Operations On Multiple RDDs - datacouch-io/spark-java GitHub Wiki
Overview
In this lab, we will explore various transformations on RDDs (Resilient Distributed Datasets) in Apache Spark. We will also delve into optimizations and visualize the operations using a Directed Acyclic Graph (DAG). This exercise builds upon the knowledge gained from previous labs related to RDD transformations.
Run time: 30-40 minutes
Meetups: Our Data for this Lab
For this lab, let's assume that we have two users attending various meetups. We will start with two users, and each user attends different meetups, which will be represented as separate RDDs. Our goal is to analyze data for these two users by performing various operations on these RDDs. The operations include union, intersection, distinct, and subtract.
User Data:
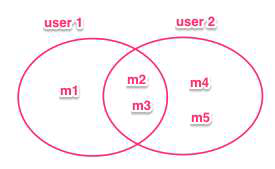
- User1 attends meetups: m1, m2, and m3.
- User2 attends meetups: m2, m3, m4, and m5.
Creating the RDDs
To begin, we create two RDDs representing the meetups attended by each user.
u1 = sc.parallelize(["m1", "m2", "m3"])
u2 = sc.parallelize(["m2", "m3", "m4", "m5"])
Checking Spark UI
After creating the RDDs, if you check the Spark UI's Jobs tab, you won't find any jobs listed. This is because Spark follows a lazy evaluation model, and since no actions have been performed, Spark hasn't executed any transformations yet.
Operations on RDDs
Finding Meetups Common to Both Users
We can find the meetups that are attended by both User1 and User2 by using the intersection operation.
common = u1.intersection(u2)
common.collect()
Finding Meetups Attended by Either User1 or User2
To find meetups attended by either User1 or User2, we use the union operation to combine both RDDs and then apply distinct to remove duplicates.
either = u1.union(u2).distinct()
either.collect()
Finding Meetups Attended by Only One User
To identify meetups that are exclusively attended by one user, we use the subtract operation.
For User1:
onlyU1 = u1.subtract(u1.intersection(u2))
onlyU1.collect()
For User2:
onlyU2 = u2.subtract(u1.intersection(u2))
onlyU2.collect()
Recommendations Based on Specific Rules
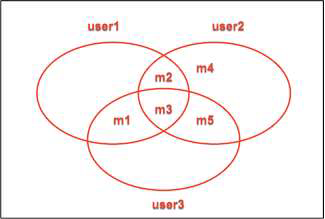
Now, let's introduce a third user (User3) who attends different meetups. We will recommend meetups for each user based on specific rules:
- A user should not be attending a recommended meetup.
- A meetup should be attended by both other users to be recommended.
Let's introduce user3
User3 attends meetups: m1, m3, and m5, as illustrated below.
Creating RDD for User3
We create an RDD u3 representing the meetups attended by User3.
u3 = sc.parallelize(["m1", "m3", "m5"])
Finding Recommendations for Users
For User1:
forU1 = u2.intersection(u3).subtract(u1)
forU1.collect()
For User2:
forU2 = u1.intersection(u3).subtract(u2)
forU2.collect()
For User3:
forU3 = u1.intersection(u2).subtract(u3)
forU3.collect()
Discussions on What's Seen in the Spark Shell UI
Let's consider at some of the results you might have seen earlier in the UI. Here's the DAG from finding the meetups in common (an intersection of the two RDDs).
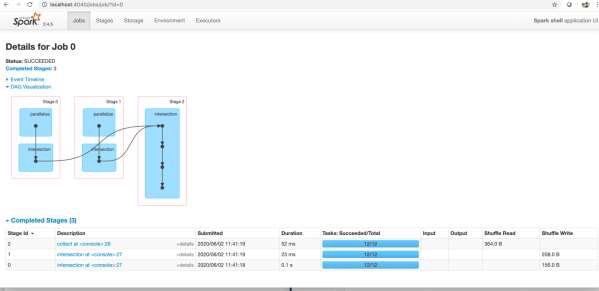
What you're seeing is this.
- Each shaded blue box represents a user operation.
- A dot in the box represents an RDD created in the corresponding operations.
- Operations are grouped by stages (In a stage, operations on partitions are pipelined in the same task).
- You can click on any stage, to drill down into it for more detail.
- Parallelization of each RDD occurs in one stage (e.g. on one node, with local data)
- Some of the intersection can happen on one stage (using whatever data is local)
- Some of the intersection happens in another stage
- Because it can no longer be done with local data - it involves data distributed over the cluster.
- Data is shuffled for the intersection to be done (i.e. sent from one node to another).
- Shuffling is expensive - we'll talk more about this later.
Here are the details on the stages (from the Completed Stages section on the same page). It gives details on the data that is shuffled.
Here's another DAG - from finding the meetups attended by either user (a union of the two RDDs).

What you're seeing is this.
- Parallelization of each RDD occurs in one stage (e.g. on one node, with local data)
- And yes, Spark has to parallelize again, because default is not to cache an RDD.
- The union happens in the same stage - It can all be done with local data
- Part of the distinct has to be done in a separate stage - it also requires shuffling data
Use Case: Airport Data Analysis with Spark
Problem Statement
Create a Spark program to read airport data from the "airports.txt" file, filter airports located in the United States, and output the airport's name and the city's name to the "out/airports_in_usa" directory.
Input Data Format (airports.txt)
Each row of the input file contains the following columns:
Airport ID, Name of airport, Main city served by airport, Country where airport islocated, IATA/FAA code, ICAO Code, Latitude, Longitude, Altitude, Timezone, DST, Timezone in Olson format
Sample Output Format (airports_in_usa)
"Airport Name 1", "City Name 1" "Airport Name 2", "City Name 2" ...
Implementation Steps
- Read the airport data from "airports.txt" into an RDD.
- Filter the airports that are located in the United States.
- Map the data to extract the airport's name and the city's name.
- Save the resulting RDD to the "out/airports_in_usa" directory.
Spark Job Submission
To submit your Spark job, follow these steps:
- Navigate to the folder where Spark is installed.
- Use the following command to submit the job:
spark3-submit --master yarn --class YourSparkClass /path/to/your/spark/program.py`
Verification
After running the Spark job, verify the output in the "out/airports_in_usa" directory in HDFS to ensure that the airport data for airports in the United States has been correctly extracted and saved.
This use case demonstrates how to perform data filtering and transformation with Spark RDDs, which is a common task in big data processing.