Anomaly - ecs-support/KM GitHub Wiki
- ที่มาบทความ : www.softnix.co.th
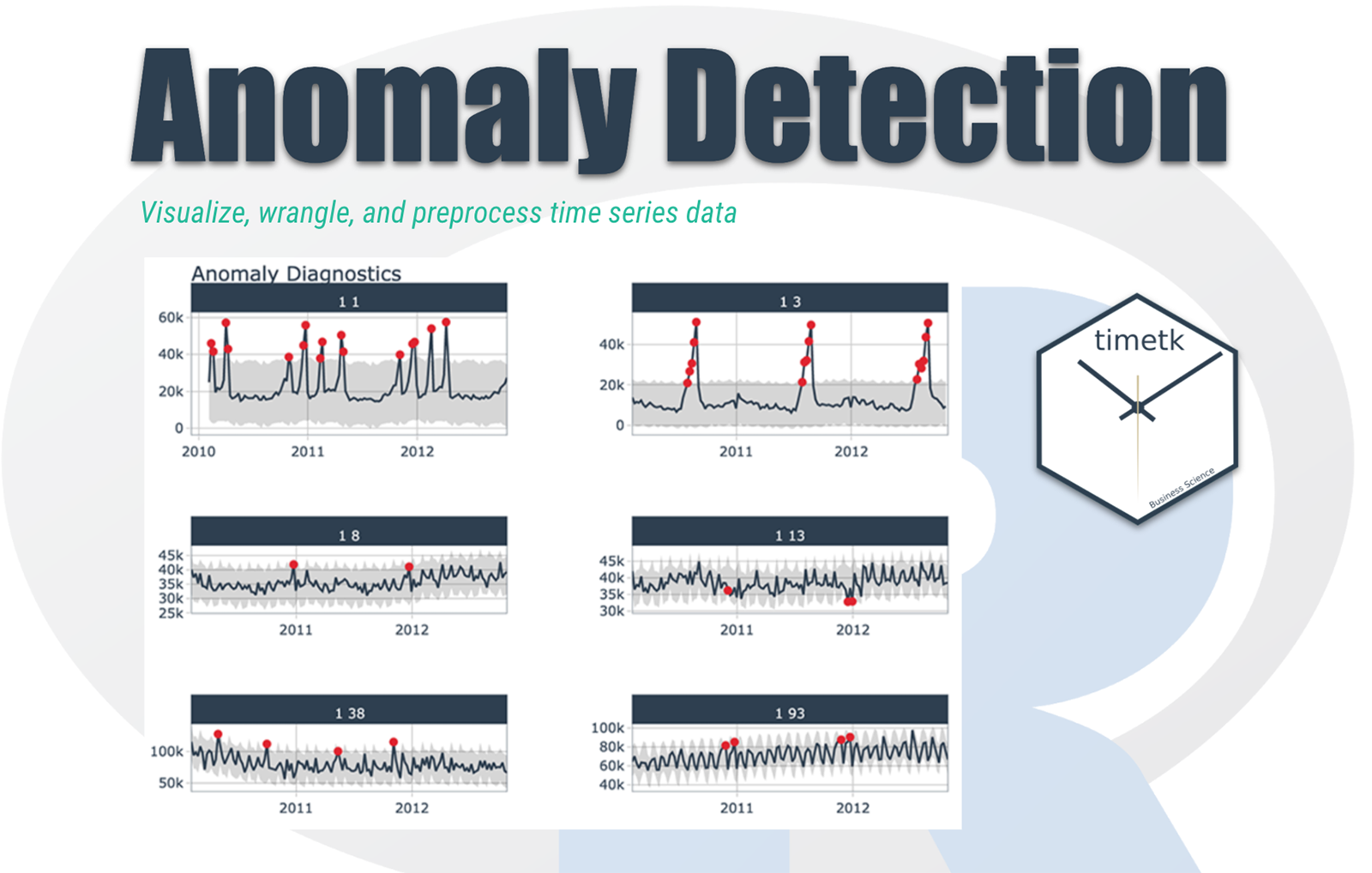
เกริ่นนำ
ในบางครั้งการใช้ Machine Learning ก็ไม่จำเป็นต้องใช้ท่ายากเสมอไป วันนี้เราจะมาหา Anomaly หรือ Outlier ด้วยวิธีที่เรารู้จักกันในนามของ Distribution หรือหากใครไม่คุ้นก็คงจะรู้จัก กราฟระฆังคว่ำ หรือ Normal Distribution หรือ Gaussian Distribution กันบ้าง แล้วเราจะสามารถใช้หา Anomaly ได้อย่างไร โปรดติดตามครับ
Anomaly คืออะไร
Anomaly หรือในอีกชื่อหนึ่งคือ Outlier คือสิ่งที่ผิดปรกติภายใน Data ซึ่งอาจเกิดจากความผิดพลาดที่มาจาก
Data Source ก็ดี หรือมาจากความผิดพลาดจากการกรอกข้อมูลก็ดี เราเรียก Data กลุ่มนี้ว่า Anomaly

https://medium.com/@praveengovi.analytics/outliers-what-it-say-during-data-analysis-75d664dcce04
Anomaly Detection
คือการใช้วิธีทางคณิตศาสตร์ สถิติ , Datamining , Machine Learning หรือ AI ดึงข้อมูลในอดีต (Historical Data) เพื่อคัดแยกสิ่งที่ผิด
ปรกติ (Anomaly) และ เป็นปรกติ (Normally) ออกจากกัน
กระบวนการของ Anomaly Detection
คือการนำข้อมูลจากอดีตเพื่อเข้ากระบวนการบางอย่างเช่น Model หรืือในที่นี้คือการดู Distribution หลังจากได้ Model แล้ว
เราสามารถแจ้ง Alert ให้ทราบว่าเกิด Anomaly ขึ้นและทำการแก้ไขป้องกันอย่างทันท่วงที

เราพบ Anomaly จากที่ใดบ้าง
จริงแล้ว Anomaly ไม่ใช่เรื่องไกลตัว เราสามารถพบ Anomaly ได้ทุกที่รอบตัวเช่น
อุณหภูมิที่ร้อนหรือหนาวเกินไป จำนวนคนที่เข้า Facebook Page ของเราที่น้อย หรือมากผิดปรกติ
ปริมาณ PM 2.5 ที่มากผิดปรกติ หรือ ราคาน้ำมันที่สูงผิดปรกติ ล้วนเป็นสิ่งรอบตัวที่เราพบ
และเป็นประโยชน์มาก ถ้าหากเรา Detect พบ เพื่อใช้ในการตัดสินใจหรือ Action ใดๆต่อไป
Characteristics ของ Anomaly
จากตัวอย่างด้านบน Anomaly นั้นมี Characteristics อย่างหนึ่ง นั่นคือ Anomaly จะมีปริมาณไม่เยอะมาก
เพราะว่าหาก Anomaly มีปริมาณเยอะแล้ว เราจะไม่เรียกว่า Anomaly อีกต่อไป ยกตัวอย่างเช่น
เมื่อ 5 ปีที่แล้วค่า PM 2.5 ไม่เคยเกิน 100 หากพบค่า PM 2.5 เกิน 100 เมื่อ 5 ปีที่แล้วเราจะเรียกว่าผิดปรกติ (Anomaly)
แต่ปัจจุบันค่า PM 2.5 มีค่ามากกว่า 100 เป็นปรกติเราจึงไม่ได้เรียกว่าผิดปรกติอีกต่อไป แต่เรากลับเรียกว่า PM 2.5 เกิน 100
เป็นปรกติ (Normally)
Distribution
ด้วยแนวความคิดที่ว่า Anomaly จะเกิดขึ้นได้ต้องมีปริมาณน้อย การแก้ไขปัญหาจึงแคบลง เราจึงสามารถใช้ Technique หนึ่งเรียกว่า
Distribution ในการหา Anomaly Detection ได้
Distribution หรือการแจกแจงความน่าจะเป็นใช้สำหรับดูการกระจายตัวของข้อมูลมีประโยชน์อย่างยิ่งสำหรับงานข้อมูล ไม่ว่าจะ
ใช้สำหรับดูว่า ข้อมูลที่ได้มานั้นเป็นตัวอย่างกลุ่มข้อมูลที่ครอบคลุมหรือไม่เป็นวิธีการเบื้องต้นเพื่อดูว่าข้อมูลเราจะ Overfit หรือไม่
แต่ในที่นี้เราใช้ประโยชน์ในอีกด้านหนึ่งกล่าวคือ ใช้ดูว่า Data ส่วนใดเป็นกลุ่มตัวอย่างทั่วไป (Normally) และ Data ใดคือกลุ่มตัวอย่างผิดปรกติ (Anomaly)
การประยุกตร์ใช้
ตัวอย่างด้านล่างคือข้อมูล CPU ของ AWS สามารถ Downlaod ได้ที่ https://www.kaggle.com/boltzmannbrain/nab
เมื่อลองดูการกระจายตัวของค่า CPU เราพบว่าค่า Normally จะอยู่ที่ 1.8-2.0

และเราจะพบว่ามีไม่บ่อยนักที่ค่า CPU จะมีค่าสูงเกิน 2.2 และทำนองเดียวกัน CPU จะมีค่าต่ำกว่า 1.7 โดยประมาณ

และพบว่าช่วงที่ CPU สูงนั้นมักจะเป็นช่วงเวลาประมาณตีสาม

จะเห็นได้ว่าการหา Anomaly เบื้องต้นนั้นใช้ Code เพียงไม่กี่บรรทัดก็สามารถที่จะหาความผิดปรกติเบื้องต้นได้ทั้งเรายังสามารถ
ประยุกตร์ใช้โดยให้ตั้ง Threshold ได้โดยนำค่าที่ไม่ควรเกิดขึ้นบ่อย 1% (เช่น 2.2 ขึ้นไป) ให้ Alert แจ้งยังผู้ดูและระบบเป็นต้น
Distribution อื่นๆ
ใน Distribution อื่นๆ เราสามารถตรวจดูว่ามีการกระจายตัวที่ช่วงใด เกิดขึ้นน้อย ก็มีโอกาสพบ Anomaly ได้เช่นกัน

จากรูปด้านซ้าย คือ Normal Distribution จุดที่พบ Anomaly คือ ตำแหน่งซ้ายและขวาของ Distribution
ส่วนรูปด้านขวาบนคือรูป Power-law Distribution ซึ่งมีการกระจายลักษณะคล้าย Exponential ซึ่งเราจะพบ Anomaly ได้ที่ด้านขวาเป็นต้น
ตัวอย่าง Colab สามารถดูได้จาก link ด้านล่างครับ
https://colab.research.google.com/drive/1Zv28_1zeWNJmNgfEQuFVAxdediNiYyIy
Conclusion
การหาสิ่งที่ผิดปรกติ (Anomaly Detection) เราสามารถใช้ Distribution หรือ Graph Histogram เพื่อดูการกระจายตัวว่าช่วงใดเป็นช่วงที่เป็นปรกติ (Normally) และช่วงใดคือช่วงที่ผิดปรกติ (Anomaly) อยู่ช่วงใดเพื่อที่เราจะสามารถ Drill down ไปยังข้อมูลนั้นเพื่อหาสาเหตุ
ที่แท้จริงหรือเพื่อประกอบการตัดสินใจ และเพื่อการนำข้อมูลไปใช้ให้เกิดประโยชน์อย่างแท้จริง
Reference
- https://machinelearningmastery.com/how-to-use-statistics-to-identify-outliers-in-data/
- http://berkeleyearth.lbl.gov/air-quality/maps/cities/Thailand/Bangkok/Bangkok.txt
- https://www.kaggle.com/boltzmannbrain/nab