Alarm gun research - dnum-mi/basegun-ml GitHub Wiki
As previously explained, there are two ways to determine if a gun is an alarm gun
- If the gun is one of the 20 models defined as an alarm by French legislation.
- If the gun has the PTB marking.

Therefore, there will be two different algorithm because the first method uses alphanumeric caracters and the latest consist in detecting graphic marking.
The model and brand of a gun are usually written on the weapon. Alarm guns are defined by a list of models according to French legislation. Therefore, the basic idea is to read the markings and engravings on the gun and compare them to the list of alarm gun models.
This method is quite simple but has some drawbacks. The markings may not be very clear, there might be reading errors for some characters, and it may require a close-up image of the markings.
This method requires Optical Character Recognition (OCR) algorithms. There are different types of algorithms:
- The text detection algorithm, which detects zones with text in an image.
- The text recognition algorithm, which recognizes the characters in the text zone.

For some use cases, such as document recognition, only the latter algorithm is necessary because the entire image contains text. However, in our use case, we need both.
Different OCR models were tested and compared to select the most suitable one for our use case.
| Model | Description | Task | Ease of use | GitHub stars |
|---|---|---|---|---|
| Tesseract | Tesseract is one of the most used OCR packages. Initially developed by HP and Google, it is now open-source. | OCR | Easy to use | 57.8k |
| EasyOCR | Easy OCR is an open-source package that allows text detection and recognition in real scenes, available in more than 80 languages. | Text detection + OCR | Easy to use | 21.8k |
| PaddleOCR | PaddleOCR is a very complete text recognition package with very good performance in many languages. | Text detection + OCR | Moderate | 38.2k |
| EAST | EAST is a fast and robust text detection model for natural scenes. | Text detection | - | - |
| DocTR | DocTR is an open-source package specialized in document text recognition. | Text detection + OCR | Easy to use | 3k |
These models were evaluated on a small dataset using the Character Error Rate (CER) metric. The results showed that PaddleOCR was superior in both text detection and recognition, and it was also faster. Therefore, we chose this model for our subsequent work.
As previously explained, image quality is crucial for accurately reading text. There are different methods to ensure good image quality before applying OCR algorithms.
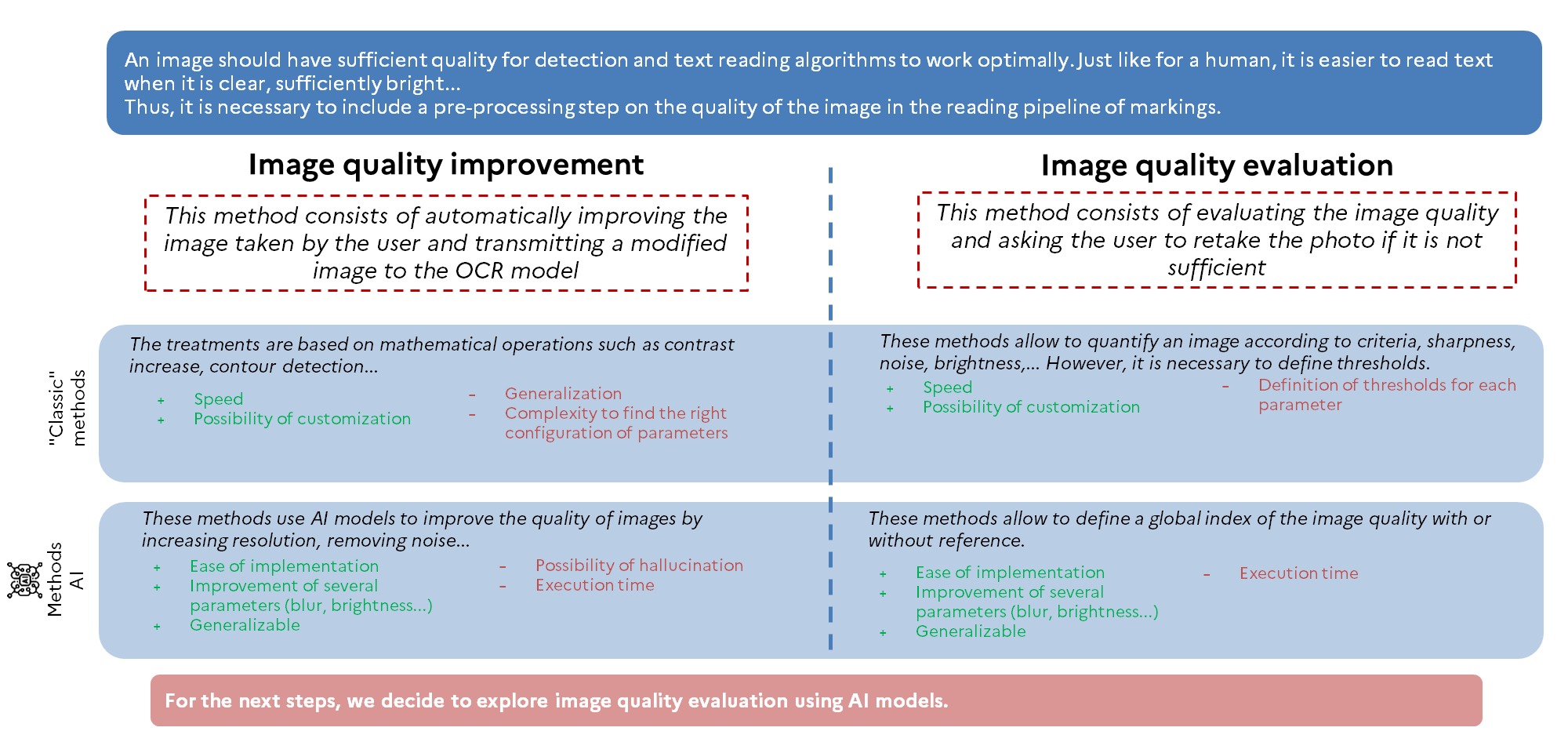
The methods of Image Quality Analysis (IQA) are mainly divided into two categories:
- Reference-based IQA: This method requires a reference image to measure the quality of the target image. It is particularly used to evaluate the impact of compression on image quality.
- Reference-free or blind IQA:** These methods only require the target image to measure its quality.
This is the approach we will explore, we tested 22 algorithms using the pyiqa library. Here are some examples:
- Brisque: One of the most widely used blind IQA methods. It provides a global quality score for the image, with a single threshold for arbitration. The score ranges from 0 (very good quality) to 100 (poor quality).
- CLIP-IQA: This method is based on a similarity calculation between the target image’s passage through the CLIP model and prompts such as “good photo” or “bad photo.” It can provide a global metric for the photo or more precise metrics for brightness, noise, etc. It also works for more subjective criteria like “scary” or “peaceful.”
- CNNIQA: This method use a classic CNN network to determine a quality score for the image that allow it to be faster than the latter techniques.
After experimenting with a small dataset, we chose to use CNNIQA due to its performance and inference speed.
Work in progress