Software Conventions - department-of-veterans-affairs/abd-vro GitHub Wiki
VRO Software Conventions
This page describes software conventions that should guide new development in VRO to help maintain consistency, expedite time to deployment, and evoke a great developer experience.
Terminology
- "domain" = area of functionality to be added to VRO, such as va.gov integration (VRO v1), MAS integration (VRO v2), or Contention Classification (CC)
- "MQ" = message queue, such as RabbitMQ, provides a message bus, enabling communication across all containers
- "container" = a Docker container is used to encapsulate functionality into modular, scalable, stateless components
- VRO's container categories:
- App container: there's a default App container that exposes an API using Java Spring Web and combines Java-based domain-specific API endpoints into a single API
- A domain can expose its API, but some manual updates will be needed to expose the API via the API Gateway
- Workflows container: defines domain-specific workflows using Camel Routes (in Java) or Prefect in Python. Each domain should have its own Workflows container; typically, a single Workflows container is needed per domain regardless of the number of workflows.
- The workflow library should be able to send requests to Service containers using the message queue.
- Service container: holds one or more microservices that implement (in any language) step(s) in a workflow, providing some basic, stateless functionality. Multiple service containers are expected to be used in a multi-step workflow. These services are typically domain-specific, but they can be generalized to be domain-independent and reusable by multiple domains.
- Platform container: offers a domain-independent resource or service, such as containers that run the RabbitMQ, Postgres DB, and Redis Cache services.
- App container: there's a default App container that exposes an API using Java Spring Web and combines Java-based domain-specific API endpoints into a single API
- A container may be composed of several VRO Gradle modules (or subprojects).
- A Gradle module is a folder with a
build.gradlefile. A module is used as a library or for a container (which may import libraries). A container module uses acontainer.*-conventionsGradle plugin (search forid .*container.*-conventionsinbuild.gradlefiles to identify all the container modules).
- A Gradle module is a folder with a
Example of VRO Container Categories:
Folder Structure
Top-level folders are for domain-independent code, except for domain-... folders where domain-specific code resides. VRO software resides in these folders:
app: VRO entrypoint; pulls in domain-specific api-controller modulesconsole: VRO shell console for diagnostics (inspired by Rails Console) - TODO: Is this still used? Remove if not.db-init: initializes and updates the database schemapostgres: defines a customized database containershared: utility and library code shared across domains (Shared libraries)svc-*: domain-independent microservices, typically for integrations (Shared microservices)mocks: mock services for development and testing, typically mocking external APIsdomain-ABC: domain-specific code with subfolders:ABC-api-controller: module that defines domain API endpoints and controllerABC-workflows: defines domain workflows (i.e., Camel Routes)svc-*: domain microservices supporting the workflows
Other top-level folders contain configurations for building and deploying VRO.
Starter Projects
Currently, VRO houses starter projects that can be used as a starting point when building a new application in VRO. These projects can be copy-pasted into the appropriate folder and used to quickly build applications in VRO that already have the relevant code-quality libraries and folder structures in place. Just download the proper project skeleton directory based on language, and paste it in the appropriate location in VRO's abd-vro repository, and then build in the functionality!
The skeleton projects are in VRO's abd-vro-skeleton-projects repo.
Shared libraries
VRO offers utilities and DB classes as shared libraries for use by domain-specific classes.
shared/apifolder: (Java) general API modelsshared/controllerfolder: (Java) Controller utilities, including InputSanitizerAdviceshared/lib-camel-connectorfolder: (Java) Camel utilities, including a Spring Configuration for Camel and CamelEntryshared/persistence-modelfolder: DB utilities, including Java Entities- Python MQ utilities to facilitate interaction with the MQ
These libraries should have minimal dependencies to help avoid dependency conflicts (aka "dependency hell").
Be cautious when updating these files since they can inadvertently affect multiple domains that use the libraries. (Versioning the libraries can help avoid this scenario but adds significant complexity and maintenance overhead.)
Shared microservices
VRO offers integrations with external services (such as Lighthouse API and BIP API) via shared microservices deployed in separate containers (for independent updating, downtime handling, and scalability). These domain-independent shared microservices are in the top-level svc-... folders. Other (non-integration) cross-domain microservices can be added as long as they are domain-independent.
Note that external services can go down, so the domain's workflow should incorporate error handling and retry mechanisms for workflow robustness. Do not rely on RabbitMQ-specific retry mechanisms (RabbitMQ Microservice reliability or any MQ-specific features) in case VRO moves to use some other MQ; instead, use Camel EIPs to do retries as part of the workflow.
Adding a New Domain
To enable capabilities for a new domain in VRO, the partner team will typically implement a Workflows container and several Service containers and add API endpoints by creating an API-Controller module.
- Code for one domain should not reference code in another domain. Keep domains decoupled, including keeping containers for different domains independent of each other. This allows containers for one domain to be restarted without affecting unrelated containers. Once created, the API-Controller module should rarely need to be updated, whereas the Workflows and Service containers are restarted more frequently.
- Add a
domain-...folder at the top level of VRO's codebase. All code for the domain should reside in subfolders under this domain folder. For an example, refer to thedomain-xamplefolder. Domains should include automated tests that validate the workflow, such as end-to-end tests. These tests can be called manually in the local developer environment and automatically during CI by GitHub actions.
API Endpoints and Controller library module
Under the domain folder, add a ...-api-controller subfolders and populate them with Java code. Because the folder name is used as the jar artifact file name, the folder name should be unique, regardless of where it is in the codebase.
- The
appcontainer module (in the top-level app folder) pulls in each domain's api-controller module to present a single API spec. - Note that API endpoints should rarely be deprecated. Instead, use version numbers in the URL. https://www.mnot.net/blog/2012/12/04/api-evolution
- The controllers should be very minimal in terms of logic. It should check the request payload and immediately inject it into a workflow. This enables error recovery and testing, where the payload can be injected directly into the workflow, bypassing the need for an API and Controller.
VRO serves APIs implemented in non-Java languages without implementing a ...-api-controller subfolder -- see API Gateway.
Shared library module
Domain-specific shared libraries can be implemented in a single subfolder or multiple subfolders. You can use any folder name, such as constants, util, or dto. These subfolders define library modules that can be imported by other modules in the domain.
- In the
domain-xampleexample, thesharedmodule illustrates defining shared domain-specific constants, DTO (data transfer object) classes, and utility classes. - Note that DAO (data access objects) belong in the top-level
persistencefolder because all domains share a DB – see the Add DB Entities section. - Once the code is stable, domain-independent classes can be moved to one of the shared libraries for use by other domains. Ensure these classes are very well tested with unit tests and documented.
Workflows container module
Workflows are implemented within a single ...-workflows subfolder. Because the folder name is used as the Docker image name, the folder name for the container should be unique, regardless of where it is in the codebase.
- For Java, workflows are defined using Camel Routes and Camel Components, which are building blocks for implementing EIPs.
- The Workflows container should implement only Camel Routes and basic processing (workflow logic or data object conversions), not the microservices themselves.
However, for rapid prototyping, early implementations can include microservices in a single container, with the understanding that the microservices will later be extracted into their own containers (as described in the next section).
- A workflow step can call a method on a Java Bean, a custom Camel Processor, etc. to perform basic logic to determine the next process,ng step. Nothing (except maybe a rejection from a manual code review) prevents that component from being big and complex. To avoid this situation, split the workflow into simple steps, which will later facilitate extracting a step into an appropriate service container. In the long term, this will make the workflow easier to understand (workflow logic and transmitted data are encoded at the workflow level), comprehensive (because hidden substeps become an explicit step), and easier to modify (by modifying routes instead of service internals). Workflows should split the processing steps into logical stages, each stage consisting of one or more Camel Routes. Segmenting the workflow facilitates testing and error recovery, as a payload (e.g., a claim) can be injected into any stage. I prefer to design workflows for asynchronous (event-based) processing, leveraging MQ queues to trigger the next step in the workflow. In addition to decoupling workflow steps, this facilitates injecting a payload (manually or as part of another workflow) in strategic intermediate steps within the workflow.
- For Python, Prefect library can be used instead of Camel. To send requests to Service containers, Prefect tasks should send the request over the MQ.
Service (microservice) container module
A microservice is implemented within a svc-... subfolder. There should be a separate folder for each microservice. Because the folder name is used as the Docker image name, the folder name for the service should be unique, regardless of where it is in the codebase.
- For scalability, a microservice is encapsulated in a container so they can be replicated as needed.
- Microservices can be easily scaled by having replicated microservices listen to the same MQ queue; more effort is required to scale using a REST API
- queue-based asynchronous model vs REST API
- A microservice should be stateless, idempotent, and basic (e.g., implementing one step in a workflow).
- A microservice listens for JSON requests on the MQ and always sends a JSON response back to the client via the MQ. Benefits:
- No REST API to set up and manage; less DevOps maintenance (e.g., exposing ports for REST API). Fewer libraries to include implies fewer libraries to maintain for SecRel.
- Makes services easier to test since the input and output are always JSON strings.
- JSON String are easily parsed in any programming language. There is no JSON data structure enforcement unless a JSON Schema is specified and applied.
- A microservice response is always expected by the client to ensure the request was received and processed (or errored). The client can handle the response synchronously (blocks the workflow while waiting for a response) or asynchronously (workflow continues and reacts whenever a response is received).
- https://developer.ibm.com/articles/how-messaging-simplifies-strengthens-microservice-applications/: decoupled communication, pull instead of push workload management, simplified error handling, security is configured in central MQ instead of potentially inconsistently in each microservice
- The expected JSON structure for a microservice response is very flexible. The only requirement is a
headerfield:
{
"someRequestCorrelationId": 987654,
"anyField": { "someSubField": "anyValue" },
"anotherField": 1234.5,
"header": {
"statusCode": 200, // use HTTP status codes
"statusMessage": "error msg or optional msg useful for debugging/observability",
"jsonSchemaName": "optional domain-specific JSON Schema name for msg body",
}
}
- To convey an error or exception to the microservice client, the response JSON String should contain the fields
statusCodeandstatusMessage.- The
statusCodeinteger value should correspond to an HTTP status code. If this key is not present, then the client can assume status code = 200. - The
statusMessageString value should convey some diagnostics and preferably actionable information. This should be present for a non-successstatusCodeto provide details for diagnostics.
- The
- Implement business logic in the Workflow container.
- Do not rely on RabbitMQ-specific retry mechanisms (or any MQ-specific features) in case VRO moves to using some other MQ. Handle retries as part of the Workflow, especially since the retry strategy (e.g., constant-time retry 3 times, exponential backoff, send Slack notification for each retry) will likely depend on the domain. Check the shared libraries or domain-specific code for implemented retry strategies that can be reused.
- A microservice should not call another microservice – implement that as steps in the workflow when possible.
- Except for communication via the MQ container, a microservice should avoid interacting directly with Platform containers. If DB values are needed, have the Workflow load it from the DB and feed that as input to the microservice. If the service needs to write to the DB, have the service output the data back to the Workflow container, which would write to the DB. This facilitates unit testing (so that a mock DB is not needed) and flexibility (e.g., output data can be sent to logs in addition to the DB).
- Integrations with external APIs (VA services) should be implemented as a microservice in order to better isolate and handle external API problems. Additionally it should be implemented in a general manner in order to promote it to a shared microservice.
- The microservice should indefinitely retry connecting to external services rather than exiting and causing the container to fail. Otherwise, when the microservice is deployed to LHDI (where mock services don't exist), the microservice will fail and Kubernetes will keep retrying to start the container. If the microservice loops indefinitely retrying to connect to the external service, this would avoid Kubernetes from unnecessarily restarting the container since the problem is the connection, not the microservice container itself.
- If there is a temporary network or external service issue, the microservice container should not be restarted and interrupt/cancel other activities/processing occurring in the microservice.
- Another reason to keep the container running is to enable diagnostics within the running container in case there is some credential or login issue when deployed to LHDI. If the container keeps restarting, it's challenging to log into the container to diagnose the problem.
- If using Java Spring to connect to the external service, you get this for free because Spring will automatically retry connecting.
- Ideally there is one microservice per container, but if several microservice are very basic, then those microservice can be in a single container to conserve resources.
When implementing the microservice in Java, Groovy, and other Java-based languages:
- To listen to the queue(s), use a RabbitMQ client with the help of Spring – see module
svc-xample-j. - Or use a Camel Route to listen to the queue(s), like the Workflow container module. Use classes in the
:shared:lib-camel-connectormodule to facilitate this.
When implementing the microservice in other languages, such as Python or Ruby :
- Use a RabbitMQ client to listen to the queue(s). There's likely common code to use the client, so set up some mechanism (like a common folder) to share that code across services for easier maintenance and updating. (TODO: create a common library for Python)
All together now
Once the above pieces are implemented, a call to the endpoint flows as follows:
- VRO client sends a request to API endpoint.
- Controller parses the request and sends it to the MQ via the CamelEntrance utility class using the queue named derived from the endpoint URL string. (This convention avoids having to share queue name constants across containers.)
- The controller can choose to send a quick response to the client or wait for some result from the triggered workflow, depending on the semantics of the endpoint.
- The Camel Route (that is listening on the queue) initiates the associated workflow given the request. At the termination of the workflow, the last response message is sent back to the controller.
- One step at a time, the workflow sends JSON-string messages to specific queues (or topics). (Again, use consistent queue naming conventions to avoid synchronizing these constants across containers.)
- A service (that is listening on the specific queue or topic) performs its function and returns an output, which is typically used as input to the next step in the workflow.
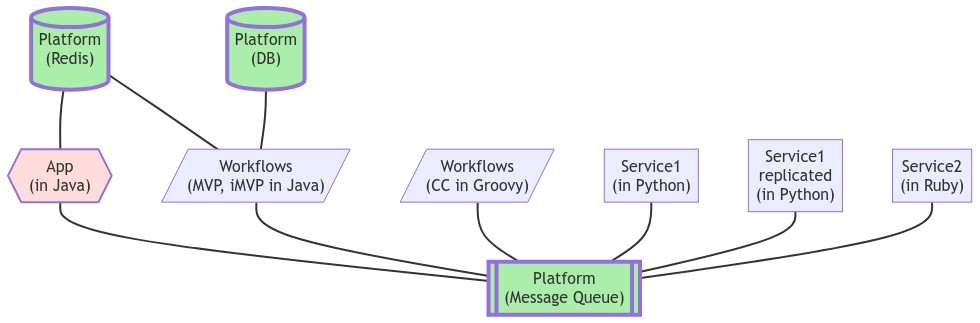
Figure: Interfacing with MQ from various components

Running the xample domain microservices
To run the xample microservices, add xample to the COMPOSE_PROFILES environment variable so that the xample microservices are started for the xample-resource POST endpoint to succeed.
export COMPOSE_PROFILES="$COMPOSE_PROFILES,xample"
Add DB Entities
Since the DB is shared across domains, the associated DB code resides at the top-level persistence folder rather than the domain-specific folder.
- Updates to the DB schema require adding a Flyway migration (in the db-init folder)
- DB models should be consistent across domains and clearly documented with column comments. Great care should be taken to prevent the logic in one domain from incorrectly modifying data values in another domain. DB ORM models should reside in the persistence folder in the appropriate subfolder. These classes do not have to be in sync, but they should be consistent across languages. Note that any domain can use these classes.
Note: A microservice should avoid interacting directly with the DB—a workflow should act as the intermediary (see the DB-related bullet in the Service (microservice) container section). If direct service-to-DB interaction is desired, use the following guidance.
For interacting with the database via Java :
- Add associated Java Entity classes in the
modelsubfolder for use by workflows or some Repository class
For interacting with the database via Python :
- Add associated SQLAlchemy ORM classes in the
sqlalchemysubfolder
For interacting with the database via Ruby on Rails :
- Add associated Rails ActiveRecord classes in the
railssubfolder
Other Details
Message Queue (RabbitMQ)
- The payload or message body is a JSON string.
- Requests/calls/messages can be synchronous or asynchronous.
- MQ queue names are constants that must be shared or synchronized across containers. Using naming conventions reduces the number of constants to be shared (via a library or environment variables).
- For Camel to automatically marshal/unmarshal DTO classes for transmission in the MQ, either define the class in the
gov.va.vro.modelpackage (or nested package) or add to thevro.camel.dto-classes(inconf-camel.yml).
Configuration Settings and Environment Variables
- Configuration settings for software settings within a container
- scripts/setenv.sh for environment variables
- Prefer to add them to
application*.yml(for Java) orsettings*.py(for Python). Those files allow different setting values per deployment env. Adding environment variables incurs the cost of keepingdocker-compose.yml(for local development) and helmcharts (for each LHDI deployment environment) updated. - Valid reasons why a setting should be in the setenv.sh file:
- A setting to support local development (and automated end2end testing)
- Secret credentials like username, password, private token. Only fake secret values belong in this file. Sensitive non-production values are in the abd-vro-dev-secrets repo. Critical production values are set within the Kubernetes deployment environment -- see Secrets Vault.
- A setting that must be the same or shared across containers
- Prefer to add them to
- Feature flags: TBD
SpringBoot Profiles
Merging Workflows Containers
To conserve infrastructure resources, lightweight workflows from a domain can be combined with workflows from other domains to reside in a single container. A lightweight workflow is defined as one that uses very little memory and CPU. The workflow code should be stable and expect no changes between major VRO deployments (e.g., when the VRO API is updated). Combining workflows across domains is quickly done without any code change by treating the workflow module as a library (instead of a container) and importing it into a multi-domain workflows container, which gets deployed instead of the domain-specific container – similar to how the app container imports api-controller modules from several domains.
Versioning
Semantic versioning is used for VRO releases.
- All code (all Gradle modules) have the same version when a code release is created.
- A deployed container uses a Docker image tagged with a specific release version. Since containers may be independently updated, deployed containers may refer to different versions.
Port numbers
VRO platform services use the typical port numbers for the particular service (usually less than port 10,000)
- 5432: Postgres DB service
- 5672: Rabbit MQ service
- 15672: RabbitMQ Management UI
- 6379: Redis cache service
The API Gateway uses the following:
- 8060: API Gateway
- 8061: health check port for the API Gateway
Ports for APIs within VRO
VRO domains offering APIs use this port numbering convention:
- 81Nx = VRO microservice ports, where N is an index
The VRO (Java) App uses the following:
- 8110: VRO App API
- 8110: health check port for the VRO App
The (Python) Contention Classification uses the following:
- 8120: Contention Classification API
- 8121: health check port for Contention Classification
The Employee Experience Team uses the following:
- 8130: Max CFI API (Python) (same port is used for health check due to uvicorn limitations)
- 8140: EP Merge App (Python) (same port is used for health check due to uvicorn limitations)
Ports for VRO microservices
VRO microservices use this port numbering convention:
-
10NNx = VRO microservice ports, where NN is an index
- example: 1010x = ports used for svc-lighthouse-api microservice
- example: 1020x = ports used for svc-bgs-api microservice
-
10NN1 = health check port for microservice NN
- example: 10101 = health check port for svc-lighthouse-api microservice
- example: 10201 = health check port for svc-bgs-api microservice
- example: 10301 = health check port used for svc-bie-kafka microservice
VRO microservices only need to connect to RabbitMQ and do not typically need to expose any service ports except for health checks.
Mock services use this port numbering convention:
- 20NNx = mock service ports, where NN is an index
- 20NN1 = health check port for mock service NN
So the following mock services would use these ports:
- 20100: mock Slack
- 20101: for health check
- 20200: mock Lighthouse API
- 20201: for health check
- 20300: mock BIP Claims
- 20301: for health check
- 20310: mock BIP Claim Evidence
- 20311: for health check
- 20500: mock BGS API
- 20501: for health check
(Note that the 2 BIP mocks use 2030x and 2031x to denote high similarity.)
To see if a port is already being used search the code base for usages of that port.
Running Xample Domain containers
A xample-integration-test GH Action workflow demonstrates an end-to-end test, from VRO API request to microservice.
To manually test svc-workflow and svc-xample-j locally, use Docker Compose:
source scripts/setenv.sh
# Build all containers
./gradlew docker
# Start the relevant containers
./gradlew :dockerComposeUp
./gradlew :domain-xample:dockerComposeUp
COMPOSE_PROFILES="" ./gradlew :app:dockerComposeUp
Open a browser to http://localhost:8110/swagger and go to the POST /v3/xample-resource section and open it. Click "Try it out". In the Request body, replace null with:
{
"resourceId":"1234",
"diagnosticCode":"J"
}
Note: diagnosticCode must be J in order for the request to be routed to the svc-xample-j microservice, as coded in Xample's Camel route.
Click Execute. The response code should be 201 with response body:
{
"resourceId": "1234",
"diagnosticCode": "J",
"status": "PROCESSING",
"statusCode": 0
}
The above can also be done with curl:
curl -X POST "http://localhost:8110/v3/xample-resource" -H "accept: application/json" -H "Content-Type: application/json" \
-d '{"resourceId":"1234","diagnosticCode":"J"}'
# The API response:
{"resourceId":"1234","diagnosticCode":"J","status":"PROCESSING","statusCode":0}%
Check the logs:
docker logs vro-xample-workflows-1
docker logs vro-svc-xample-j-1
Xample code highlights
TODO: Most Xample links were deleted in develop. Should we remove these?
- An HTTP API endpoint is implemented by XampleController
- When an API request is received, the controller sends a one-way MQ message to the Xample Workflow for processing
- In the meantime, the controller sends an API response (with
status="PROCESSING")
- In the meantime, the controller sends an API response (with
- The Xample Workflow uses Camel to route a MQ message to the
svc-xample-jmicroservice - After an artificial delay to simulate processing, the microservice sends a MQ response back to the Xample Workflow
- When the Xample Workflow receives the MQ response, it logs the microservice's response (with
status="DONE")
Run microservice outside of Docker
To run any VRO component outside of Docker, you'll need to configure your environment so that the component can communicate with containers inside of Docker -- some steps for running vro-app in IntelliJ.
For the svc-xample-j microservice, no additional setup is necessary since the defaults to connect to the MQ should work.
source scripts/setenv.sh
./gradlew :dockerComposeUp
./gradlew :domain-xample:dockerComposeUp
COMPOSE_PROFILES="" ./gradlew :app:dockerComposeUp
# Stop the Docker instance of svc-xample-j so you can run svc-xample-j's bootRun outside of Docker
docker stop vro-svc-xample-j-1
./gradlew :domain-xample:svc-xample-j:bootRun
To test, run in a new console:
curl -X POST "http://localhost:8110/v3/xample-resource" -H "accept: application/json" -H "Content-Type: application/json" \
-d '{"resourceId":"1234","diagnosticCode":"J"}'
To build and restart specific containers
- To build the
svc-xample-jDocker image:./gradlew :domain-xample:svc-xample-j:docker- To build all images under the
domain-xamplefolder:./gradlew -p domain-xample build
- To build all images under the
- To run this the updated image:
./gradlew :domain-xample:dockerComposeUp- Alternatively, you can use Docker Compose directly:
docker compose -f domain-xample/docker-compose.yml up svc-xample-j
- Alternatively, you can use Docker Compose directly:
For more see Docker Compose.