2019关系抽取baseline解读 - dylhhh/2020-LIC-RE- GitHub Wiki
2019 baseline解读
Baseline主要有两个模型构成:一个P模型,一个SPO模型。其中P模型是一个使用Bi-LSTM +max-pooling 的多分类模型,目的是将给定的句子进行关系分类。而SPO模型,是将已经分类的句子,通过BIEO的标注方式进行打标签,并识别出关系中的“subject”和“object”
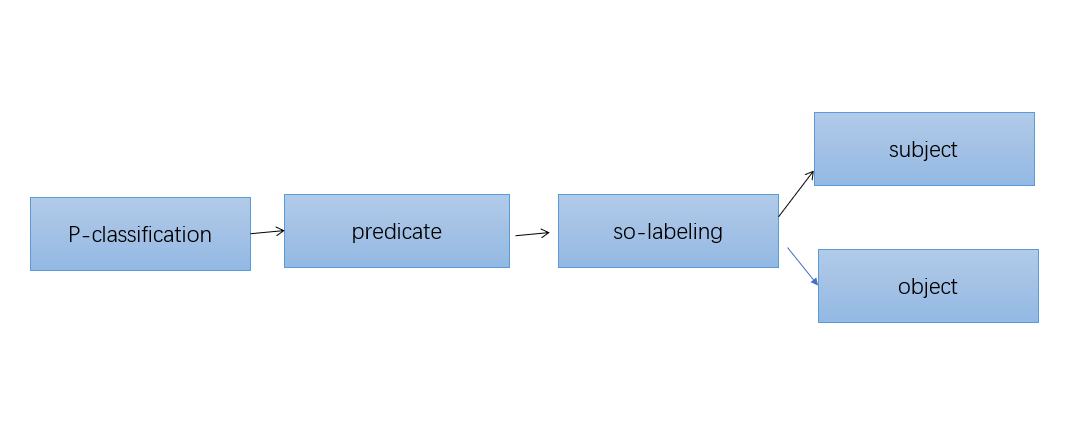
整个模型架构如下:
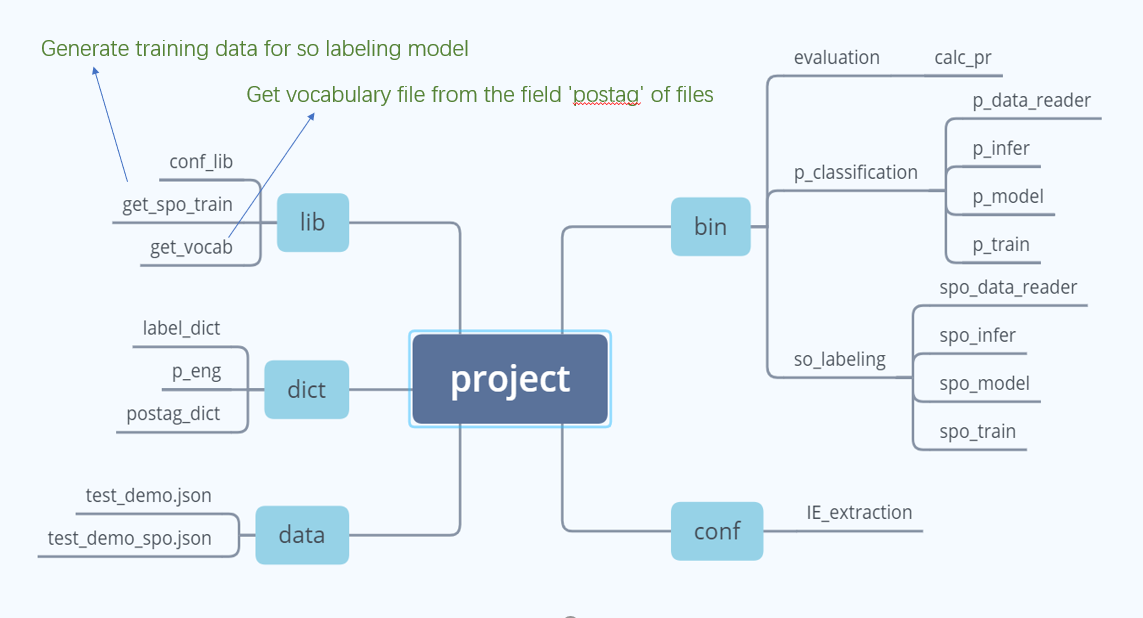
项目提供了三个dict:Label_dict,p_dict, postag_dict ,供比赛使用:

其中,label_dict是BIEO的标注方式,p_dict是每种关系对应的编码,postag_dict是词性标注
其中P模型的结构和输入、输出如下:
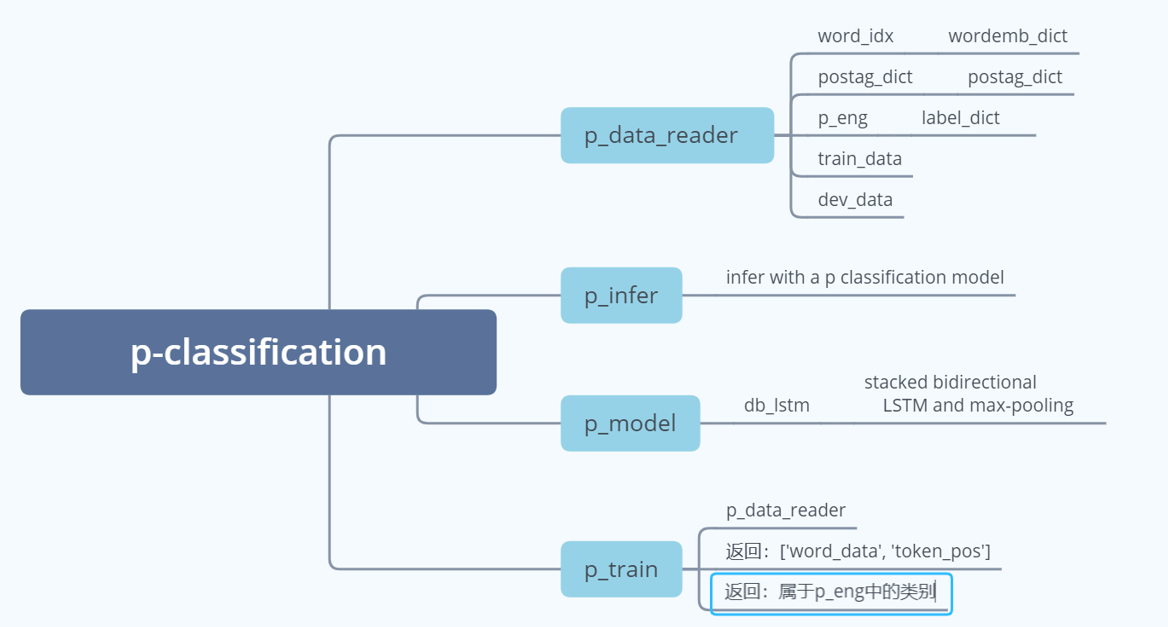
P模型的输入是:word_idx,postag_dict,label_dict(p_eng), train_data,dev_data。
输出主要为:['word_data', 'token_pos']和这个句子属于的关系类别。
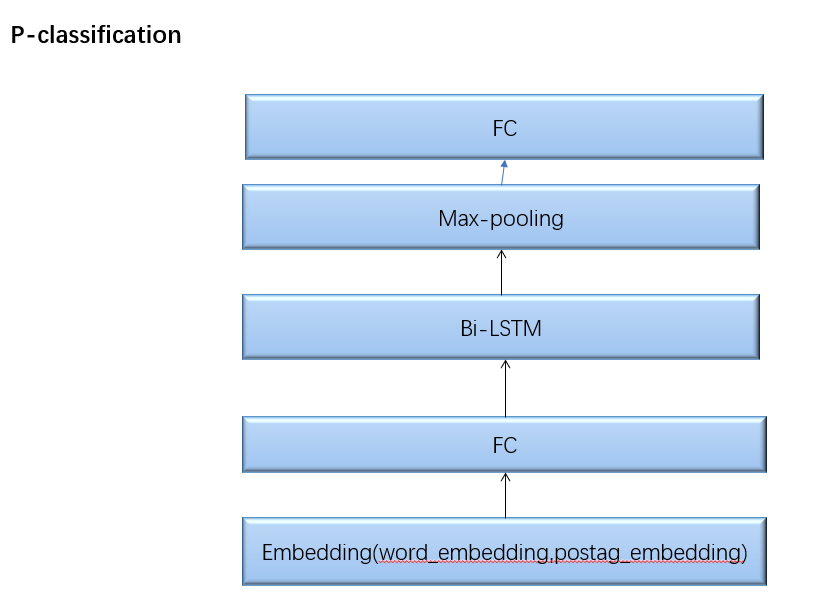
P模型结构如下:
SPO模型如下:
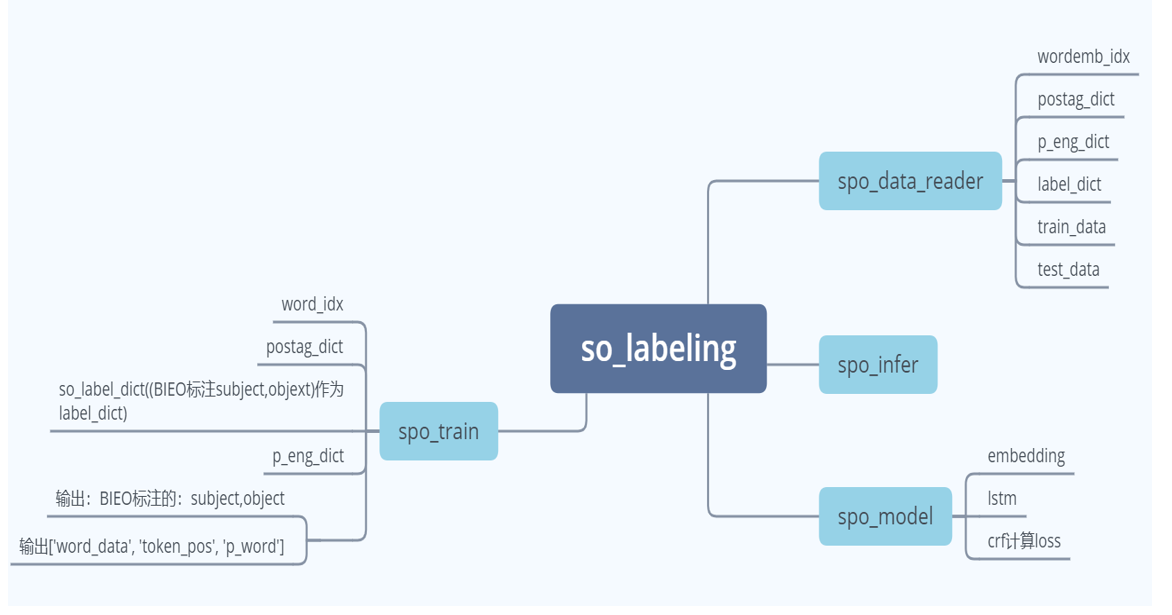
它的输入是:word_idx,postag_dict(词性标注对应的字典),label_dict(用BIEO标注的subject和object,在这个模型中也称为so_label),p_eng_dict,train_data,test_data.
输出的是:['word_data', 'token_pos', 'p_word'],和输出的subject和object。
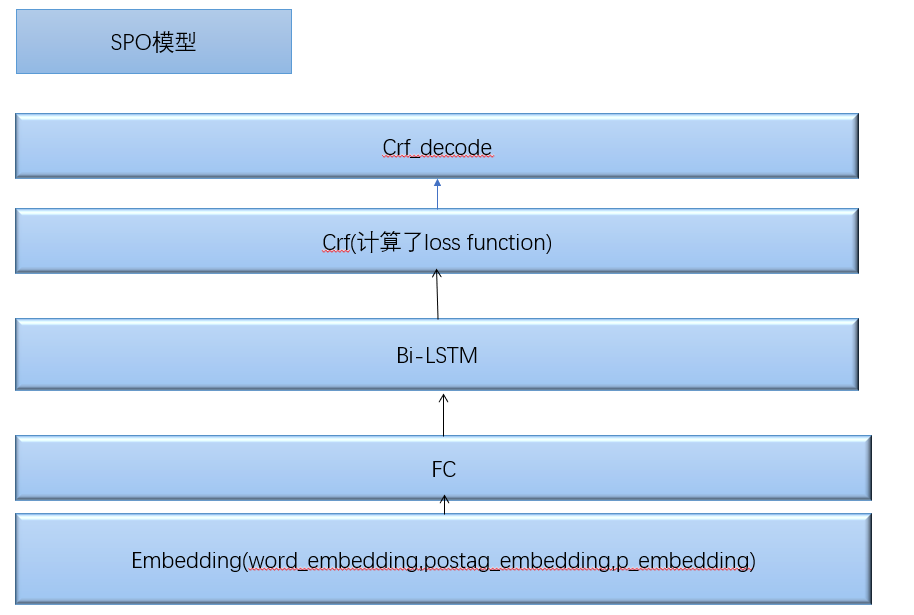
SPO的模型构架如下:
模型的评价方法:
首先(S,P,O)三者都对应相等,才算一个正例。通过计算precision和recall,进而计算F1值。

其中correct_sum的计算方法如下:

当得到的SPO是golden_spo_set(真实的SPO)、alias_dict(别名),loc_dict(location entities of various granularity)。correct_sum加一。recall_correct_sum计算方法同理。