Sprint 4. Resultados Implementación - df-garcia/Chiper_202010_Grupo_Canem GitHub Wiki
1. Selección de tecnologías y frameworks
Para el desarrollo del Sprint 4, se usaron varias tecnologías dentro de las que se comprende: tres bases de datos (SQL) Postgres y una (no SQL) MongoDB. Se eligieron esta cantidad de base de datos y de estos tipos con base a los microservicios implementados (implementando patrones como Database per service y Shared database). Adicional a esto, este tipo de bases de datos permiten un mejor y mayor manejo de datos basados en los modelos que se construyeron con Django/Python; Python que fue el lenguaje principal de desarrollo de nuestro proyecto, permitió junto al framework Django un manejo más fácil de las consultas en la base de datos, aprovechar el uso del ORM provisto por el framework y una nueva comprensión del desarrollo basado en MVT (model, view, template). De igual manera, para dos de los microservicios implementados (servicio de Catálogo y de Tienda) se decidió ahondar y trabajar con Java como lenguaje de programación base, utilizando Spring Boot como framework, esto para manejar una nueva herramienta de programación dentro del proyecto. Por otro lado, se utilizó el API de Auth0 integrado con el framework Django para cubrir y garantizar la autenticación y autorización de los usuarios dentro de la aplicación, esta API permitió separar de la base de datos principal los datos sobre los usuarios (email, contraseñas, entre otros) y así garantizar una mejor distribución en el almacenamiento con base al tipo de datos. Continuando con la presentación de las tecnologías usadas, cabe mencionar que se implementó un API Gateway (reemplazando el Service Registry existente dentro de la arquitectura) que funciona como "enrutador" desde un punto de entrada común (solicitudes de clientes por parte desde una UI) y redirige al grupo de microservicios propuestos: Manejador de Catálogo, manejador de Tienda, manejador de Pedidos y manejador de Analítica.
Finalmente, no sobra nombrar los editores que se utilizaron para escribir el código del proyecto, estos fueron: Visual Studio Code, PyCharm y Eclipse.
Estas fueron las principales tecnologías y frameworks ocupados durante el desarrollo del Sprint 4.
2. Documentación de análisis y resultados
ASR 1:
Para este ASR, se realizaron pruebas utilizando el scanner de SonarQube. De esta manera, se puede verificar si hubo cambios en cuanto a las métricas obtenidas antes y después de realizar la implementación de los microservicios.
A continuación, se muestran las diferentes métricas obtenidas al analizar el proyecto antes de realizar la implementación de los microservicios:
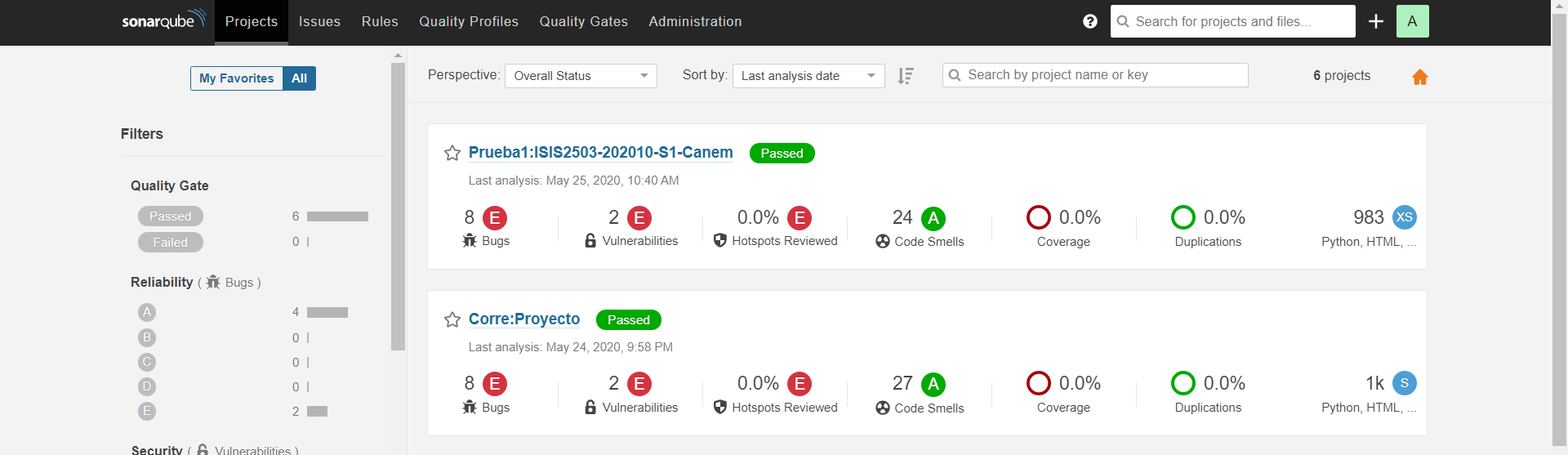
Se realizaron dos pruebas, siendo la última la que tiene el nombre Prueba1:ISIS2503-202010-S1-Canem. Como se observa, hay 8 bugs, 2 vulnerabilidades, 24 code smells y un porcentaje de 0% en cuanto a duplicaciones de código. Se muestra a continuación una observación más detallada de cada métrica:
Vista general de todas las métricas - Prueba 1:
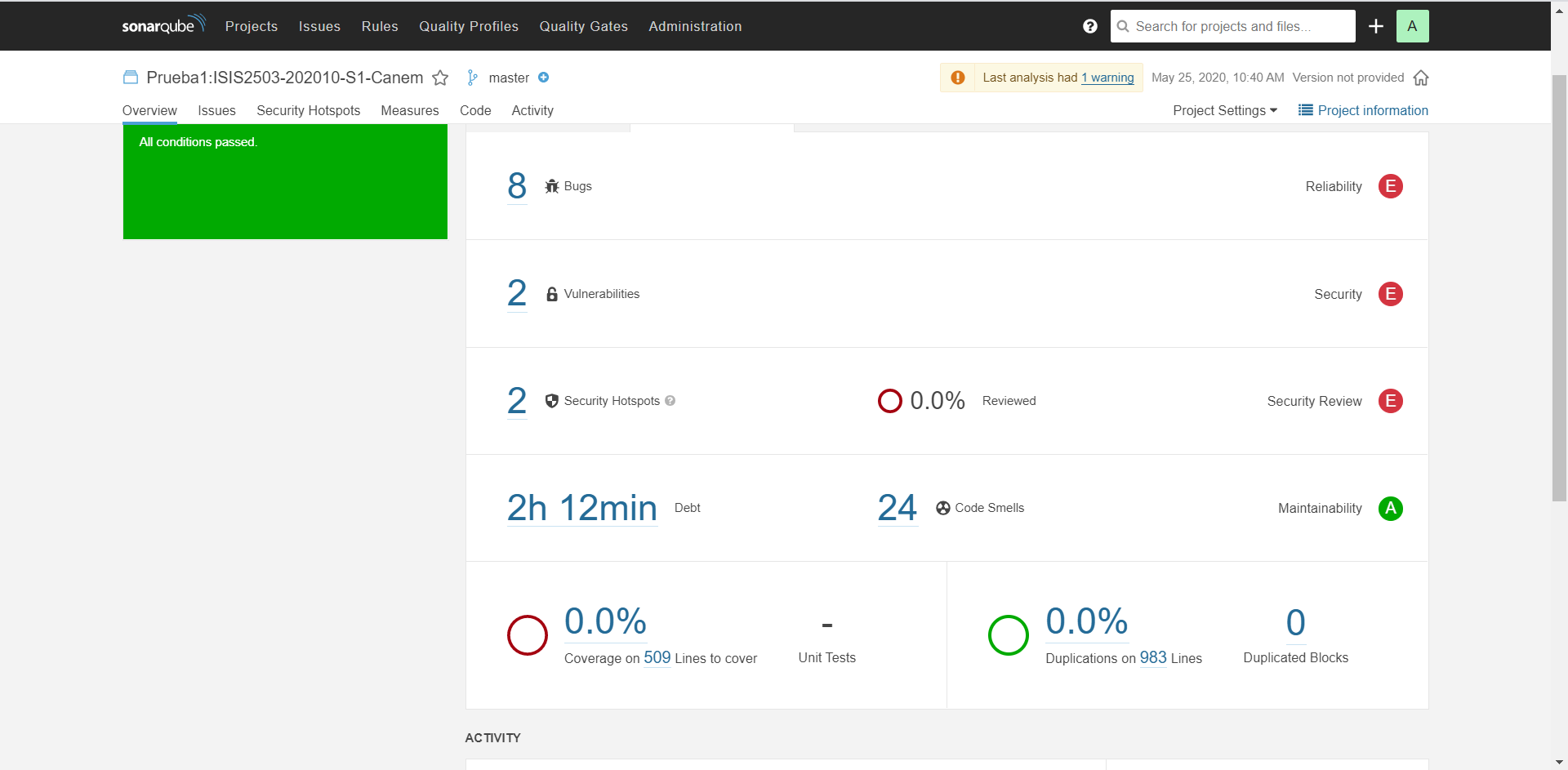 Bugs - Prueba 1:
Bugs - Prueba 1:
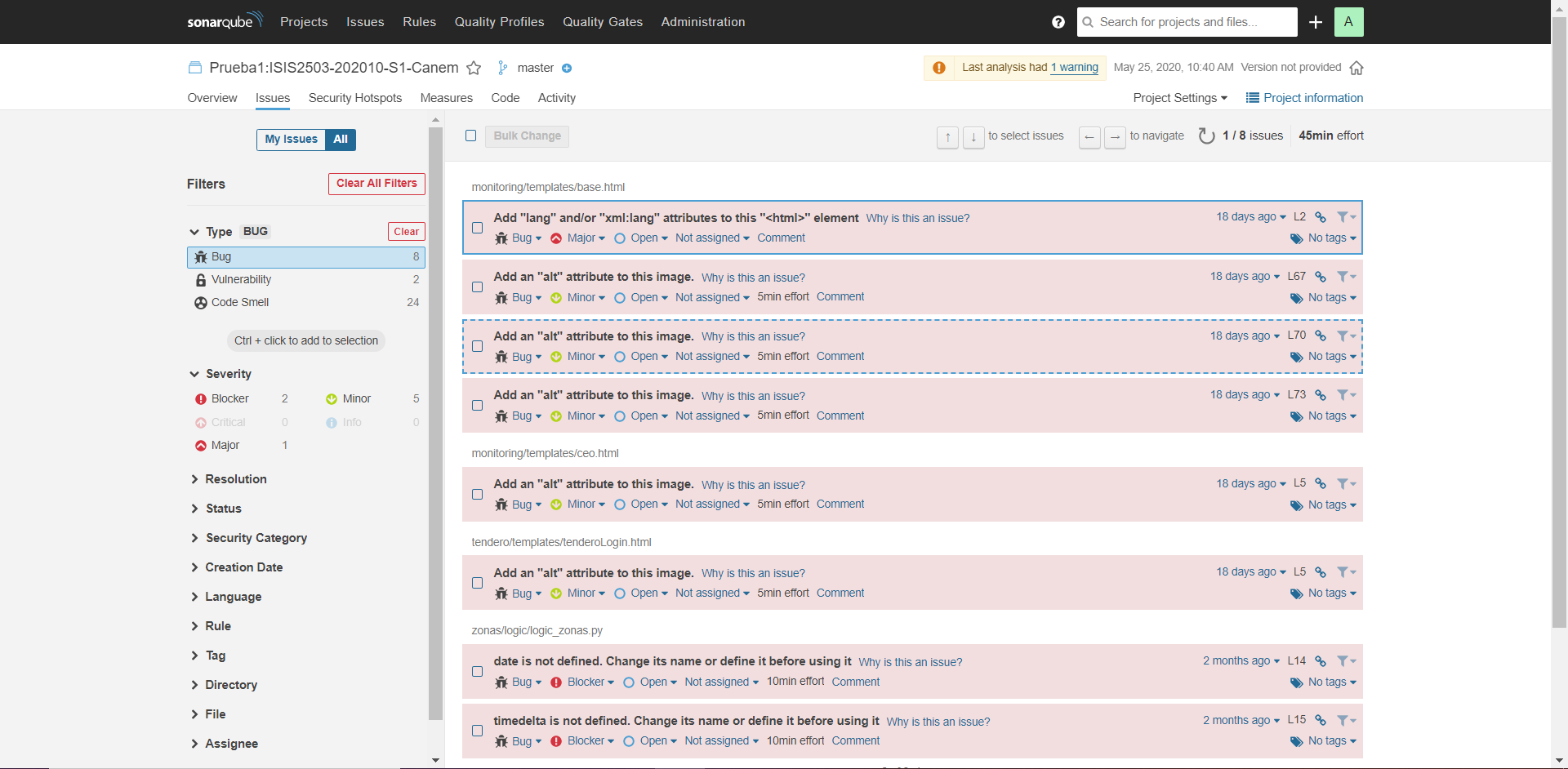 Vulnerabilidades - Prueba 1:
Vulnerabilidades - Prueba 1:
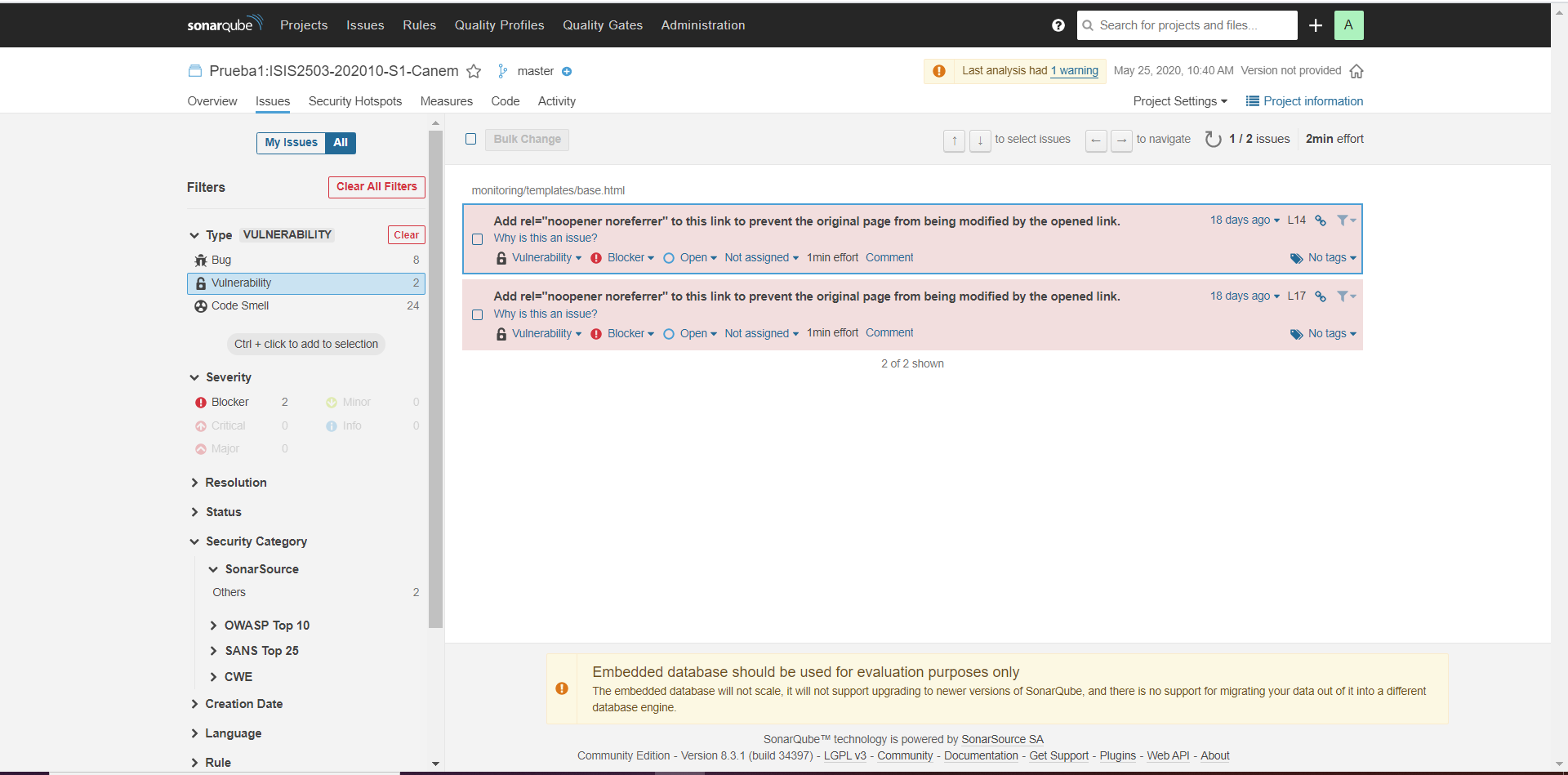 Puntos de Seguridad - Prueba 1:
Puntos de Seguridad - Prueba 1:
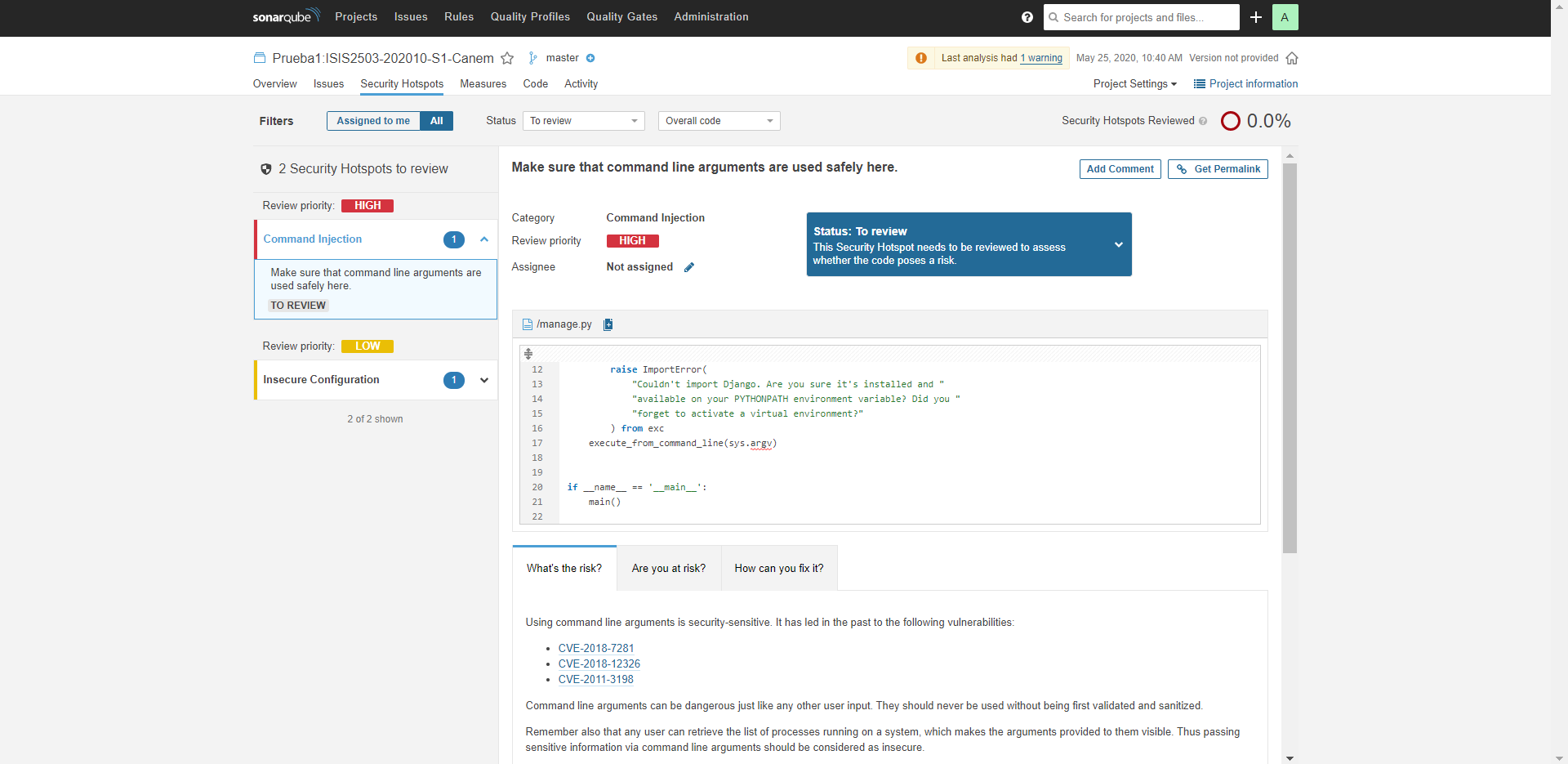 Code Smells - Prueba 1:
Code Smells - Prueba 1:
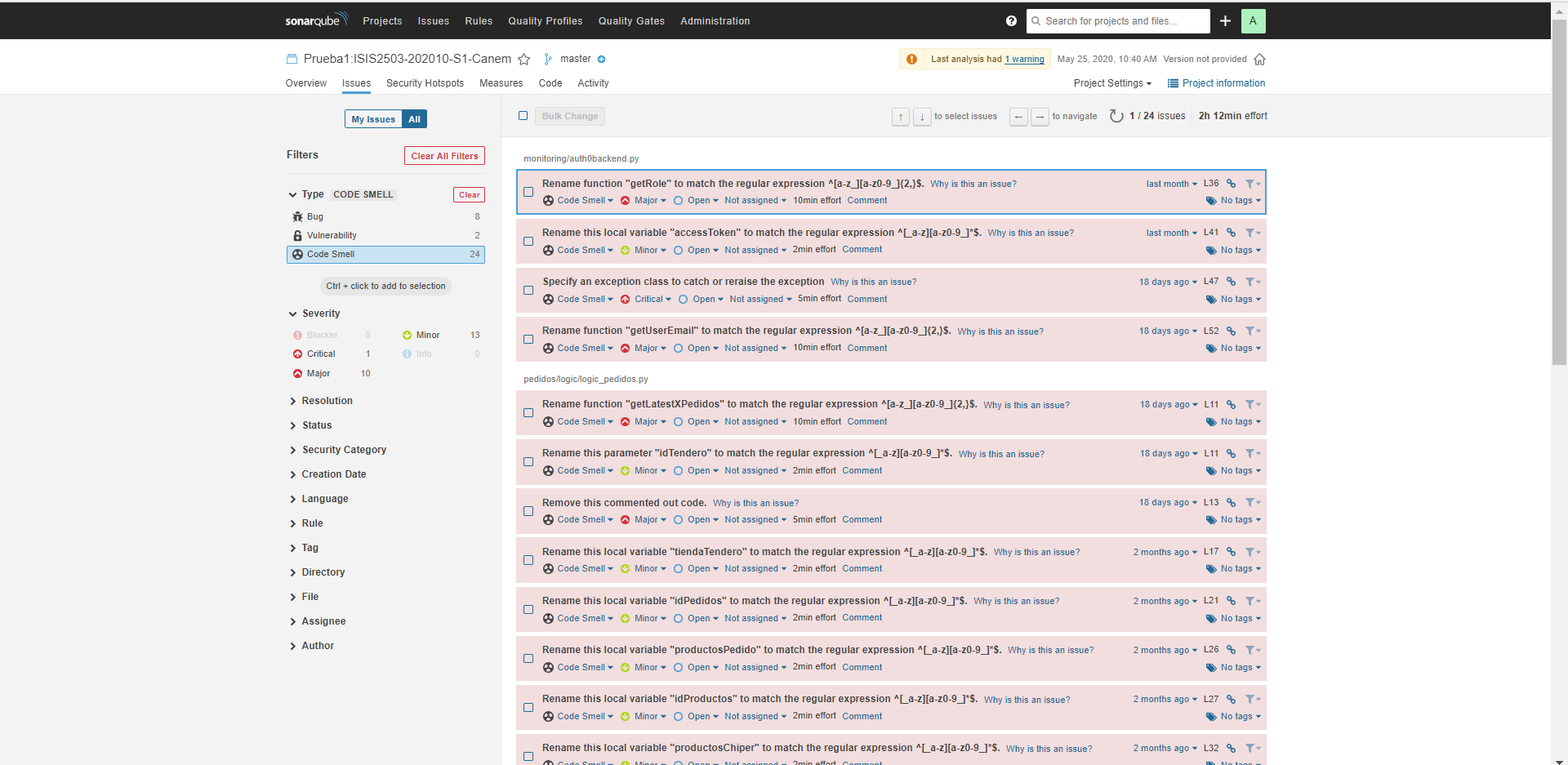 Duplicaciones de Código - Prueba 1:
Duplicaciones de Código - Prueba 1:
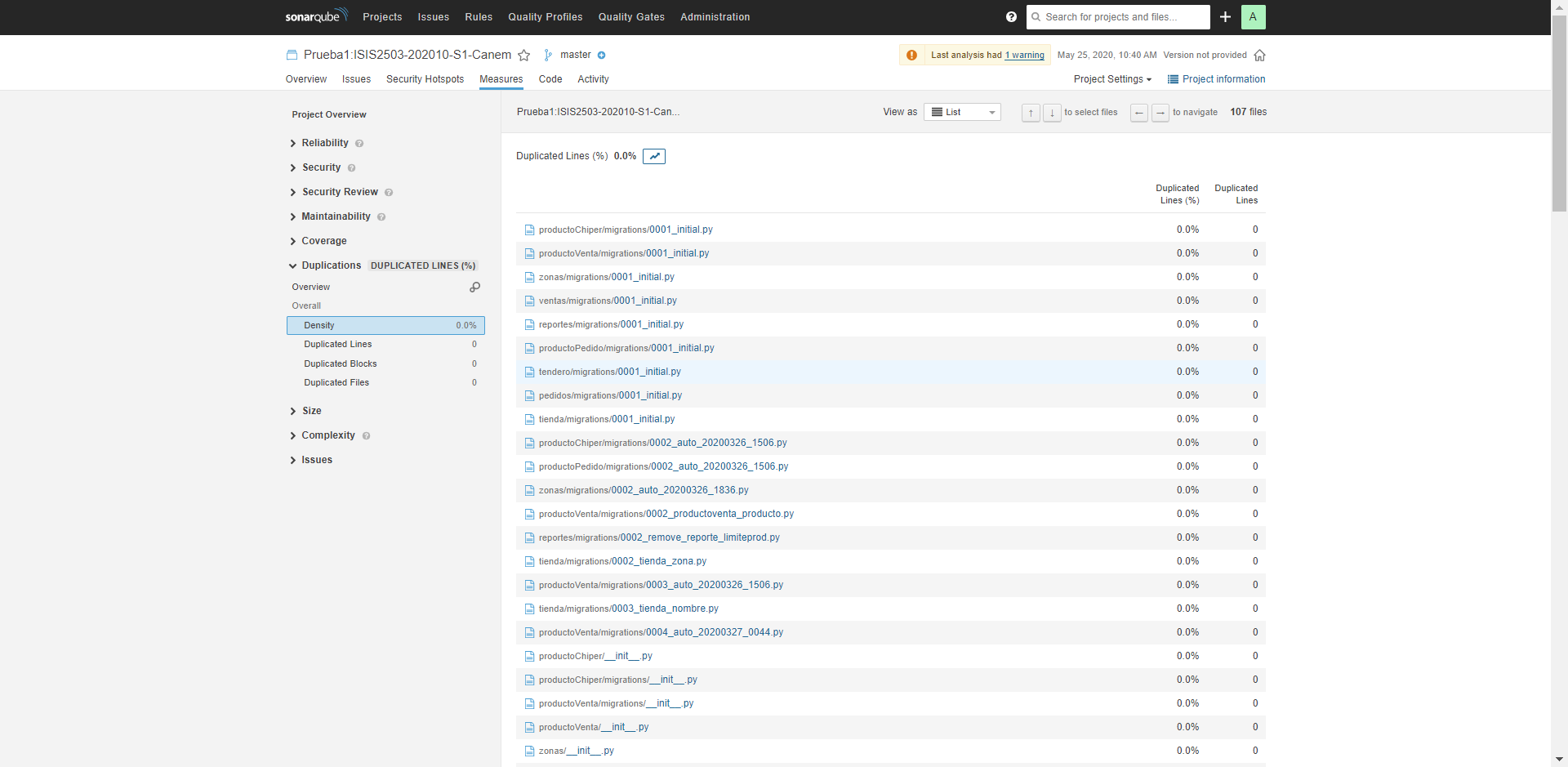 Como se observa, esta prueba pasó todas las condiciones establecidas por SonarQube. A pesar de que hay ciertas cosas por mejorar en el código, el porcentaje de duplicaciones está por debajo del 5%, que es lo que nos interesa para el cumplimiento del ASR establecido en el Sprint.
Como se observa, esta prueba pasó todas las condiciones establecidas por SonarQube. A pesar de que hay ciertas cosas por mejorar en el código, el porcentaje de duplicaciones está por debajo del 5%, que es lo que nos interesa para el cumplimiento del ASR establecido en el Sprint.
Para la segunda prueba (realizada después de haber implementado los microservicios) se obtuvo un resultado óptimo, en el que se pasaron todas las condiciones de SonarQube.
A continuación, se muestran las diferentes métricas obtenidas al analizar el proyecto después de realizar la implementación de los microservicios:

La prueba realizada tiene el nombre Prueba2:ISIS2503-202010-S1-Canem. Como se observa, hay 8 bugs, 2 vulnerabilidades, 31 code smells y un porcentaje de 0% en cuanto a duplicaciones de código. Se muestra a continuación una observación más detallada de cada métrica:
Vista general de todas las métricas - Prueba 2:
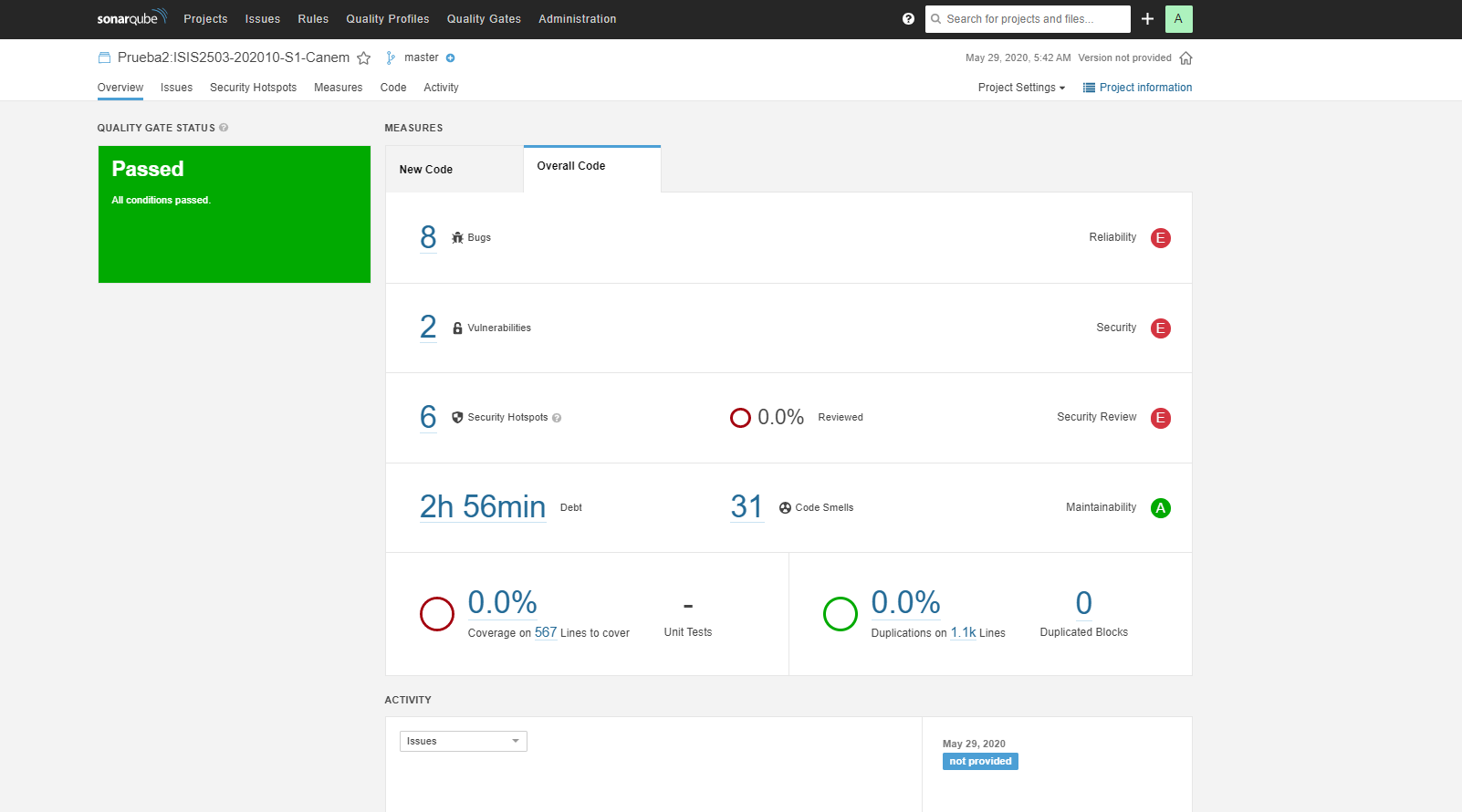 Bugs - Prueba 2:
Bugs - Prueba 2:
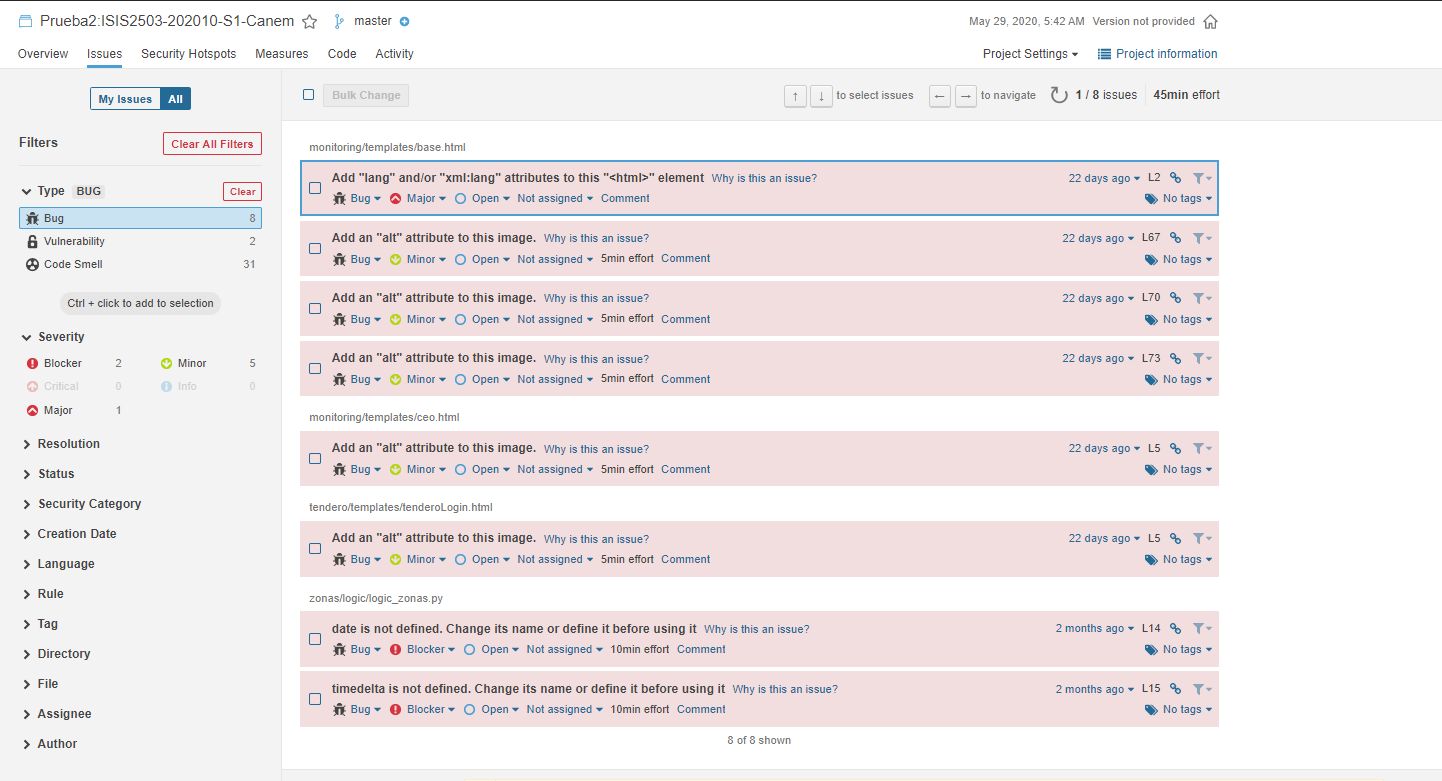 Vulnerabilidades - Prueba 2:
Vulnerabilidades - Prueba 2:
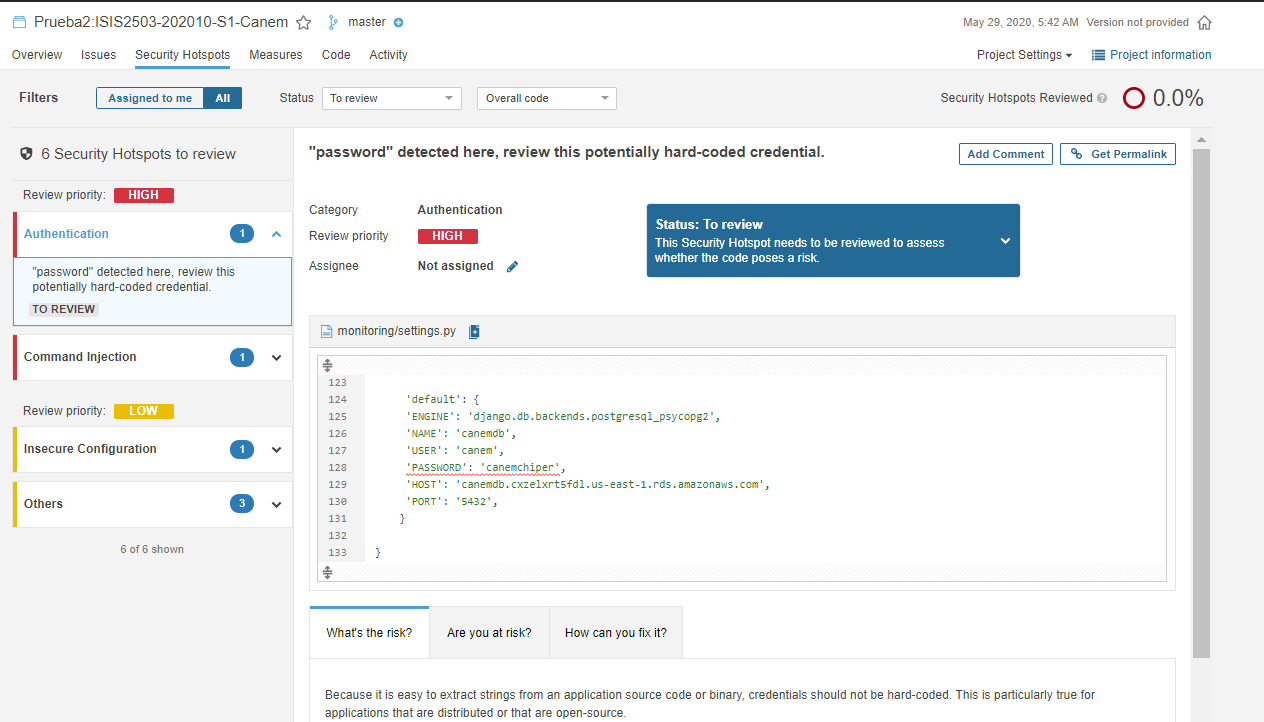
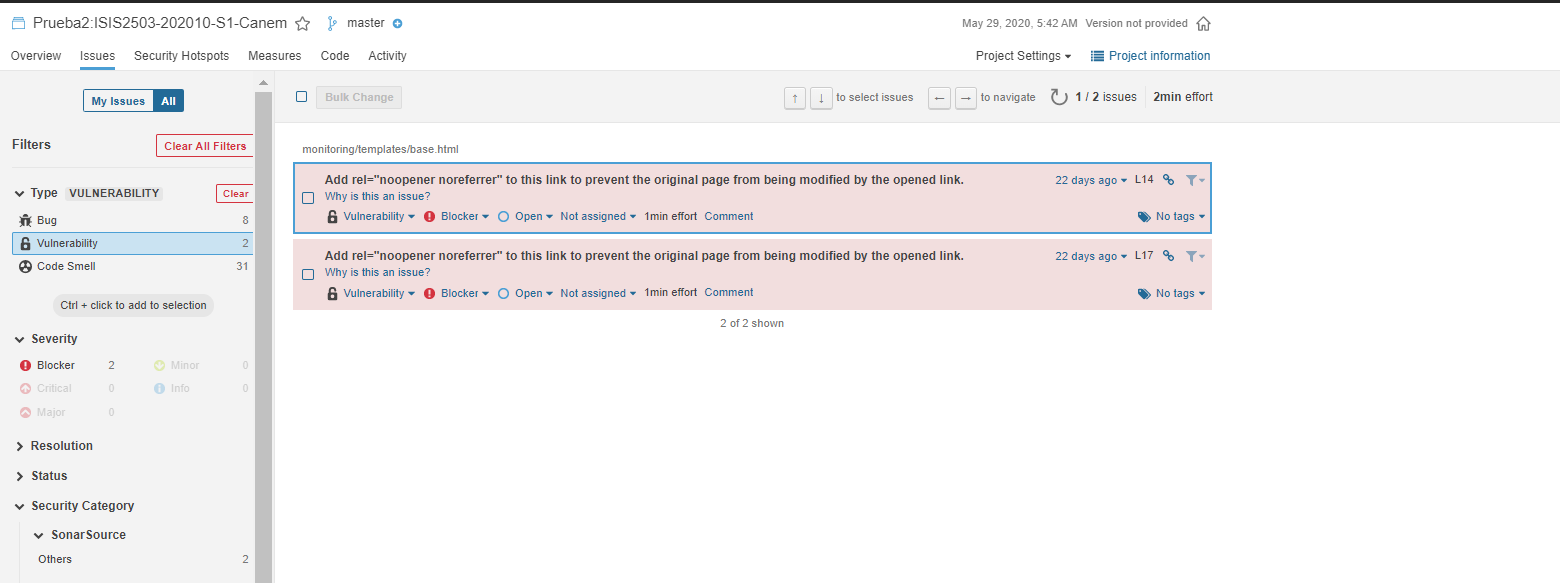 Puntos de Seguridad - Prueba 2:
Puntos de Seguridad - Prueba 2:
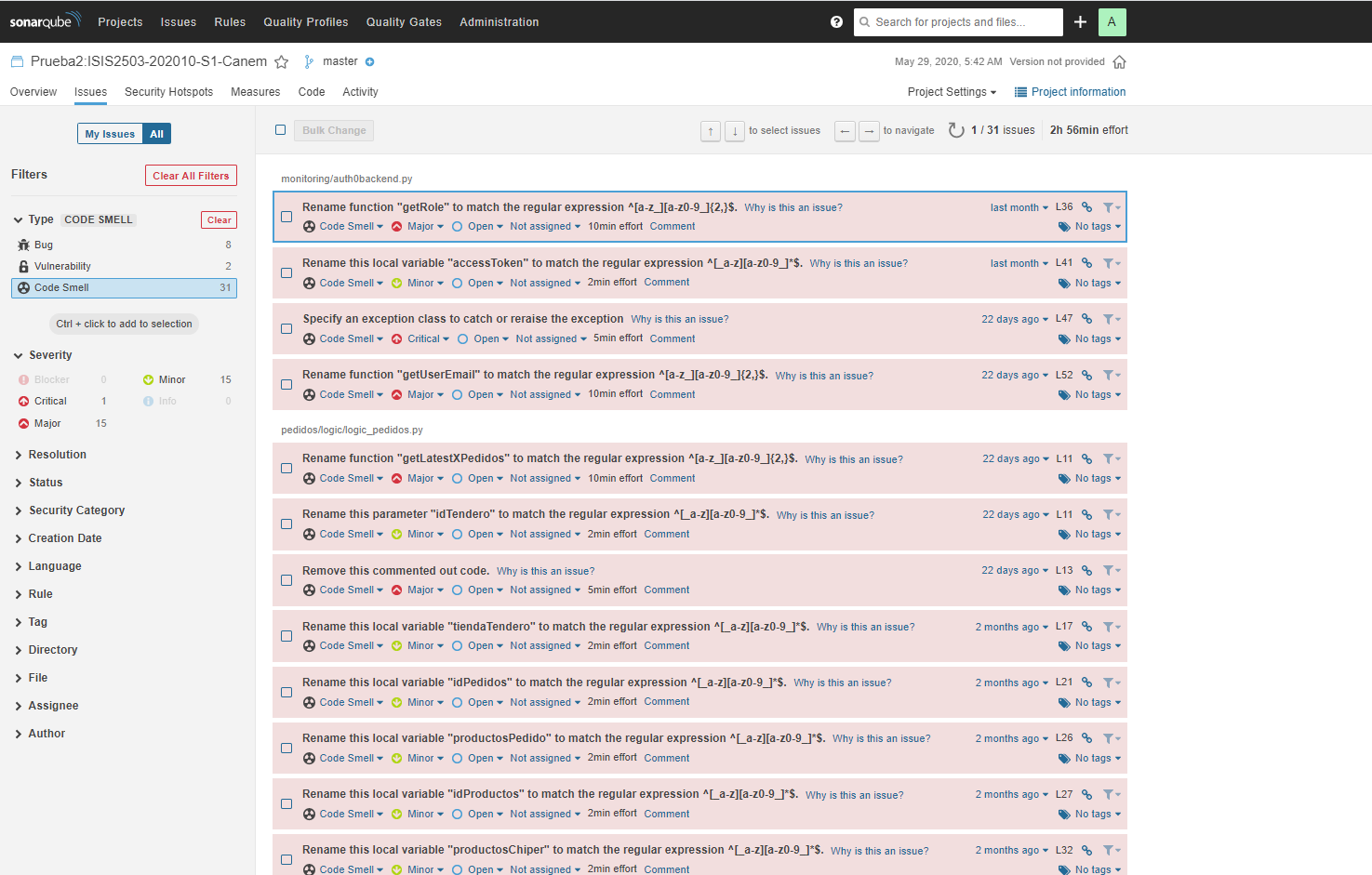
 Code Smells - Prueba 2:
Code Smells - Prueba 2:
 Duplicaciones de Código - Prueba 2:
Duplicaciones de Código - Prueba 2:
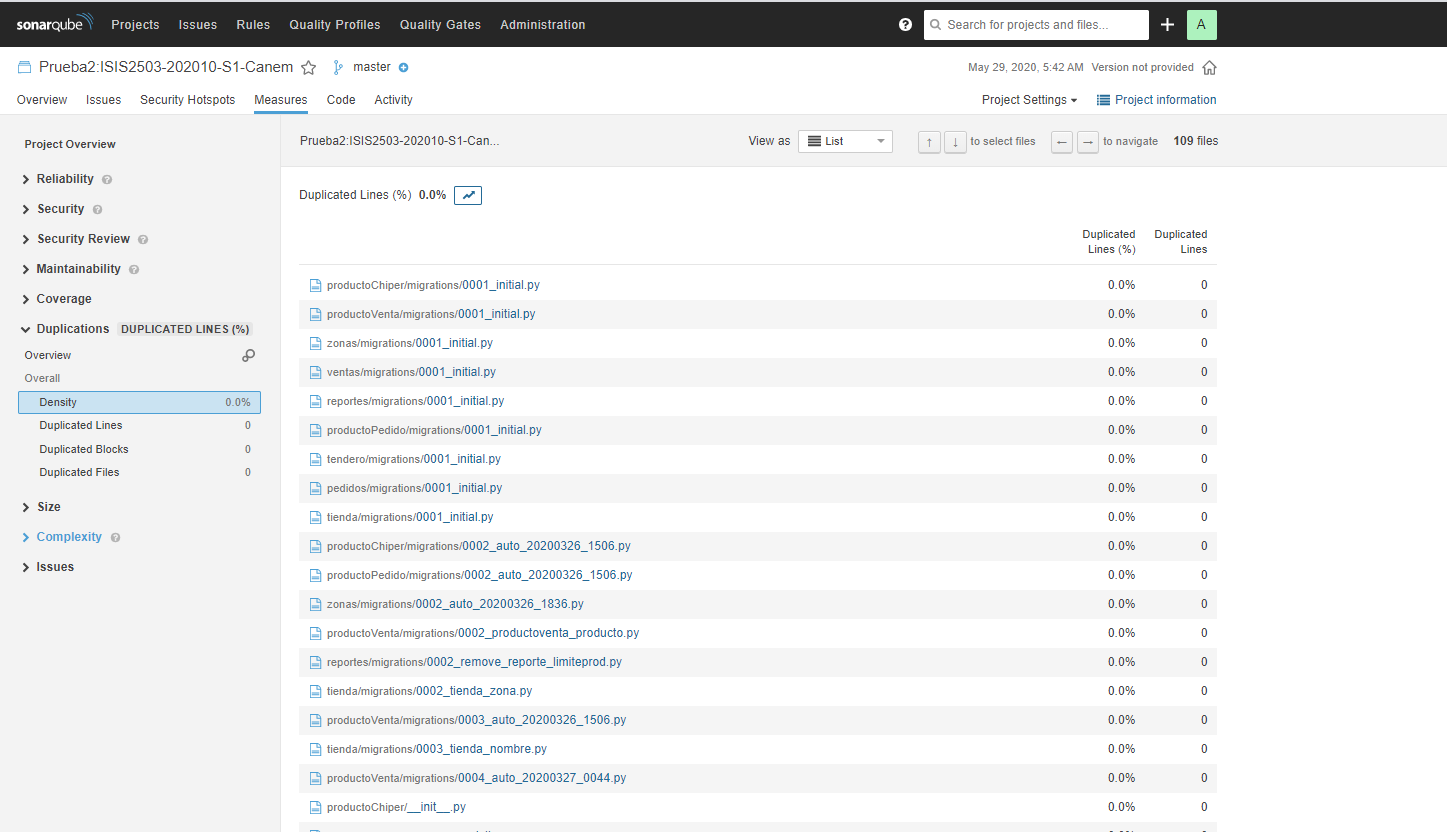 Como se observa, esta prueba también pasó todas las condiciones establecidas por SonarQube. Sigue habiendo ciertas cosas por mejorar en el código, pero el porcentaje de duplicaciones está por debajo del 5%, que es lo que nos interesa para el cumplimiento del ASR establecido en el Sprint.
Por tanto, se puede concluir que se cumplió con el ASR, a partir de los resultados obtenidos.
Como se observa, esta prueba también pasó todas las condiciones establecidas por SonarQube. Sigue habiendo ciertas cosas por mejorar en el código, pero el porcentaje de duplicaciones está por debajo del 5%, que es lo que nos interesa para el cumplimiento del ASR establecido en el Sprint.
Por tanto, se puede concluir que se cumplió con el ASR, a partir de los resultados obtenidos.
ASR 2:
Para este ASR se realizaron pruebas de latencia con base a la herramienta de JMeter, esto posibilitó establecer los tiempos que tomaban las peticiones tipo GET para la obtención de los datos peretenecientes a los reportes generados por el manejador de analítica. A continuación, se muestran los resultados obtenidos para diferentes escenarios:
| #Threads | Ramp up (s) | Latencia promedio (ms) | Rendimiento promedio (pets/s) | %Error |
|---|---|---|---|---|
| 100 | 1 | 6428 | 11,9 | 0% |
| 100 | 5 | 2548 | 12,1 | 0% |
| 100 | 10 | 1079 | 4,2 | 0% |
| 80 | 5 | 824 | 12,7 | 0% |
| 50 | 4 | 2830 | 2,8 | 0% |
| 60 | 2 | 3182 | 3,5 | 0% |
| 65 | 1 | 3633 | 12,2 | 0% |
Evidencia de las pruebas:
Escenario 1: 
Escenario 2: 
Escenario 3: 
Escenario 4: 
Escenario 5: 
Escenario 6: 
Escenario 7: 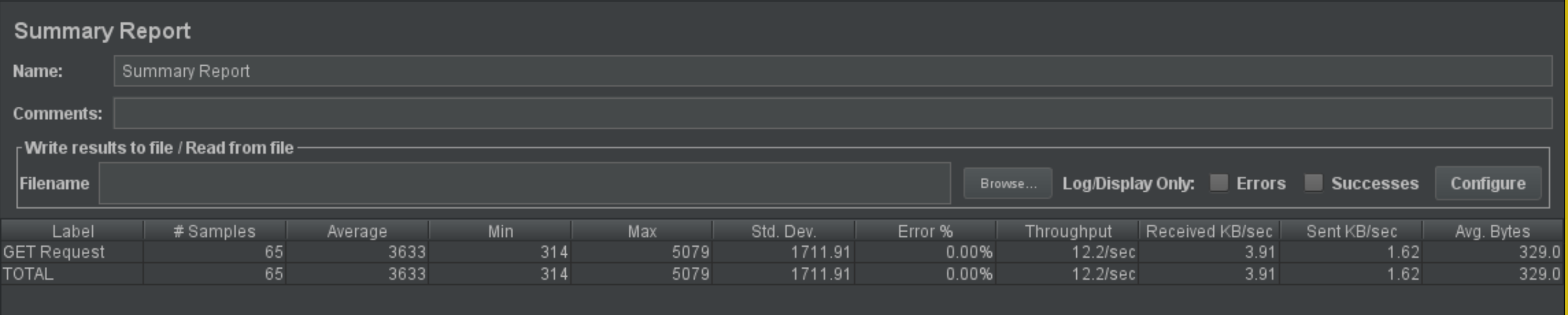
Conclusión: Después de hacer un análisis exhaustivo a los resultados obtenidos podemos observar que el punto de inflexión para la arquitectura propuesta son aproximadamente 60 threads con un ramp-up de 2 segundos. A pesar de esto, se puede evidenciar un comportamiento aceptable para la mayoría de los casos, sin descartar la posibilidad de encontrar otros escenarios óptimos para la arquitectura. Lo anterior, teniendo en cuenta que JMeter presenta variabilidad significativa con base a la velocidad de la red. Finalmente, se comprueba que existe un buen comportamiento general del sistema para el cambio a una base de datos documental (implementada en MongoDB), utilizando patrones de diseño detallado.
3. Modificaciones realizadas en los modelos de arquitectura
1. Microservicios
Para este Sprint se ahondó mucho más en el manejo de microservicios. Esto se puede ver el hecho de que una considerable cantidad de los ambientes desplegados contengan solo una aplicación con responsabilidades específicas. Las razones que motivaron esta elección fueron la facilidad en el desarrollo, y el favorecimiento de atributos como la cohesión, la mantenibilidad, el bajo acoplamiento y la escalabilidad. Además, al ser implementados se disminuye la complejidad del despliegue y la propagación de errores.
2. Database per Service
Para contribuir al bajo acoplamiento y a los requerimientos de latencia se decidió implementar una base de datos por cada microservicio. Esto es beneficioso ya que los distintos microservicios no interfieren directamente con los datos que tienen almacenados los demás y además se adquiere cierta libertad para implementar el esquema de almacenamiento que mejor se ajuste a las necesidades del servicio.
3. Descomposición por dominios y subdominios
Cada microservicio responde a un subdominio de entre los que se plantearon y es importante que sea de esta manera ya que se beneficia la autonomía de cada microservicio y el proceso de construcción de software se ve favorecido al permitir una mejor distribución del trabajo.
4. SAGAS
Se implementó un broker para mantener la concordancia entre la base de datos de la tienda y la de los pedidos según indica el patrón SAGAS. A través de este broker se da un esquema de transaccionalidad en a cual se garantiza que distintas bases de datos hagan sus respectivas actualizaciones. Se tuvo que implementar este patrón ya que se uso "database per service" pero a la vez hay bases de datos que manejan información en común.
5. Instance per Host
El despliegue de la arquitectura se dió utilizando un servidor por cada una de los servicios implementados. Esta táctica de favorece la velocidad de despliegue y reduce la contienda por recursos entre los diferentes servicios. Adicionalmente, se tienen instancias de ejecución aisladas y permite el desarrollo multiplataforma.
6. Backend for Frontend
Para el despliegue de la arquitectura planteada, se utilizó el patrón Backend for Frontend, debido a las múltiples opciones que tienen los clientes para conectarse a la aplicación (POS, Web y Móvil). A partir del uso de múltiples API Gateways se permite la interacción de diferentes tipos de usuarios y múltiples protocolos.
4. Repositorios adicionales usados para cubrir los patrones y tácticas planteadas (implementados con otra tecnología)
1. Repositorio del micro servicio de catálogo (implementado en Java con el framework Spring): https://github.com/df-garcia/MicroservicioCatalogo 2. Repositorio del micro servicio de tienda (implementado en Java con el framework Spring): https://github.com/Mario-Hurtado/pruebaSubs