Classification training v2 - dnum-mi/basegun-ml GitHub Wiki
After analysing the previous classification model, 4 pain points have been identified:
To address these pain points, several strategies have been considered, prioritizing quick wins with positive impact. Let’s delve into the main approaches:
The first step involves transitioning from an EfficientNet architecture to YOLOv8. YOLOv8 offers significantly faster inference times. To isolate the impact of the model change, we used the same dataset and data augmentation parameters.

The results showed that using YOLOv8 for classification reduces classification errors by fourfold and significantly improves inference time. This new model will serve as our baseline for further enhancements.
To mitigate the dependency on image rotation, we introduced data augmentation techniques. Specifically, we applied the following geometric transformations:
In order to assess the impact of these transformations, the test dataset has been modified using the same transformations.
On this new dataset, the previous YOLOv8 model goes from 93.5% precision to 91% precision.
Let's have a look to the impact after the training with the new data augmentation.

This new data augmentation allow the model to be more precise and less rotation dependant
Some experimentation has been fulfilled in order to determined if new typologies will give better performance to the model:
The conclusion were the following ones:
As a result, we decided to retain the existing typologies
YOLOv8 offers various model sizes, from nano (our current choice) to XL. Larger models generally yield better performance but come with longer inference times. The YOLOv8 nano offers good performance and is quite fast (~30ms on an isoprod environment), therefore we decided to test the YOLOv8 small which is the next size as the inference time was below the threshold defined.
Here is the comparison.
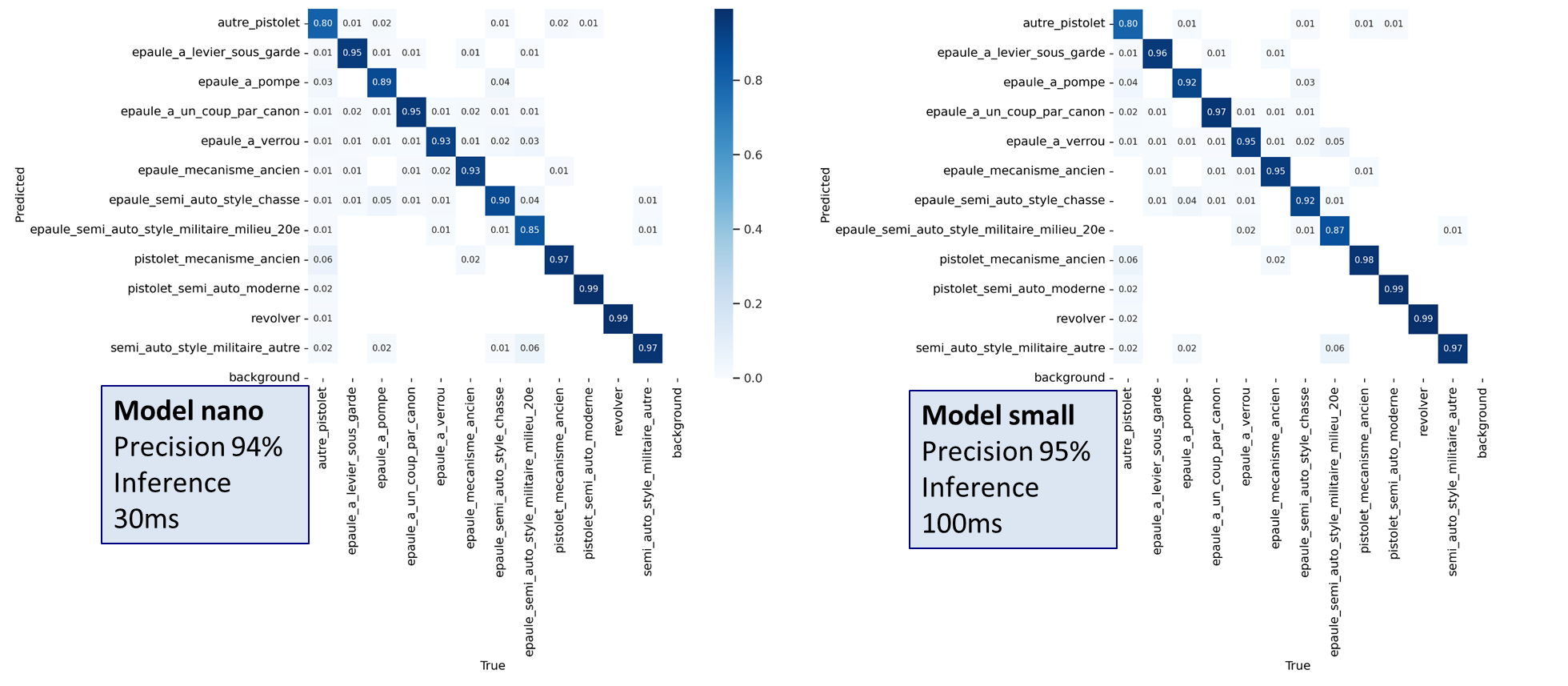
While the precision gain was not substantial, we opted to use the small model for now. However, we’ve kept the nano model as a backup in case new constraints arise.