Java Wiki - emizoripx/java-wiki GitHub Wiki
- Interfaz Map y sus implementaciones
- Java Records
- Interfaz Queue
- Interfaz Deque
- Interfaz PriorityQueue
- Virtual Threads
- Sequenced Collections
- String templates, unnamed patterns and variables, record patterns y pattern matching for switch
Es una interfaz que representa una estructura de datos clave valor. En otras palabras asocia un valor con una clave que permite recuperar ese valor utilizando la clave asociada.
Al ser una interfaz no podemos crear objetos.
Las implementaciones de la interfaz Map son: HashMap, EnumMap, TreeMap, LinkedHashMap entre otras.
Ejemplo:
import java.util.*;
public class Main {
public static void main(String[] args) {
// Crear un Map utilizando HashMap
Map<String, Integer> mapa = new HashMap<>();
// Agregar elementos al mapa
mapa.put("Juan", 25);
mapa.put("María", 30);
mapa.put("Pedro", 28);
// Obtener el valor asociado a una clave
int edadMaria = mapa.get("María");
System.out.println("La edad de María es: " + edadMaria);
// Iterar sobre las claves del mapa
for (String nombre : mapa.keySet()) {
System.out.println("Nombre: " + nombre + ", Edad: " + mapa.get(nombre));
}
}
}
El ejemplo crea un Map usando la implementacion HashMap que asocia nombres de personas con sus edades, la manera de agregar valores a tu map es usando el metodo put(), para recuperar el valor se usa el metodo get(), finalente para imprimir todos los valores del map usamos el metod keySet
La interfaz Map incluye todos los métodos del Collection interfaz. Es porque Collection es una súper interfaz de Map .
Además de los métodos disponibles en el Collection interfaz, el Map La interfaz también incluye los siguientes métodos:
- put(K, V) - Inserta la asociación de una clave K y un valor V en el mapa. Si la clave ya está presente, el nuevo valor reemplaza el valor anterior.
- putAll() - Inserta todas las entradas del mapa especificado en este mapa.
- putIfAbsent(K, V) - Inserta la asociación si la clave K aún no está asociado con el valor V .
- get(K) - Devuelve el valor asociado a la clave especificada K . Si no se encuentra la clave, devuelve null .
- getOrDefault(K, valor predeterminado) - Devuelve el valor asociado a la clave especificada K . Si no se encuentra la clave, devuelve el defaultValue .
- containsKey(K) - Comprueba si la clave especificada K está presente en el mapa o no.
- containsValue(V) - Comprueba si el valor especificado V está presente en el mapa o no.
- replace(K, V) - Reemplazar el valor de la clave K con el nuevo valor especificado V .
- replace(K, valor anterior, valor nuevo) - Reemplaza el valor de la clave K con el nuevo valor nuevoValor solo si la clave K está asociado con el valor oldValue .
- remove(K) - Elimina la entrada del mapa representada por la clave K .
- remove(K, V) - Elimina la entrada del mapa que tiene clave K asociado con el valor V .
- keySet() - Devuelve un conjunto de todas las claves presentes en un mapa.
- values() - Devuelve un conjunto de todos los valores presentes en un mapa.
- entrySet() - Devuelve un conjunto de todas las asignaciones clave/valor presentes en un mapa.
Es la implementación más utilizada de la interfaz Map. Almacena los pares clave-valor en una tabla hash, lo que proporciona un acceso rápido a los elementos. No garantiza el orden de los elementos.
- Alta velocidad de búsqueda y recuperación: HashMap proporciona un acceso rápido a los elementos a través de la tabla hash, lo que lo hace ideal para operaciones de búsqueda y recuperación.
- Eficiencia en el uso de memoria: HashMap tiene un consumo de memoria eficiente y es adecuado para grandes conjuntos de datos.
- No ordenado: Los elementos en un HashMap no tienen un orden predecible. Si necesitas iterar sobre los elementos en un orden específico, como el orden de inserción o un orden basado en la clave, un HashMap no será adecuado.
- Sincronización: HashMap no es sincronizado, lo que significa que no es seguro para subprocesos. Si necesitas un Map que pueda ser accedido concurrentemente por múltiples hilos, tendrás que sincronizar manualmente el acceso a través de bloqueos o utilizar una implementación sincronizada como Collections.synchronizedMap().
Cuando usar?
- Se utiliza comúnmente cuando no se requiere un orden específico de los elementos.
- Proporciona un acceso rápido a los elementos a través de la tabla hash.
- Es adecuado para la mayoría de las situaciones generales donde la clave no necesita un orden particular.
Es una implementación especializada de la interfaz Map en Java que está diseñada para su uso con tipos de enumeración (enum). Esta implementación está altamente optimizada para el rendimiento y el uso eficiente de la memoria cuando se utiliza con enumeraciones como claves.
- Eficiencia y rendimiento optimizados: EnumMap está altamente optimizado para trabajar con tipos de enumeración como claves, lo que significa que proporciona un rendimiento rápido y eficiente en comparación con otras implementaciones de Map cuando se utilizan enumeraciones.
- Uso eficiente de la memoria: Debido a su implementación interna especializada, EnumMap puede ser más eficiente en el uso de la memoria en comparación con otras implementaciones de Map, especialmente cuando se trabaja con un gran número de claves de enumeración.
- Ordenamiento natural de claves: EnumMap mantiene un orden natural de las claves basado en el orden en que las constantes de la enumeración están declaradas en el código fuente. Esto puede ser útil si necesitas iterar sobre las claves en un orden específico.
- Tipo seguro: Al utilizar enumeraciones como claves, EnumMap proporciona un alto nivel de seguridad de tipos. Esto significa que puedes evitar errores de programación relacionados con tipos al utilizar EnumMap.
- Limitado a enumeraciones como claves: La principal desventaja de EnumMap es que está diseñado específicamente para trabajar con tipos de enumeración como claves. Esto significa que no puedes utilizar EnumMap con otros tipos de claves, como cadenas o números.
- No permite claves nulas: EnumMap no permite claves nulas, ya que está diseñado para trabajar con enumeraciones, donde cada constante de la enumeración es una clave válida. Si necesitas permitir claves nulas, EnumMap no sería la elección adecuada.
- Requiere que las claves sean constantes de enumeración: Para utilizar EnumMap, debes tener una enumeración definida con un conjunto fijo de constantes. Si no tienes una enumeración adecuada, EnumMap no sería útil en tu caso.
Cuando usar?
- Asociación de datos con constantes de enumeración: Si tienes una enumeración que representa un conjunto fijo de constantes relacionadas y necesitas asociar algún tipo de datos con cada una de esas constantes, EnumMap es una elección natural. Por ejemplo, días de la semana, meses del año, tipos de moneda, etc.
- Eficiencia y rendimiento: Cuando estás trabajando con enumeraciones como claves, EnumMap puede proporcionar un rendimiento superior y un uso más eficiente de la memoria en comparación con otras implementaciones de Map. Si la eficiencia es una preocupación y estás trabajando exclusivamente con enumeraciones, EnumMap es una opción sólida.
- Seguridad de tipos: EnumMap ofrece un alto nivel de seguridad de tipos, ya que garantiza que solo se puedan utilizar constantes válidas de la enumeración como claves. Esto puede ayudar a evitar errores de programación relacionados con tipos al asociar datos con enumeraciones.
- Ordenamiento natural de claves: Si necesitas mantener un orden natural de las claves basado en el orden de declaración en la enumeración, EnumMap es una buena elección. Puedes confiar en que las iteraciones sobre un EnumMap proporcionarán los elementos en el orden en que fueron declarados en la enumeración.
Implementa la interfaz NavigableMap y utiliza un árbol rojo-negro para almacenar los pares clave-valor. Garantiza un ordenamiento natural de las claves o permite especificar un comparador personalizado para el ordenamiento.
- Ordenamiento natural o personalizado: TreeMap garantiza un ordenamiento natural de las claves o permite especificar un comparador personalizado para el ordenamiento, lo que lo hace útil en situaciones donde se necesita un orden específico de los elementos.
- Eficiencia en operaciones ordenadas: TreeMap proporciona operaciones de búsqueda, inserción y eliminación eficientes en conjuntos de datos ordenados.
- Rendimiento de inserción y eliminación: Aunque TreeMap proporciona un ordenamiento natural de las claves o un ordenamiento personalizado, las operaciones de inserción y eliminación son más lentas en comparación con HashMap. Esto se debe a la necesidad de mantener la estructura del árbol rojo-negro para garantizar el orden.
- Uso de memoria: TreeMap puede consumir más memoria que HashMap debido a la estructura del árbol rojo-negro, especialmente cuando el mapa contiene una gran cantidad de elementos.
Cuando usar?
- Se utiliza cuando necesitas un ordenamiento natural de las claves o un ordenamiento personalizado definido por un comparador.
- Útil cuando necesitas iterar sobre los elementos en un orden específico, como orden alfabético o numérico.
Esta implementación mantiene un orden de inserción de los elementos, además de permitir un acceso rápido a través de una estructura de lista doblemente enlazada. Combina las características de HashMap con un registro del orden de inserción.
- Mantenimiento del orden de inserción: LinkedHashMap mantiene el orden de inserción de los elementos, lo que es útil cuando necesitas iterar sobre los elementos en el mismo orden en que fueron insertados.
- Rendimiento predecible en operaciones de iteración: LinkedHashMap proporciona un rendimiento predecible en operaciones de iteración y es más rápido que TreeMap en operaciones que no requieren ordenamiento.
- Consumo de memoria: LinkedHashMap puede consumir más memoria que HashMap debido a la necesidad de mantener una lista doblemente enlazada para mantener el orden de inserción.
- Rendimiento de iteración: Aunque LinkedHashMap mantiene el orden de inserción, las operaciones de iteración pueden ser ligeramente más lentas que en HashMap debido al mantenimiento de la lista enlazada.
Cuando usar?
- Se utiliza cuando necesitas mantener el orden de inserción de los elementos.
- Útil cuando necesitas iterar sobre los elementos en el mismo orden en que fueron insertados.
- También proporciona un acceso rápido a los elementos a través de la tabla hash.
Es una versión concurrente de HashMap, diseñada para admitir operaciones concurrentes sin bloqueos. Proporciona un alto rendimiento para aplicaciones con múltiples hilos de ejecución.
- Acceso seguro para subprocesos: ConcurrentHashMap proporciona acceso seguro para subprocesos sin necesidad de sincronización adicional, lo que lo hace ideal para entornos de programación concurrente.
- Alto rendimiento en operaciones concurrentes: ConcurrentHashMap proporciona un alto rendimiento para operaciones concurrentes sin bloqueos, lo que lo hace adecuado para aplicaciones con múltiples hilos de ejecución.
- Complejidad de uso: Aunque ConcurrentHashMap proporciona acceso seguro para subprocesos sin necesidad de sincronización adicional, su uso correcto puede ser más complejo que otras implementaciones debido a las garantías de consistencia débil y la necesidad de comprender los detalles de su comportamiento concurrente.
Cuando usar?
- Se utiliza en entornos multi-hilo donde múltiples hilos pueden acceder y modificar el mapa concurrentemente.
- Proporciona un alto rendimiento para operaciones concurrentes sin bloqueos.
- Útil cuando se necesita una estructura de datos de mapa segura para hilos.
Implementa una tabla hash basada en referencias débiles. Las claves en un WeakHashMap son referencias débiles, lo que significa que pueden ser recolectadas por el recolector de basura si no hay otras referencias fuertes a ellas.
- Asociación de información con objetos débiles: WeakHashMap es útil para asociar información con objetos que pueden ser recolectados por el recolector de basura cuando ya no son referenciados, lo que facilita la gestión de memoria en ciertos escenarios.
- Recogida de basura: Aunque WeakHashMap es útil para asociar información con objetos que pueden ser recolectados por el recolector de basura, debes tener cuidado al usarlo, ya que las entradas débiles pueden ser eliminadas en cualquier momento durante la recolección de basura, lo que puede afectar el comportamiento esperado de tu aplicación.
Cuando usar?
- Se utiliza cuando necesitas asociar información con objetos que pueden ser recolectados por el recolector de basura cuando ya no son referenciados.
- Útil para implementar cachés o estructuras de datos donde los objetos deben ser eliminados cuando no están en uso.
Es una implementación de Map que compara las claves utilizando el operador de identidad (==) en lugar del método equals(). Es útil en situaciones donde la igualdad de objetos se define por su identidad en lugar de su estado.
- Comparación basada en identidad: IdentityHashMap compara las claves utilizando la identidad (==) en lugar del método equals(), lo que lo hace útil en situaciones donde la igualdad de objetos se define por su identidad en lugar de su estado.
- Comparación basada en identidad: IdentityHashMap compara las claves utilizando la identidad (==) en lugar del método equals(). Esto puede llevar a resultados inesperados si estás acostumbrado a usar la igualdad basada en el método equals() y no tienes en cuenta la identidad de los objetos.
Cuando usar?
- Se utiliza cuando necesitas comparar las claves utilizando la identidad de los objetos (operador ==) en lugar del método equals().
- Útil en situaciones donde la igualdad de objetos se define por su identidad en lugar de su estado.
Son un tipo de datos especial para crear objetos inmutables.
- Introducidos en Java 14 y confirmados como característica permanente en Java 16.
- Permiten la creación de objetos inmutables de forma concisa.
- Diseñados para representar datos simples de una manera más compacta que las clases tradicionales.
Normalmente, escribimos clases para simplemente contener datos, resultados de consultas o información de un servicio.
- Facilitar la creación de objetos inmutables.
- Reducir la verbosidad del código al definir clases de datos.
- Mejorar la legibilidad y mantenibilidad del código.
- Atributos finales e inmutables.
- Métodos equals, hashCode y toString generados automáticamente.
- Sintaxis concisa y legible.
- No permiten herencia, pero pueden implementar interfaces.
- Útiles para DTOs y representación de datos simples.
package com.mcalvaro.records;
public record CategoryRecord( int categoryId, String name) {
}- Una cola es una estructura de datos abstractos lineales con el orden particular de realizar operaciones: primero en entrar, primero en salir (FIFO).

- Queue en Java es una interfaz. La interfaz Queue tiene 2 superinterfaces, 4 interfaces diferentes que heredan de la cola y una lista de clases que lo implementan.
Colección<E>Iterable<E>
Deque<E>BlockingDeque<E>BlockingQueue<E>TransferQueue<E>
LinkedListPriorityQueueAbstractQueueArrayBlockingQueueArrayDequeConcurrentLinkedDequeConcurrentLinkedQueueDelayQueueLinkedBlockingDequeLinkedBlockingQueueLinkedTransferQueuePriorityBlockingQueueSynchronousQueue
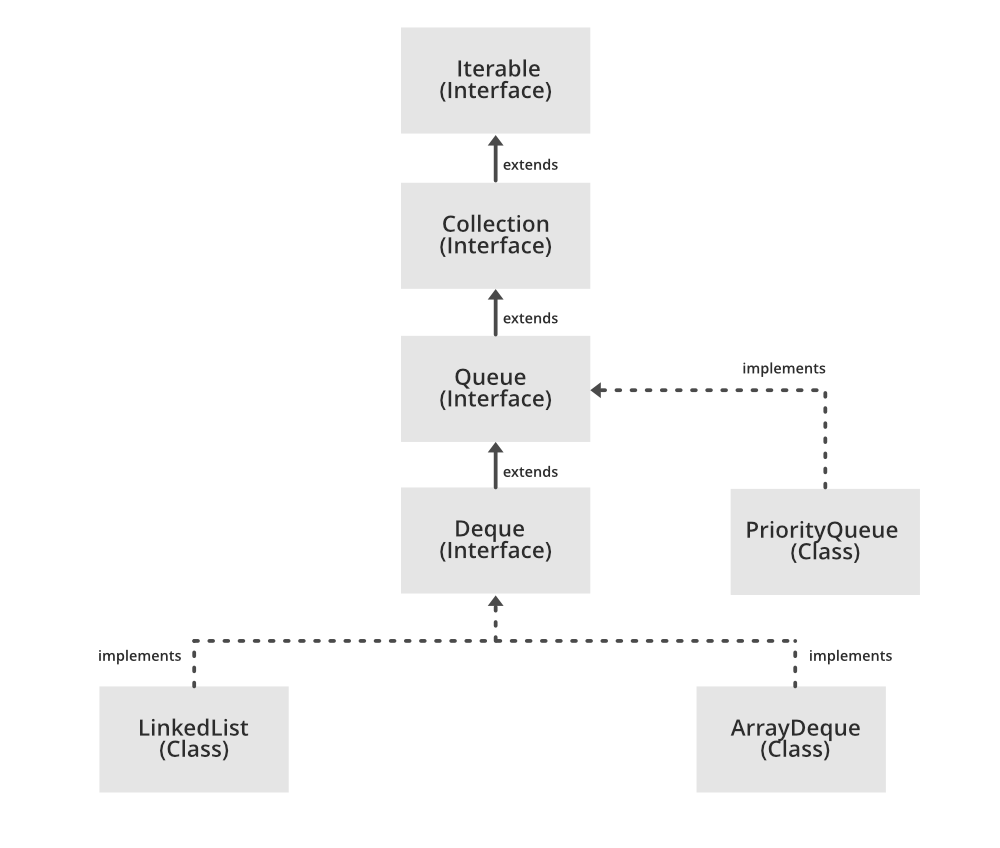
La interfaz Queue está presente en el paquete java.util, se utiliza para contener los elementos que están a punto de procesarse en orden FIFO (primero en entrar, primero en salir)
- Es una lista ordenada de objetos
- En Java, la interfaz Queue es un subtipo de la interfaz Collection y representa una colección de elementos en un orden específico
Al ser una interfaz, la cola necesita una clase concreta para la declaración y las clases más comunes son PriorityQueue y LinkedList en Java.
Tenga en cuenta que ninguna de estas implementaciones es segura para subprocesos.
PriorityBlockingQueuees una implementación alternativa si se necesita una implementación segura para subprocesos.
package com.mcalvaro;
import java.util.LinkedList;
import java.util.Queue;
public class MainApplication {
public static void main(String[] args) {
System.out.println("Queue Interface");
Queue<String> queue = new LinkedList<>();
}
}- La interfaz Queue proporciona varios métodos para agregar, eliminar e inspeccionar elementos en la cola
-
add(element)-> Agrega un elemento al final de la cola. Si la cola está llena, genera una excepción. -
offer(element)-> agrega un elemento al final de la cola. Si la cola está llena, devuelve falso -
remove()-> elimina y devuelve el elemento al principio de la cola. Si la cola está vacía, genera una excepción -
poll()-> elimina y devuelve el elemento al principio de la cola. Si la cola está vacía, devuelve nulo. -
element()-> Devuelve el elemento al principio de la cola sin eliminarlo. Si la cola está vacía, genera una excepción. -
peek()-> Devuelve el elemento al principio de la cola sin eliminarlo. Si la cola está vacía, devuelve nulo.
-
La interfaz Deque presente en el paquete java.util es un subtipo de la interfaz Queue
Los Deques soportan la inserción y extracción del elemento por ambos extremos.
Se puede utilizar como cola (primero en entrar, primero en salir/FIFO) o como pila (último en entrar, primero en salir/LIFO)
- De doble extremo: La principal ventaja de la interfaz Deque es que proporciona una cola de doble extremo, que permite agregar y eliminar elementos de ambos extremos de la cola
- Flexibilidad: La interfaz Deque proporciona una serie de métodos para agregar, eliminar y recuperar elementos de ambos extremos de la cola, lo que le brinda una gran flexibilidad en su uso.
-
Operaciones de bloqueo: La interfaz Deque proporciona métodos de bloqueo, como
takeFirstytakeLast, que le permiten esperar a que los elementos estén disponibles o que haya espacio disponible en la cola.
- Rendimiento: el rendimiento de un Deque puede ser más lento que el de otras estructuras de datos, como una lista vinculada o una matriz, porque proporciona más funcionalidad.
- Dependiente de la implementación: el comportamiento de un Deque puede depender de la implementación que utilice. Por ejemplo, algunas implementaciones pueden proporcionar operaciones seguras para subprocesos, mientras que otras no.
Se utiliza PriorityQueue cuando se supone que los objetos deben procesarse según la prioridad. Los elementos de la cola de prioridad se ordenan según el orden natural o mediante un comparador proporcionado en el momento de la construcción de la cola, según el constructor que se utilice.
La clase implementa las interfaces
Serializable,Iterable<E>,Collection<E>,Queue<E>.
-
PriorityQueue no permite valores nulos.
-
No podemos crear una PriorityQueue de objetos que no sean comparables. (Requiere que los objetos que almacena sean comparables, ya que necesita ordenarlos internamente según un criterio de prioridad)
-
PriorityQueue son colas independientes (Cada instancia de PriorityQueue es independiente de las demás.).
-
Si varios elementos tienen el mismo valor más bajo, uno de ellos se seleccionará de forma arbitraria para ser la cabeza.
-
Dado que PriorityQueue no es seguro para subprocesos, Java proporciona la clase
PriorityBlockingQueue -
Hereda métodos de las clases
AbstractQueue,AbstractCollection`` ,CollectionyObject`.
PriorityQueue(): Crea una PriorityQueue con la capacidad inicial predeterminada (11) que ordena sus elementos según su orden natural.
PriorityQueue<E> pq = nueva PriorityQueue<E>();Los virtual threads (hilos virtuales) son una nueva característica de Java que aborda las limitaciones en el modelo de concurrencia tradicional de Java.
Los Virtual Threads son una característica introducida en Java 21 como parte del Project Loom. Son hilos gestionados por la JVM y no por el sistema operativo, lo que permite crear y manejar millones de hilos de forma eficiente.
- Threads Tradicionales: Gestionados por el sistema operativo, costosos en términos de recursos, limitados en número.
- Virtual Threads: Hilos livianos gestionados por la JVM, permitiendo una concurrencia masiva con bajo consumo de recursos.
- Escalabilidad: Permiten manejar millones de hilos simultáneamente, ideales para aplicaciones con alta concurrencia.
- Simplicidad: Facilitan la programación concurrente, eliminando la necesidad de pools de hilos.
- Compatibilidad: Funcionan con las APIs estándar de Java y se integran fácilmente en el código existente.
- Tareas CPU-bound: No son ideales para tareas que consumen intensamente la CPU, donde no ofrecen beneficios significativos sobre los hilos tradicionales.
- Nuevas Prácticas: Requieren considerar nuevas prácticas de desarrollo y un cambio en la mentalidad de programación.
- Creación y Manejo: Se pueden crear fácilmente usando métodos como Thread.startVirtualThread y Thread.ofVirtual.
- Sin Afinidad de Procesador: No mantienen afinidad con hilos específicos del sistema operativo.
- Daemon Threads: Siempre se ejecutan como hilos daemon.
- Prioridad Fija: No se puede cambiar su prioridad.
La clase Thread proporciona algunos métodos para construir con ellos instancias de un VirtualThread. Por ejemplo: startVirtualThread, crea el virtual thread y lo inicia, todo en una misma operación.
Runnable task = () -> System.out.println("Hello World!");
// Creating and starting the thread in the same operation
Thread.startVirtualThread(task);También usando el método ofVirtual() que devuelve un Builder para crear paso a paso el hilo deseado.
//Creating the Virtual thread, and then Running the start method.
var thread = Thread.ofVirtual().start(task);
var thread2 = Thread.ofVirtual().name("My Thread").start(task);o podemos crear un virtual thread pero sin iniciarlo
var unstartedThread = Thread.ofVirtual().unstarted();
//... some other logic...
unstartedThread.started(); //Now starts the threadUn pool de threads es una estrategia válida para reutilizar los threads de plataforma costosos para múltiples tareas, pero con los threads virtuales, que son livianos y económicos, no es necesario crear un grupo de ellos. ExecutorService es una API que proporciona algunos grupos de subprocesos en Java y se usa ampliamente en muchas aplicaciones.
Si se quiere aprovechar los beneficios de los threads virtuales pero sin refactorizar el código existente mediante ExecutorService, puede utilizar la implementación VirtualThreadPerTaskExecutor. Como su nombre lo indica, crea un Executor que crea thread virtuales por Tarea, en otras palabras, no está reutilizando o “agrupando” los hilos virtuales.
Runnable task = () -> System.out.println("Hello, world");
ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();
executorService.execute(task);La eliminación de la participación del sistema operativo en el ciclo de vida de un subproceso virtual es lo que elimina el cuello de botella de escalabilidad. Con esto, hay una reducción drástica de los requisitos de recursos para manejar múltiples procesos en competencia, dando como resultado un mayor rendimiento.
Desde Java 21, "Sequenced Collections" es una nueva característica añadida a las clases/interfaces Collection existentes que les permite acceder al primer y al último elemento de la misma utilizando los nuevos métodos por defecto. La característica también nos permite obtener una vista invertida de la colección con una simple llamada a un método.
Hay que tener en cuenta que el orden de encuentro no implica la posición física de los elementos. Sólo significa que un elemento está antes (más cerca del primer elemento) o después (más cerca del último elemento) del otro elemento.
Profundicemos en esta nueva característica añadida desde Java 21.
Esta nueva iniciativa [JEP-431] introduce 3 nuevas interfaces en la jerarquía de colecciones que permiten que las clases de colecciones existentes tengan un orden de encuentro definido. El orden tendrá un primer elemento bien definido, el segundo elemento, y así sucesivamente, hasta el último elemento.
Estas nuevas interfaces son:
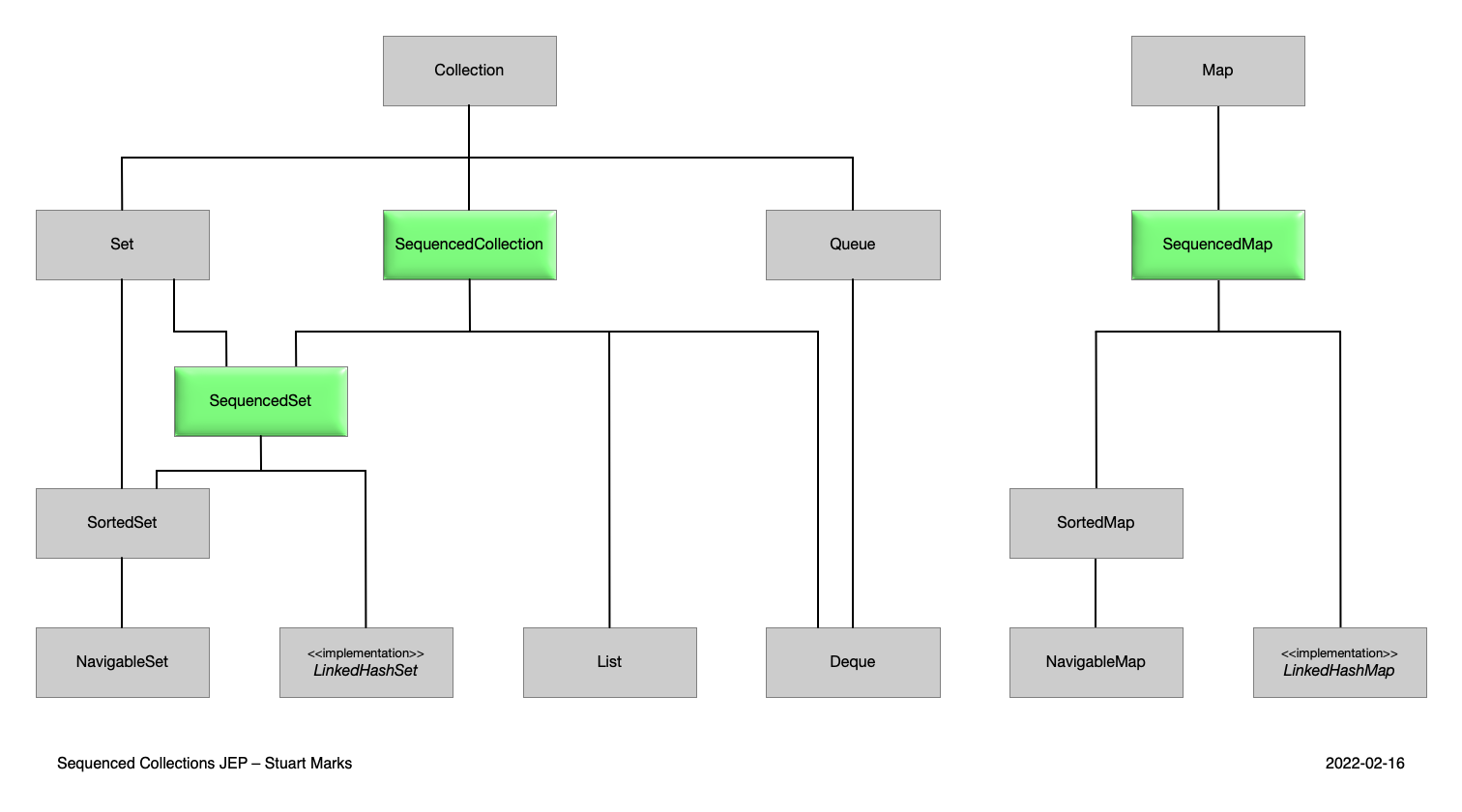
La motivación para introducir las interfaces secuenciadas es una larga demanda pendiente de métodos sencillos para obtener el primer y el último elemento de una colección. Actualmente, antes de Java 21, si queremos obtener el primer y el último elemento de una ArrayList codificaríamos:
Not a Clean Code
var firstItem = arrayList.iterator().next();
var lastItem = arrayList.get(arrayList.size() - 1);Con las nuevas Sequenced Collections, podemos obtener el primer y el último elemento utilizando métodos más sencillos:
This is Clean
var firstItem = arrayList.getFirst();
var lastItem = arrayList.getLast();La interfaz SequencedCollection proporciona métodos para añadir, recuperar y eliminar elementos en cualquiera de los extremos de la colección, junto con el método reversed(), que proporciona una vista con orden inverso de esta colección.
Como podemos ver todos los métodos, excepto reversed(), son métodos por defecto y proporcionan una implementación por defecto.
SequencedCollection.java
interface SequencedCollection<E> extends Collection<E> {
// New Method
SequencedCollection<E> reversed();
// Promoted methods from Deque<E>
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}Por ejemplo, el siguiente programa crea una ArrayList y realiza nuevas operaciones secuenciadas en esta lista.
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(1); // List contains: [1]
arrayList.addFirst(0); // List contains: [0, 1]
arrayList.addLast(2); // List contains: [0, 1, 2]
Integer firstElement = arrayList.getFirst(); // 0
Integer lastElement = arrayList.getLast(); // 2
List<Integer> reversed = arrayList.reversed();
System.out.println(reversed); // Prints [2, 1, 0]Tenga en cuenta que cualquier modificación de la lista es visible en los métodos, incluida la vista inversa.
// previous code ...
arrayList.add(3);
System.out.println( arrayList ); //[0, 1, 2, 3]
System.out.println( arrayList.reversed() ); //[3, 2, 1, 0]La interfaz SequencedSet es específica de las implementaciones de Set como LinkedHashSet. SequencedSet hereda SequencedCollection y sobreescribe su método reversed() y la única diferencia es que el tipo de retorno de SequencedSet.reversed() es SequencedSet.
SequencedSet.java
interface SequencedSet<E> extends SequencedCollection<E>, Set<E> {
SequencedSet<E> reversed();
}Veamos un ejemplo de utilización de estos métodos en sets.
LinkedHashSet<Integer> linkedHashSet = new LinkedHashSet<>(List.of(1, 2, 3));
Integer firstElement = linkedHashSet.getFirst(); // 1
Integer lastElement = linkedHashSet.getLast(); // 3
linkedHashSet.addFirst(0); //List contains: [0, 1, 2, 3]
linkedHashSet.addLast(4); //List contains: [0, 1, 2, 3, 4]
System.out.println(linkedHashSet.reversed()); //Prints [5, 3, 2, 1, 0]El SequencedMap es específico de las clases Map, como LinkedHashMap. No implementa la SequencedCollection y proporciona sus propios métodos que aplican el orden de acceso a las entradas del mapa en lugar de elementos individuales.
SequencedMap.java
interface SequencedMap<K,V> extends Map<K,V> {
// New Methods
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// Promoted Methods from NavigableMap<K, V>
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}Las colecciones de vistas proporcionadas por los métodos keySet(), values(), entrySet(), sequencedKeySet(), sequencedValues() y sequencedEntrySet() reflejan el mismo orden de encuentro de los elementos. La diferencia es que los valores de retorno de los métodos sequencedKeySet(), sequencedValues() y sequencedEntrySet() son tipos secuenciados.
LinkedHashMap<Integer, String> map = new LinkedHashMap<>();
map.put(1, "One");
map.put(2, "Two");
map.put(3, "Three");
map.firstEntry(); //1=One
map.lastEntry(); //3=Three
System.out.println(map); //{1=One, 2=Two, 3=Three}
Map.Entry<Integer, String> first = map.pollFirstEntry(); //1=One
Map.Entry<Integer, String> last = map.pollLastEntry(); //3=Three
System.out.println(map); //{2=Two}
map.putFirst(1, "One"); //{1=One, 2=Two}
map.putLast(3, "Three"); //{1=One, 2=Two, 3=Three}
System.out.println(map); //{1=One, 2=Two, 3=Three}
System.out.println(map.reversed()); //{3=Three, 2=Two, 1=One}La clase Collections es una clase de utilidad que contiene métodos para operaciones comunes sobre tipos de colecciones. Una de estas operaciones es convertir una colección mutable en una inmutable.
Por ejemplo, el método Collections.unmodifiableList() devuelve una vista no modificable de la lista especificada. Siguiendo con el mismo tema, la clase Collections tiene ahora tres nuevos métodos que devuelven vistas inmutables para los nuevos tipos añadidos.
Collections.unmodifiableSequencedCollection(sequencedCollection);
Collections.unmodifiableSequencedSet(sequencedSet);
Collections.unmodifiableSequencedMap(sequencedMap);Las nuevas interfaces también afectan a los tipos de colección no modificables. Si intentamos utilizar las nuevas operaciones add o remove en una colección no modificable, nos encontraremos con la UnsupportedOperationException.
En el siguiente ejemplo, List es un tipo no modificable por lo que no podemos utilizar métodos como addFirst(), addLast() etc.
List<Integer> list = List.of(1, 2, 3);
//list.addLast(4); //Exception in thread "main" java.lang.UnsupportedOperationExceptionDel mismo modo, algunas colecciones ya tienen un orden de clasificación definido, y por lo tanto los métodos que fuerzan los órdenes (por ejemplo addFirst(), addLast() etc) no tienen sentido, invocar estos métodos lanzará UnsupportedOperationException.
TreeSet<Integer> set = new TreeSet(List.of(1, 2, 3));
// set.addFirst(4); //Exception in thread "main" java.lang.UnsupportedOperationExceptionSi intentamos utilizar los métodos secuenciados en una colección vacía, obtendremos la NoSuchElementException, porque no hay ningún elemento presente para devolver desde el método.
List<Integer> list = List.of();
//list.getFirst(); //Exception in thread "main" java.lang.NoSuchElementExceptionLos cambios en las Sequenced Collections se han integrado bien en el marco de trabajo de colecciones, y el código que simplemente utiliza implementaciones de colecciones no se verá afectado en gran medida. Aún así, si nuestras clases implementan otras interfaces Collection para crear tipos personalizados, pueden surgir algunas incompatibilidades.
Por ejemplo, si las implementaciones personalizadas existentes utilizan los métodos con el mismo nombre, surgirá un conflicto de nombres y es posible que tenga que refactorizar el código al actualizar a Java 21.
Del mismo modo, la interfaz List y Deque proporcionan anulaciones covariantes del método reversed(). El primer método devuelve List y el otro devuelve Deque.
Así que si la clase personalizada implementa ambas interfaces, List y Deque, entonces empezará a fallar a partir de Java 21.
class MyList implements List<T>, Deque<T> { // This will fail in Java 21
//...
}La solución para corregir este error es definir un nuevo método reversed() en la clase MyList y devolver un tipo que sea subtipo de List así como de Deque. En nuestro caso, MyList implementa ambas interfaces por lo que podemos devolverlo desde el método reversed().
class MyList implements List<T>, Deque<T> { // This will work
//...
MyList<E> reversed() {
// implement the reversed method
}
}La Sequenced Collection es una gran adición para hacer el lenguaje Java más adaptable y fácil de usar para los nuevos desarrolladores. La mayoría de las colecciones Java ya tenían un orden de encuentro definido a través de iteradores, las nuevas interfaces lo hacen más oficial y proporcionan métodos de uso directo para que sea aún más fácil interactuar con los elementos de ambos extremos de una colección.
Las plantillas de cadenas(String templates) es la representación en tiempo de ejecución de una plantilla de cadena o plantilla de bloque de texto en una expresión de plantilla.
Las plantillas de cadenas complementan los literales de cadena y los bloques de texto existentes de Java acoplando texto literal con expresiones integradas y procesadores de plantillas para producir resultados especializados.
Una expresión incrustada es una expresión Java excepto que tiene una sintaxis adicional para diferenciarla del texto literal en la plantilla de cadena. Un procesador de plantillas combina el texto literal de la plantilla con los valores de las expresiones incrustadas para producir un resultado.
Esta es una función de vista previa. Una función de vista previa es una función cuyo diseño, especificación e implementación están completas, pero no son permanentes. Es posible que exista una función de vista previa en una forma diferente o que no exista en futuras versiones de Java SE. Para compilar y ejecutar código que contiene funciones de vista previa, debe especificar opciones de línea de comandos adicionales.
String name = "Raul";
String info = STR."Mi nombre es \{name}";
System.out.println(info); El procesador de plantillas STR es uno de los procesadores de plantillas incluidos en el JDK. Realiza automáticamente la interpolación de cadenas reemplazando cada expresión incrustada en la plantilla con su valor, convertido en una cadena. El JDK incluye otros dos procesadores de plantillas:
- El procesador de plantillas FMT: es como el procesador de plantillas STR excepto que acepta especificadores de formato como se define en java.util.Formatter e información local de manera similar a como en las invocaciones del método printf.
- El procesador de plantillas RAW: no procesa automáticamente la plantilla de cadena como los procesadores de plantillas STR. Puede usarlo como ayuda para crear sus propios procesadores de plantillas. Tenga en cuenta que también puede implementar la interfaz StringTemplate.Processor para crear un procesador de plantilla.
Una plantilla de cadena sigue al carácter de punto, que es una cadena que contiene una o más expresiones incrustadas. Una expresión incrustada es una expresión Java rodeada por una barra invertida y una llave de apertura ({) y una llave de cierre }.
Puede utilizar cualquier expresión Java como expresión incrustada en una plantilla de cadena.
Ejemplos:
Las expresiones incrustadas pueden contener cadena y un caracter:
String jugador = "r4u1";
char vidas = '3';
String mensaje = STR."El jugador \{jugador} tiene \{vidas} intentos para terminar el juego.";
System.out.println(mensaje);Las expresiones incrustadas pueden contener operaciones aritméticas
double x = 10.5, y = 20.6;
String p = STR."\{x} * \{y} = \{x * y}";
System.out.println(p);Como ocurre con cualquier expresión Java, las expresiones incrustadas se evalúan de izquierda a derecha. También pueden contener operadores de prefijo y postfijo.
int index = 0;
String data = STR."\{index++}, \{index++}, \{++index}, \{index++}, \{index}";
System.out.println(data);Las expresiones incrustadas pueden invocar métodos y acceder a campos.
String message2 = STR. "Hoy es \{ getToday()
}, y la temperatura es de \{
getTemperature() } grados";
System.out.println(message2);una plantilla dentro de otra
String[] a = { "X", "Y", "Z" };
String letters = STR."\{a[0]}, \{STR."\{a[1]}, \{a[2]}"}";
System.out.println(letters);Cuando especifica la plantilla para cadenas multilínea, puede usar un bloque de texto en lugar de una cadena normal. Esto le permite utilizar documentos HTML y datos JSON más fácilmente con plantillas de cadenas, como se demuestra en los siguientes ejemplos.
String title = "Pagina Web Demo";
String text = "Contenido de la pagina web";
String webpage = STR."""
<html>
<head>
<title>\{title}</title>
</head>
<body>
<p>\{text}</p>
</body>
</html>
""";
System.out.println(webpage);String customerName = "Java Name";
String phone = "72557839";
String address = "Av. Las Americas Nro 4563";
String json = STR."""
{
"name": "\{customerName}",
"phone": "\{phone}",
"address": "\{address}"
}
""";
System.out.println(json);record Circle(String name, double radius) {
double area() {
return Math.PI * Math.pow(radius, 2);// πr2
}
}
Circle[] zone = new Circle[] {
new Circle("Primer Circulo", 17.8),
new Circle("Segundo Circulo", 9.6),
};
String table = STR."""
Descripcion\tRadio\tArea
\{zone[0].name}\t\t\{zone[0].radius}\t\{zone[0].area()}
\{zone[1].name}\t\t\{zone[1].radius}\t\{zone[1].area()}
Total \{zone[0].area() + zone[1].area()}
""";
System.out.println(table);El procesador de plantillas FMT es como el procesador de plantillas STR excepto que puede usar especificadores de formato que aparecen a la izquierda de una expresión incrustada. Estos especificadores de formato son los mismos que los definidos en la clase java.util.Formatter.
String formattedTable = FormatProcessor.FMT."""
Descripcion\t\tRadio\tArea
%-12s\{zone[0].name}\t%7.2f\{zone[0].radius}\t%7.2f\{zone[0].area()}
%-12s\{zone[1].name}\t%7.2f\{zone[1].radius}\t%7.2f\{zone[1].area()}
\{" ".repeat(18)} Total %7.2f\{zone[0].area() + zone[1].area()}
""";
System.out.println(formattedTable);El procesador de plantillas RAW pospone el procesamiento de la plantilla para un momento posterior. En consecuencia, puede recuperar los literales de cadena de la plantilla y los resultados de las expresiones incrustadas antes de procesarlos.
Para recuperar los literales de cadena de una plantilla y los resultados de las expresiones incrustadas, llame a StringTemplate::fragments y StringTemplate::values, respectivamente. Para procesar una plantilla de cadena, llame a StringTemplate.process(StringTemplate.Processor) o StringTemplate.Processor.process(StringTemplate). También puedes llamar al método StringTemplate::interpolate, que devuelve el mismo resultado que el procesador de plantillas STR.
int v = 10, w = 20;
StringTemplate rawST = StringTemplate.RAW."\{v} mas \{w} igual \{v + w}";
java.util.List<String> fragments = rawST.fragments();
java.util.List<Object> values = rawST.values();
System.out.println(rawST.toString());
fragments.stream().forEach(f -> System.out.print("[" + f + "]"));
System.out.println();
values.stream().forEach(val -> System.out.print("[" + val + "]"));
System.out.println();
System.out.println(rawST.process(STR));
System.out.println(STR.process(rawST));
System.out.println(rawST.interpolate());Los patrones sin nombre pueden aparecer en una lista de patrones de un patrón de registro y siempre coinciden con el componente de registro correspondiente. Puedes usarlos en lugar de un patrón tipográfico. Eliminan la carga de tener que escribir un tipo y nombre de una variable de patrón que no es necesaria en el código posterior. Las variables sin nombre son variables que se pueden inicializar pero no utilizar. Ambos se indican con el carácter de subrayado (_).
Esta es una función de vista previa.
Considere el siguiente ejemplo que calcula la distancia entre dos instancias de ColoredPoint:
record Point(double x, double y) {}
enum Color { RED, GREEN, BLUE }
record ColoredPoint(Point p, Color c) {}
double getDistance(Object obj1, Object obj2) {
if (obj1 instanceof ColoredPoint(Point p1, Color c1) &&
obj2 instanceof ColoredPoint(Point p2, Color c2)) {
return java.lang.Math.sqrt(
java.lang.Math.pow(p2.x - p1.x, 2) +
java.lang.Math.pow(p2.y - p1.y, 2));
} else {
return -1;
}
}El ejemplo no utiliza el componente Color del registro ColoredPoint. Para simplificar el código y mejorar la legibilidad, puede omitir o eliminar los patrones de tipo Color c1 y Color c2 con el patrón sin nombre (_):
double getDistance(Object obj1, Object obj2) {
if (obj1 instanceof ColoredPoint(Point p1, _) &&
obj2 instanceof ColoredPoint(Point p2, _)) {
return java.lang.Math.sqrt(
java.lang.Math.pow(p2.x - p1.x, 2) +
java.lang.Math.pow(p2.y - p1.y, 2));
} else {
return -1;
}
}Ningún valor está vinculado a la variable de patrón sin nombre. En consecuencia, la declaración resaltada en el siguiente ejemplo no es válida:
if (obj1 instanceof ColoredPoint(Point p1, Color _) &&
obj2 instanceof ColoredPoint(Point p2, Color _)) {
// Compiler error: the underscore keyword '_" is only allowed to
// declare unnamed patterns, local variables, exception parameters or
// lambda parameters
System.out.println("Color: " + _);
// ...
} Puede utilizar patrones sin nombre en expresiones y declaraciones de switch:
sealed interface Employee permits Salaried, Freelancer, Intern { }
record Salaried(String name, long salary) implements Employee { }
record Freelancer(String name) implements Employee { }
record Intern(String name) implements Employee { }
static void printSalary(Employee b) {
switch (b) {
case Salaried r -> System.out.println("Salary: " + r.salary());
case Freelancer _ -> System.out.println("Other");
case Intern _ -> System.out.println("Other");
}
}Puede utilizar varios patrones en una etiqueta de caso siempre que no declaren ninguna variable de patrón. Por ejemplo, puede reescribir la declaración de cambio anterior de la siguiente manera:
switch (b) {
case Salaried r -> System.out.println("Salary: " + r.salary());
case Freelancer _, Intern _ -> System.out.println("Other");
}Puede utilizar la palabra clave de guión bajo (_) no solo como patrón en una lista de patrones, sino también como nombre de una variable local, excepción o parámetro lambda en una declaración cuando el valor de la declaración no es necesario. Esto se llama variable sin nombre, que representa una variable que se está declarando pero que no tiene un nombre utilizable.
Las variables sin nombre son útiles cuando el efecto secundario de una declaración es más importante que su resultado.
Considere el siguiente ejemplo que itera a través de los elementos de la matriz orderID con un bucle for. El efecto secundario de este bucle for es que calcula el número de elementos en los ID de pedido sin utilizar nunca la variable id del bucle:
int[] orderIDs = {34, 45, 23, 27, 15};
int total = 0;
for (int id : orderIDs) {
total++;
}
System.out.println("Total: " + total);Puede utilizar una variable sin nombre para omitir la identificación de la variable no utilizada:
int[] orderIDs = {34, 45, 23, 27, 15};
int total = 0;
for (int _ : orderIDs) {
total++;
}
System.out.println("Total: " + total);Un parámetro de excepción de un bloque catch
static void validateNumber(String s) {
try {
int i = Integer.parseInt(s);
System.out.println(i + " is valid");
} catch (NumberFormatException _) {
System.out.println(s + " isn't valid");
}
} Puede utilizar un patrón de registro para probar si un valor es una instancia de un tipo de clase de registro y, si lo es, realizar de forma recursiva una coincidencia de patrones en los valores de sus componentes.
El siguiente ejemplo prueba si obj es una instancia del registro Punto con el patrón de registro Punto(doble x, doble y):
record Point(double x, double y) {}
static void printAngleFromXAxis(Object obj) {
if (obj instanceof Point(double x, double y)) {
System.out.println(Math.toDegrees(Math.atan2(y, x)));
}
} Este ejemplo extrae los valores x,y de obj directamente, llamando automáticamente a los métodos de acceso del registro Point.
Un patrón de registro consta de un tipo y una lista de patrones de registro (posiblemente vacía). En este ejemplo, el tipo es Punto y la lista de patrones es (doble x, doble y).
El siguiente ejemplo es igual que el anterior excepto que utiliza un patrón de tipo en lugar de un patrón de registro:
static void printAngleFromXAxisTypePattern(Object obj) {
if (obj instanceof Point p) {
System.out.println(Math.toDegrees(Math.atan2(p.y(), p.x())));
}
} Si una clase de registro es genérica, entonces puede especificar explícitamente los argumentos de tipo en un patrón de registro. Por ejemplo:
record Box<T>(T t) { }
static void printBoxContents(Box<String> bo) {
if (bo instanceof Box<String>(String s)) {
System.out.println("Box contains: " + s);
}
}Puede probar si un valor es una instancia de un tipo de registro parametrizado siempre que el valor pueda convertirse al tipo de registro en el patrón sin requerir una conversión sin marcar. El siguiente ejemplo no se compila:
static void uncheckedConversion(Box bo) {
// error: Box cannot be safely cast to Box<String>
if (bo instanceof Box<String>(var s)) {
System.out.println("String " + s);
}
} Puede utilizar var en la lista de componentes del patrón de registro. En el siguiente ejemplo, el compilador deduce que las variables de patrón xey son de tipo doble:
static void printAngleFromXAxis(Object obj) {
if (obj instanceof Point(var x, var y)) {
System.out.println(Math.toDegrees(Math.atan2(y, x)));
}
} El compilador puede inferir el tipo de argumentos de tipo para patrones de registro en todas las construcciones que aceptan patrones: declaraciones de cambio, expresiones de cambio y expresiones de instancia de.
El siguiente ejemplo es equivalente a printBoxContents. El compilador infiere su argumento de tipo y variable de patrón: Box(var s) se infiere como Box(String s)
static void printBoxContentsAgain(Box<String> bo) {
if (bo instanceof Box(var s)) {
System.out.println("Box contains: " + s);
}
} Una instrucción switch transfiere el control a una de varias declaraciones o expresiones, dependiendo del valor de su expresión selectora. En versiones anteriores, la expresión del selector debe evaluarse como un número, cadena o constante de enumeración, y las etiquetas de caso deben ser constantes. Sin embargo, en esta versión, la expresión del selector puede ser cualquier tipo de referencia o un tipo int, pero no un tipo long, flotante, doble o booleano, y las etiquetas de casos pueden tener patrones. En consecuencia, una declaración o expresión switch puede probar si su expresión selectora coincide con un patrón, lo que ofrece más flexibilidad y expresividad en comparación con probar si su expresión selectora es exactamente igual a una constante.
Consideremos el siguiente código que calcula el perímetro de ciertas formas de la sección Coincidencia de patrones para la instancia del Operador:
interface Shape { }
record Rectangle(double length, double width) implements Shape { }
record Circle(double radius) implements Shape { }
public static double getPerimeter(Shape s) throws IllegalArgumentException {
if (s instanceof Rectangle r) {
return 2 * r.length() + 2 * r.width();
} else if (s instanceof Circle c) {
return 2 * c.radius() * Math.PI;
} else {
throw new IllegalArgumentException("Unrecognized shape");
}
}Puede reescribir este código para usar una expresión de patrón switch de la siguiente manera:
public static double getPerimeter(Shape s) throws IllegalArgumentException {
return switch (s) {
case Rectangle r -> 2 * r.length() + 2 * r.width();
case Circle c -> 2 * c.radius() * Math.PI;
default -> throw new IllegalArgumentException("Unrecognized shape");
};
}El siguiente ejemplo utiliza una declaración de cambio en lugar de una expresión switch:
public static double getPerimeter(Shape s) throws IllegalArgumentException {
switch (s) {
case Rectangle r: return 2 * r.length() + 2 * r.width();
case Circle c: return 2 * c.radius() * Math.PI;
default: throw new IllegalArgumentException("Unrecognized shape");
}
}El tipo de expresión de selector puede ser un tipo primitivo integral o cualquier tipo de referencia, como en los ejemplos anteriores. La siguiente expresión de cambio coincide con la expresión del selector obj con patrones de tipo que involucran un tipo de clase, un tipo de enumeración, un tipo de registro y un tipo de matriz:
record Point(int x, int y) { }
enum Color { RED, GREEN, BLUE; }
static void typeTester(Object obj) {
switch (obj) {
case null -> System.out.println("null");
case String s -> System.out.println("String");
case Color c -> System.out.println("Color with " + c.values().length + " values");
case Point p -> System.out.println("Record class: " + p.toString());
case int[] ia -> System.out.println("Array of int values of length" + ia.length);
default -> System.out.println("Something else");
}
}Puede agregar una expresión booleana justo después de una etiqueta de patrón con una cláusula when. Esto se llama etiqueta de patrón protegido. La expresión booleana en la cláusula when se llama guardia. Un valor coincide con una etiqueta de patrón protegido si coincide con el patrón y, de ser así, la protección también se evalúa como verdadera. Considere el siguiente ejemplo:
static void test(Object obj) {
switch (obj) {
case String s:
if (s.length() == 1) {
System.out.println("Short: " + s);
} else {
System.out.println(s);
}
break;
default:
System.out.println("Not a string");
}
}Puede mover la expresión booleana s.length == 1 justo después de la etiqueta del caso con una cláusula when:
static void test(Object obj) {
switch (obj) {
case String s when s.length() == 1 -> System.out.println("Short: " + s);
case String s -> System.out.println(s);
default -> System.out.println("Not a string");
}
}-
String Templates:
Introduce una nueva forma de construir cadenas de texto utilizando una sintaxis especial que permite incluir variables y expresiones directamente en las cadenas.
-
Beneficios:
- Mejora la legibilidad y la claridad del código.
- Reduce los errores comunes asociados con la concatenación de cadenas.
- Facilita la construcción de cadenas complejas de manera eficiente y segura.
-
Beneficios:
-
Unnamed Patterns and Variables:
Permite omitir nombres de variables y patrones cuando no se necesitan, utilizando el guion bajo (_).
-
Beneficios:
- Reduce el desorden y las advertencias sobre variables no utilizadas.
- Mejora la claridad del código al indicar explícitamente que ciertos valores se están ignorando.
- Proporciona una sintaxis más flexible y concisa para coincidencia de patrones y manejo de variables temporales.
-
Beneficios:
-
Record Patterns:
Introduce la deconstrucción de registros directamente en las declaraciones, lo que facilita el acceso a los datos contenidos en los registros.
-
Beneficios:
- Simplifica el acceso a los componentes de los registros.
- Mejora la seguridad de tipo y la claridad del código.
- Proporciona una sintaxis más limpia y mantenible para trabajar con datos inmutables.
-
Beneficios:
-
Pattern Matching for switch:
Permite usar coincidencia de patrones en las declaraciones y expresiones switch, simplificando las verificaciones de tipo y haciendo el código más conciso y legible.
-
Beneficios:
- Mejora la concisión y la claridad del código.
- Proporciona seguridad de tipo mejorada.
- Facilita el mantenimiento y la evolución del código.
-
Beneficios:
Finalmente estas características mejoras hacen que el código sea más fácil de leer, entender y mantener a largo plazo.