2020年baseline解读以及跑苏神2020的baseline代码 - dylhhh/2020-LIC-RE- GitHub Wiki
- 2020官方baseline源码
- 2020苏神baseline源码
- 2020苏神baseline博客 1、2020年代码解读
模型思路:
一个结构化的tagging strategy来直接微调ERNIE,通过该策略,可以在一次扫描中提取多个重叠的SPOs。
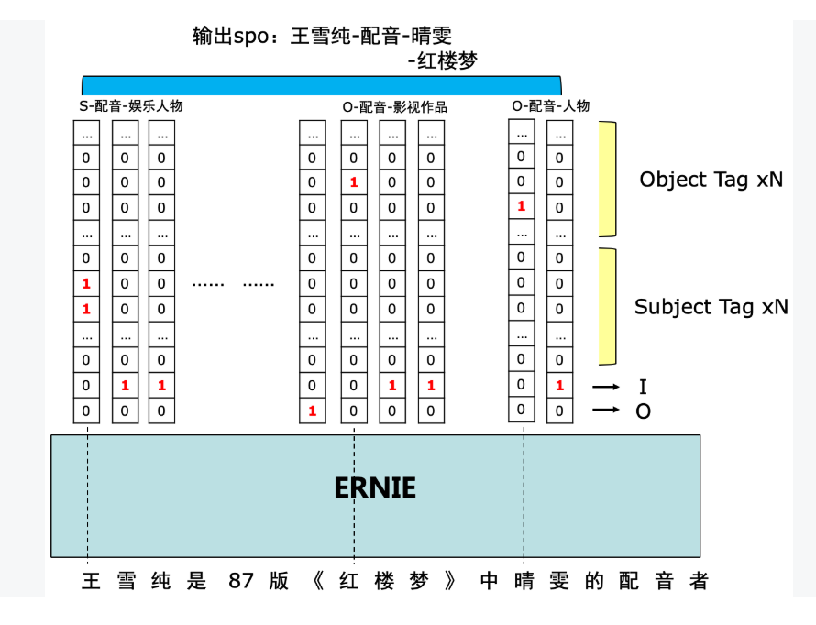
一、tagging strategy策略
tagging strategy是为了在DuIE 2.0任务中发现多个重叠的SPOs而设计的。
把predicate和object对应的前缀拼接起来作为不同的predicate,比如“饰演_@value”、“饰演_inWork”当成两个不同的predicate分别抽取。
以下是tagging strategy的图示:

代码主要体现在主要体现在task_reader文件中:

二、模型
使用的是百度
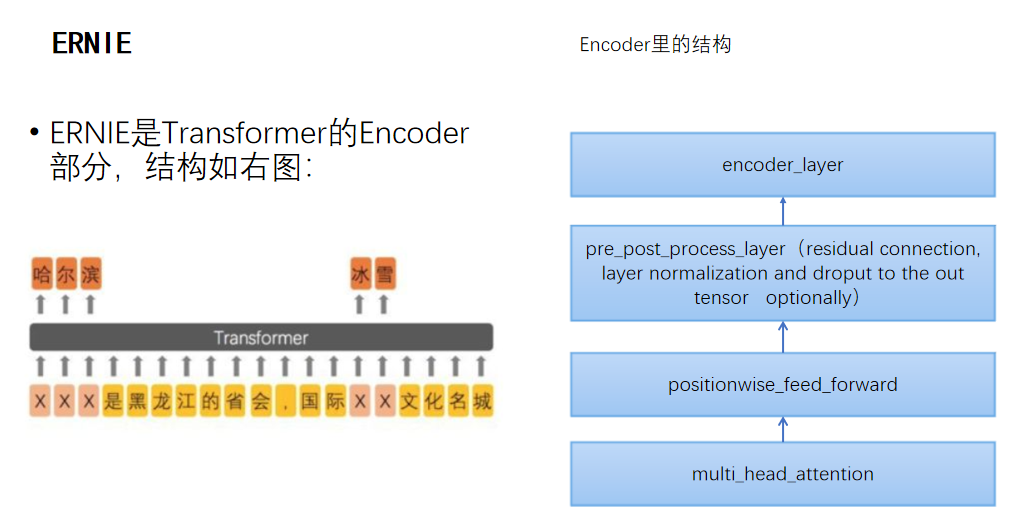
模型的输入是:

三、Finetune过程
微调过程涉及三个文件:
finetune_args(参数)
finetune_launch(过程)
relation_extraction_multi_cls
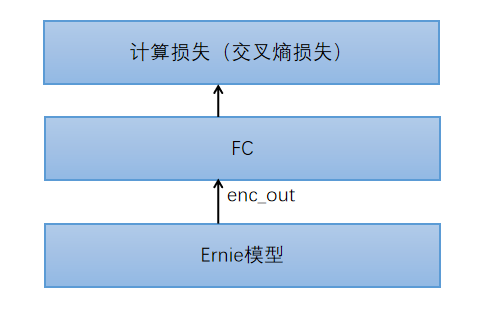
从模型输出的每一个token都是一个768维的向量,然后直接用这个向量接fc层做的分类,得到logits,输出logits并通过sigmoid转换(0,1)之间 最后predict函数将结果转换成最终的spo。format_output:将最后的输出转换为示例样式的输出。
2、跑苏神2020年的代码
一、苏神代码解读
苏神的代码是基于bert4keras
对于复杂的object,他的处理与百度baseline的处理是一样的,即把predicate和object对应的前缀拼接起来作为不同的predicate,比如“饰演_@value”、“饰演_inWork”当成两个不同的predicate分别抽取。
二、模型结果如下:

三、2020年百度baseline和苏神2020baseline对比
相同点:
1、二者处理复杂关系的方法是一样的
不同点: 2、百度的baseline的预训练模型用的是ERNIE;苏神用的是bert4kears
结果对比:
百度epoch=1的结果是:FI值:0.646
苏神epoch=20的结果是:F1值:0.68