "correct" instances with things that look ever so slightly different."
- i.e. my idea from 10 years ago wrt fitting models to bogus data
- a place like AQR should, every once in a while, give its researchers bogus data (without them knowing) to see if they come up with something to calibrate how much they are overfitting
- i suppose this is sorta like permutation resampling as used wrt multiple comparisons
Running things on a GPU (10/1/16)
- TensorFlow and Keras are (current) reigning champs
Is Artificial Intelligence Permanently Inscrutable? Despite new biology-like tools, some insist interpretation is impossible.
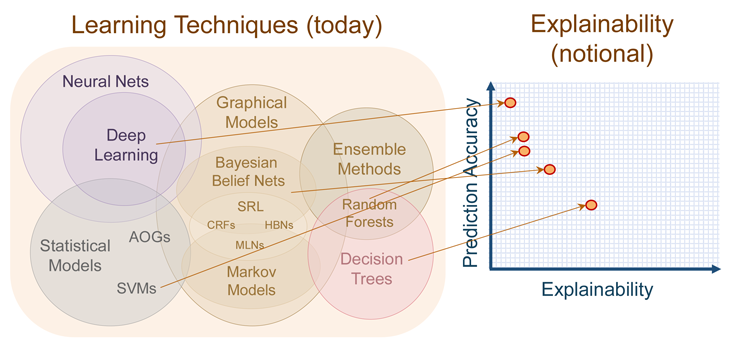
- "deep networks as the least understandable of modern methods. At the other end of the spectrum are decision trees, rule-based systems that tend to prize explanation over efficacy." (see image here)
- "Yosinski’s toolkit can, in part, counter these concerns by working backward, discovering what the network itself “wants” to be correct—a kind of artificial ideal. The program starts with raw static, then adjusts it, pixel by pixel, tinkering with the image using the reverse of the process that trained the network. Eventually it finds a picture that elicits the maximum possible response of a given neuron."
{kind=link}
- "Dropout is meant to reduce overfitting by randomly omitting half of the feature detectors on each training case."
"Understanding Machine Learning: From Theory to Algorithms" by Shai Shalev-Shwartz and Shai Ben-David. It's available for free at its website: http://www.cs.huji.ac.il/~shais/UnderstandingMachineLearning/understanding-machine-learning-theory-algorithms.pdf (6/28/16)
ML "learns" by making mistakes, so one possible way to train it might be to make it compete against other ML. Every time it loses, it should be able to "learn" something. (5/3/16)
- Abstract: Used to estimate the risk of an estimator or to perform model selection, cross-validation is a widespread strategy because of its simplicity and its (apparent) universality. Many results exist on model selection performances of cross-validation procedures. This survey intends to relate these results to the most recent advances of model selection theory, with a particular emphasis on distinguishing empirical statements from rigorous theoretical results. As a conclusion, guidelines are provided for choosing the best cross-validation procedure according to the particular features of the problem in hand.
- keywords: overfitting
Neural Network Basics (4/19/16)
Machine "Un"-learning (3/18/16)
- Aggregate data at varying levels of granularity. Then machine learn from a chosen level to speed things up.
- Deep-Q learning Pong with Tensorflow and PyGame (3/16/16)
-
Deep Learning Comparison Sheet: Deeplearning4j vs. Torch vs. Theano vs. Caffe vs. TensorFlow (3/16/16)
- "Thirdly, Java’s lack of robust scientific computing libraries can be solved by writing them, which we’ve done with ND4J."
- "By choosing Java, we excluded the fewest major programming communities possible."
- "We have paid special attention to Scala in building Deeplearning4j and ND4J, because we believe Scala has the potential to become the dominant language in data science."
- How to combine CNN with CRF in python? (3/16/16)
- TensorFlow Machine Learning with Financial Data on Google Cloud Platform (3/10/16)
- TensorFlow in Python (3/10/16 and 12/15/16; FWC - great pointer)
- Python Anywhere: Quickstart: TensorFlow-Examples on PythonAnywhere
- Do you think TensorFlow will eventually replace Theano and Torch? (3/18/16)
- TensorFlow for "shallow learning" -- Implementations of Multilayer-Perceptron and Softmax Regression in a scikit-learn-like interface (3/22/16)
- R vs. Python
- TensorFlow, Theano, Keras, Neon, PDB, TDB, TensorBoard, NVIS
Benefit of KNN: You can model the whole distribution, all the moments of it. This is difficult to model with other techniques. Ask Desmond, he might know others.
Neural GPUs Learn Algorithms (12/10/15)
Self Organizing Maps (SOMs) Tutorial (12/7/15)
- Linked to from SOMs with Google's TensorFlow
- Prototyping - R, Python
- IBM - Weka, SPSS (Desmond isn't quite sure why IBM uses these though)
- Lua/Torch - like Python, 2 GB csv limit that might be fixed by now though
- Big Data - Spark/mllib and Hadoop/Mahout, big bug less configurable, e.g. fewer metrics and less options for targeted batch GD (but this isn't really that important in practi
- This software was mentioned by Desmond.
- He sounded reluctant when he had to stop using it in favor of SPSS.
Visualizing popular ML algorithms (10/25/15)
- e.g. Image recognition, NLP
- This is because lots of people understand the goals of those problems.
- I'm in a unique position to understand the goals of financial forecasting.
- Thus suggests to get good at doing a problem the hard way first to learn how it's done, and then switch to ML
- It's almost like there's another dimension to the supervised/unsupervised dimension of ML: understanding the output/y's/range/meaning vs. not understanding--maybe this is "domain knowledge"
Email: "projections onto nonlinear subspaces (k-RBMs)" (the email contains hard copies of these papers)
- "Non-Linear Manifolds" - https://www.google.com/search?q=projection+onto+curved+subspaces&ie=utf-8&oe=utf-8#q=projection+onto+nonlinear+subspaces
- RBMs - http://deeplearning.net/tutorial/rbm.html
- Why conquer a task if there’s no insight to be had from the victory? “Okay,” he says, “Deep Blue plays very good chess—so what? Does that tell you something about how we play chess? No. Does it tell you about how Kasparov envisions, understands a chessboard?” A brand of AI that didn’t try to answer such questions—however impressive it might have been—was, in Hofstadter’s mind, a diversion.
- “Nobody is a very reliable guide concerning activities in their mind that are, by definition, subconscious,” he once wrote. “This is what makes vast collections of errors so important. In an isolated error, the mechanisms involved yield only slight traces of themselves; however, in a large collection, vast numbers of such slight traces exist, collectively adding up to strong evidence for (and against) particular mechanisms.” Correct speech isn’t very interesting; it’s like a well-executed magic trick—effective because it obscures how it works.
- FWC - "vast collections of errors so important" - similar to studying differentials rather than levels, as in differential gene expressions--i.e. make your own errors!
- Carpenter is putting his nearly one million dollars in National Science Foundation grants into work around the open source “Stan” package, which presents a scalable approach to Bayesian modeling that can incorporate larger, more complex problems than tend to fit inside other frameworks.
- working with drug maker Novartis on a drug-disease interaction clinical trial for an ophthalmology drug that spans close to 2,000 patients.
- http://www.iro.umontreal.ca/~bengioy/dlbook/ (no pdf available, only online for now)
- Bibliography: http://www.iro.umontreal.ca/~bengioy/dlbook/front_matter.pdf (also in Downloads directory)
Deep Learning Resources (http://deeplearning.net/software_links/)
- "Torch – provides a Matlab-like environment for state-of-the-art machine learning algorithms in lua"
- MIT OpenCourseWare
- Deep Learning at Oxford, 2015
- "Although quite long (~45 min), it's a good snapshot of where AI / deep learning is today and where it came from and why it's winning."
- [Yann Lecun, Facebook // Artificial Intelligence // Data Driven #32 (Hosted by FirstMark Capital)] (https://www.youtube.com/watch?v=AbjVdBKfkO0)
- My notes here
- Why You Should be a Little Scared of Machine Learning http://www.reddit.com/r/programming/comments/3l0qek/why_you_should_be_a_little_scared_of_machine/
- This link on Recurrent Neural Networks was linked to from the above: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- "RNNs combine the input vector with their state vector with a fixed (but learned) function to produce a new state vector"
- "If training vanilla neural nets is optimization over functions, training recurrent nets is optimization over programs."
- "crucially this output vector's contents are influenced not only by the input you just fed in, but also on the entire history of inputs you've fed in in the past." I.e. this links back to learning in stages (pixels, lines, shapes, faces; or regimes, sectors, instruments).
- SEQUENCES - "model the probability distribution of the next character in the sequence given a sequence of previous characters"
- this article contains lots of other links: RMSProp, minimal character-level RNN language model in Python/numpy, code, Long-Short-Term Memory networks
Email: "What is the difference between convolutional neural networks, restricted Boltzmann machines, and auto-encoders? - Cross Validated"
- http://stats.stackexchange.com/questions/114385/what-is-the-difference-between-convolutional-neural-networks-restricted-boltzma
- "So, if we already had PCA, why the hell did we come up with autoencoders and RBMs? It turns out that PCA only allows linear transformation of a data vectors."
- http://stats.stackexchange.com/questions/40598/restricted-boltzmann-machines-vs-multilayer-neural-networks
- "Once deep (or maybe not that deep) network is pretrained, input vectors are transformed to a better representation and resulting vectors are finally passed to real classifier (such as SVM or logistic regression). In an image above it means that at the very bottom there's one more component that actually does classification."
- file:///home/fred/Documents/coursera/machine_learning/complete_notes_holehouse/Machine_learning_complete/09_Neural_Networks_Learning.html (from here: http://www.holehouse.org/mlclass/)
- http://cs229.stanford.edu/materials.html
- Email: "octave/matlab resources" ** https://www.coursera.org/learn/machine-learning/supplement/Mlf3e/more-octave-matlab-resources
- http://www.forbes.com/sites/anthonykosner/2013/12/29/why-is-machine-learning-cs-229-the-most-popular-course-at-stanford/
- http://www.holehouse.org/mlclass/17_Large_Scale_Machine_Learning.html
- People still use relational databases - great if you have predictable queries over structured data
- But the data people want to work with is becoming more complex and bigger
- Free text, unstructured data doesn't fit will into tables
- Do sentiment analysis in SQL isn't really that good
- So to do new kinds of processing need a new type of architecture
- Hadoop lets you do data processing - not transactional processing - on the big scale
- Increasingly things like NoSQL is being used
- Welcome to the AI Conspiracy: The ‘Canadian Mafia’ Behind Tech’s Latest Craze http://recode.net/2015/07/15/ai-conspiracy-the-scientists-behind-deep-learning/
- "Deep-Learning AI Is Taking Over Tech. What Is It?"
- "The results of these collections are then tiled so that they overlap to obtain a better representation of the original image; this is repeated for every such layer. Because of this, they are able to tolerate translation of the input image" https://en.wikipedia.org/wiki/Convolutional_neural_network
- ...anything we don't. Anything we can observe effect and input, but not transmission mechanism.
- E.g. the inner workings of the brain. Which would be very meta, b/c it would be like a machine learning a machine that learns a machine.
- E.g. machine learning to learn the structure of a neural net. A neural net learning a neural net. What if it could learn what the outputs and inputs are rather than being programmed to know them.
- The Model Complexity Myth https://jakevdp.github.io/blog/2015/07/06/model-complexity-myth/
- Gaussian Processes for Machine Learning (free technical book) http://www.gaussianprocess.org/gpml/
- Fill in the Blanks: Using Math to Turn Lo-Res Datasets Into Hi-Res Samples http://www.wired.com/2010/02/ff_algorithm/
- Codementor: Building Data Products with Python: Using Machine Learning to Provide Recommendations https://www.codementor.io/python/tutorial/build-data-products-django-machine-learning-clustering-user-preferences
- "using K-means clustering as a machine learning model that makes use of user similarity in order to provide better wine recommendations"
-
- Chess-playing computer with an entirely new method of learning, and more here. It is International Master strength (for now).
- http://www.technologyreview.com/view/541276/deep-learning-machine-teaches-itself-chess-in-72-hours-plays-at-international-master/