Spring Boot - darmoise/wiki GitHub Wiki
Центральной частью Spring является подход Inversion of Control, который позволяет конфигурировать и управлять объектами Java с помощью рефлексии. Вместо ручного внедрения зависимостей, фреймворк забирает ответственность за это посредством контейнера. Контейнер отвечает за управление жизненным циклом объекта: создание объектов, вызов методов инициализации и конфигурирование объектов путём связывания их между собой.
Объекты, создаваемые контейнером, также называются управляемыми объектами (beans).
- отделение выполнения задачи от ее реализации;
- легкое переключение между различными реализациями;
- большая модульность программы;
- более легкое тестирование программы путем изоляции компонента или проверки его зависимостей и обеспечения взаимодействия компонентов через контракты.
Подробнее можно прочитать тут.
- Парсирование кофигурации (XML, JavaConfig и тд). После парсирования конфигурации создается BeanDefenition - мета информация, описывающая будущий бин;
- Настройка уже созданных BeanDefinition - на этом этапе мы можем повлиять на то, какими будут наши бины еще до их создания;
- Создание кастомных FactoryBean - можно самостоятельно создать фабрику, которая будет создавать бины определенного типа;
- Создание экземпляров бинов - тут происходит создание классов или проксей. На этом этапе можно организовать инжект поля через конструктор;
- Настройка созданных бинов - BeanPostProcessor - именно то, что нам нужно. На этом этапе конструктор бина уже выполнился и бин создан, но бин еще не попал в контекст.
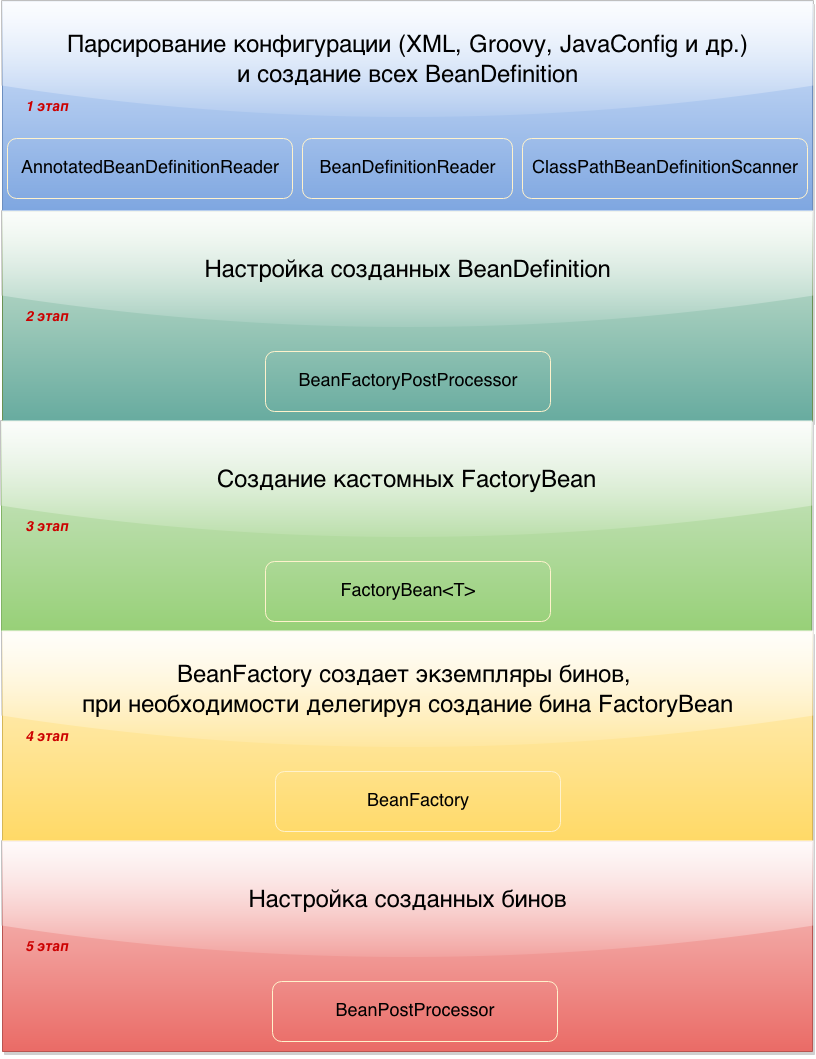
Цель первого этапа создание всех BeanDefinition — специального интерфейса, через который можно получить доступ к метаданным будущего бина.
Для Xml конфигурации используется класс — XmlBeanDefinitionReader, который реализует интерфейс BeanDefinitionReader. Тут все достаточно прозрачно. XmlBeanDefinitionReader получает InputStream и загружает Document через DefaultDocumentLoader. Далее обрабатывается каждый элемент документа и если он является бином, то создается BeanDefinition на основе заполненных данных (id, name, class, alias, init-method, destroy-method и др.).
Контекст можно получить следующим образом:
ClassPathXmlApplicationContext(“context.xml”);Каждый BeanDefinition помещается в Map. Map хранится в классе DefaultListableBeanFactory. В коде Map выглядит вот так.
/** Map of bean definition objects, keyed by bean name */
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<String, BeanDefinition>(64);Пример XML:
<beans....>
<bean class="com.inwhite.spring.compare.CoolDaoImpl" id="coolDao"/>
<bean id ="coolService" class="com.inwhite.spring.compare.CoolServiceImpl"
init-method="init"
destroy-method="closeResources"
scope="prototype">
<property name="dao" ref="coolDao"/>
</bean>
</beans>Контекст можно получить следующим образом:
new AnnotationConfigApplicationContext(“package.name”);Конфигурация через аннотации с указанием класса с @Configuration или с указанием пакета сканирования
Используется класс AnnotationConfigApplicationContext:
new AnnotationConfigApplicationContext(JavaConfig.class); // JavaConfig
new AnnotationConfigApplicationContext(“package.name”); // указание пакета для сканированияВнутри AnnotationConfigApplicationContext есть следующие поля:
/*
* Работает в два этапа
* 1. Регистрацияя всех @Configuration для парсирования.
* Если в конфигурации используется @Conditional,
* то будут задействованы только те конфигурации,
* для которых проверка вернет true;
* 2. Регистрация специального BeanFactoryPostProcessor,
* а именно BeanDefinitionRegistryPostProcessor, который (при помощи класса ConfigurationClassParser)
* парсирует JavaConfig и создает BeanDefinition.
*/
private final AnnotatedBeanDefinitionReader reader;
/*
* сканирует указанный пакет на наличие классов,
* помеченных аннотацией @Component,
* помеченные классы парсируются и для них создается BeanDefinition.
*/
private final ClassPathBeanDefinitionScanner scanner; По стилю похожа на XML, за исключением, что используется Groovy. Контекст получается следующим образом:
new GenericGroovyApplicationContext(“context.groovy”).Внутри GenericGroovyApplicationContext находится поле:
private final GroovyBeanDefinitionReader reader; // занимается чтением конфигуарцииПосле первого этапа у нас есть Map, в котором хранятся BeanDefinition. У нас есть возможность повлиять на то, какими будут наши бины еще до их фактического создания, иначе говоря мы имеем доступ к метаданным класса. Для этого существует специальный интерфейс BeanFactoryPostProcessor, реализовав который, мы получаем доступ к созданным BeanDefinition и можем их изменять:
public interface BeanFactoryPostProcessor {
/*
* ConfigurableListableBeanFactory - фабрика, которая содержит много полезных методов, например,
* getBeanDefinitionNames, который позволяет получить все имена BeanDefinition, а уже по имени получить
* BeanDefinition для обработки метаданных.
*/
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
}Одна из родных реализаций интерфейса BeanFactoryPostProcessor - PropertySourcesPlaceholderConfigurer. Например, из application.property считывается данные для подключения к БД этого конфигуратора и inject'ятся в нужное поле. Так как inject делается по ключу, то до создания экземпляра бина нужно заменить ключ на заначение из файла.
Пример класса для inject'а:
/*
* Если PropertySourcesPlaceholderConfigurer не обработает этот BeanDefinition,
* то после создания экземпляра ClassName,
* в поле host проинжектится значение — "${host}"
* (в остальные поля проинжектятся соответствующие значения).
*/
@Component
public class ClassName {
@Value("${host}")
private String host;
@Value("${user}")
private String user;
@Value("${password}")
private String password;
@Value("${port}")
private Integer port;
} 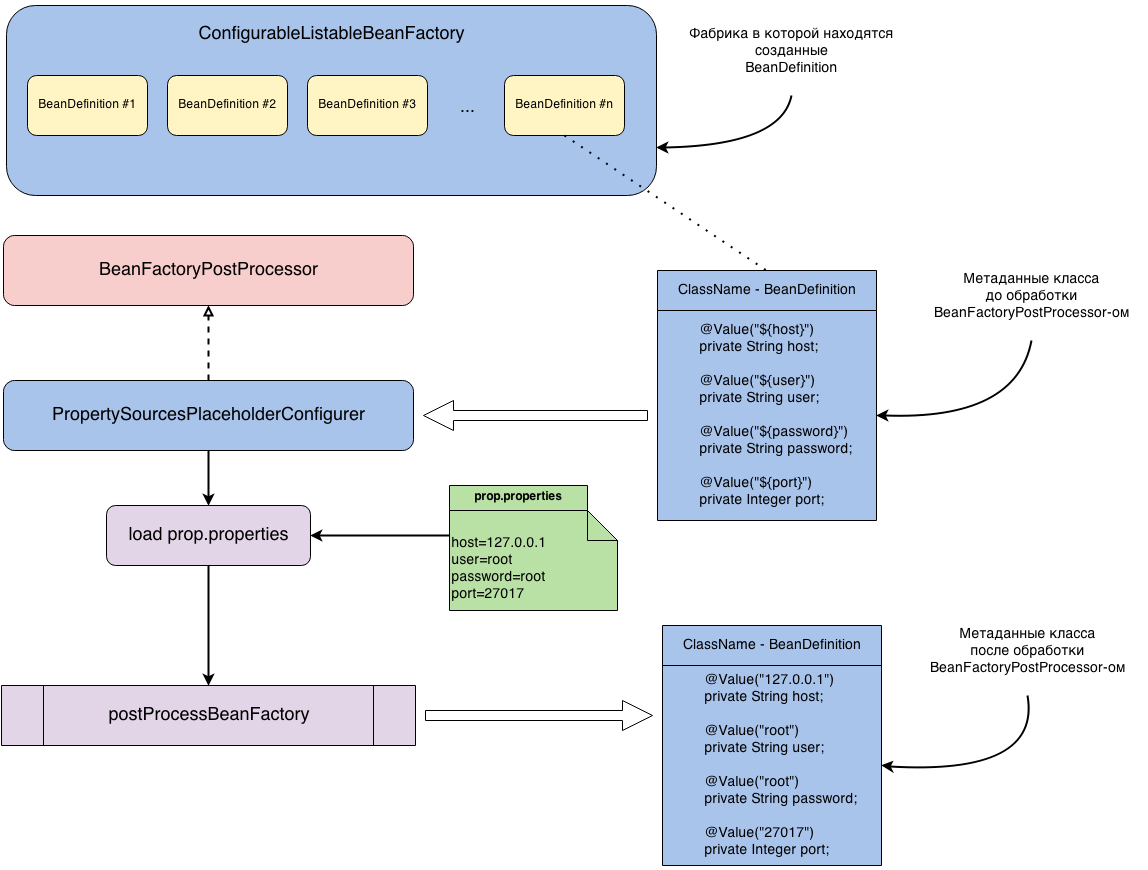
Чтобы конфигуратор был добавлен в цикл настройки созданных BeanDefinition, создать для него бин:
@Configuration
@PropertySource("classpath:property.properties")
public class DevConfig {
@Bean
public static PropertySourcesPlaceholderConfigurer configurer() {
return new PropertySourcesPlaceholderConfigurer();
}
}FactoryBean — это generic интерфейс, которому можно делегировать процесс создания бинов типа . В те времена, когда конфигурация была исключительно в xml, разработчикам был необходим механизм с помощью которого они бы могли управлять процессом создания бинов. Именно для этого и был сделан этот интерфейс. Для тех кто пользуется JavaConfig, этот интерфейс будет абсолютно бесполезен.
<!-- На первый взгляд, тут все нормально и нет никаких проблем -->
<!-- А что если нужен еще один цвет, или вообще случайный, вот тут на помощь приходит FactoryBean -->
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="redColor" scope="prototype" class="java.awt.Color">
<constructor-arg name="r" value="255" />
<constructor-arg name="g" value="0" />
<constructor-arg name="b" value="0" />
</bean>
</beans>Создадим фабрику для создания бинов типа Color:
package com.malahov.factorybean;
import org.springframework.beans.factory.FactoryBean;
import org.springframework.stereotype.Component;
import java.awt.*;
import java.util.Random;
public class ColorFactory implements FactoryBean<Color> {
@Override
public Color getObject() throws Exception {
Random random = new Random();
Color color = new Color(random.nextInt(255), random.nextInt(255), random.nextInt(255));
return color;
}
@Override
public Class<?> getObjectType() { return Color.class; }
@Override
public boolean isSingleton() { return false; }
}Теперь добавим эту фабрику в xml-конфиг:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="colorFactory" class="com.malahov.temp.ColorFactory"/>
</beans>Теперь создание бина типа Color.class будет делегироваться ColorFactory, у которого при каждом создании нового бина будет вызываться метод getObject.
Созданием экземпляров бинов занимается BeanFactory при этом, если нужно, делегирует это кастомным FactoryBean. Экземпляры бинов создаются на основе ранее созданных BeanDefinition.

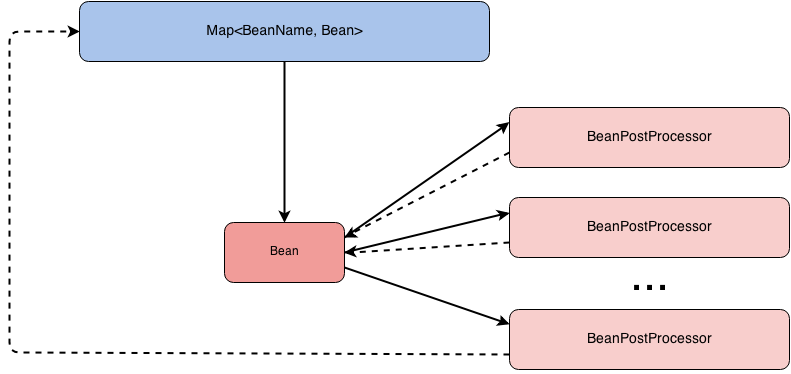
Интерфейс BeanPostProcessor позволяет вклиниться в процесс настройки ваших бинов до того, как они попадут в контейнер. Интерфейс несет в себе несколько методов.
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException;
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException;
}Оба метода вызываются для каждого бина. На данном этапе экземпляр бина уже создан и идет его донастройка, соответственно:
- Оба метода в итоге должны вернуть бин. Если в методе вы вернете null, то при получении этого бина из контекста вы получите null, а поскольку через бинпостпроцессор проходят все бины, после поднятия контекста, при запросе любого бина вы будете получать фиг, в смысле null.
- Если вы хотите сделать прокси над вашим объектом, то имейте ввиду, что это принято делать после вызова init метода, иначе говоря это нужно делать в методе postProcessAfterInitialization.
Полезной может быть эта статья.
В некоторых задачах можно создать прокси-класс для логирования:
- Создадим аннотацию
@Logging, которая будет вешаться над классом, методы которого нужно логировать Пример:
@Retention(RetentionPolicy.RUNTIME)
public @interface Logging {
}Создаем кастомный BeanPostProcessor:
@Slf4j
@Component
public class LoggingBeanPostProcessor implements BeanPostProcessor {
private final Map<String, Class<?>> map = new HashMap<>(); // Мапа, в которую сохраняются классы, помеченные аннотацией Logging
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
Class<?> cls = bean.getClass();
if (cls.isAnnotationPresent(Logging.class)) {
map.put(beanName, cls);
}
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
val cls = map.get(beanName);
if (cls != null) {
return Proxy.newProxyInstance(
bean.getClass().getClassLoader(),
bean.getClass().getInterfaces(),
(proxy, method, args) -> {
val methodName = method.getName();
val argsAsString = Arrays.stream(args)
.map(Object::toString)
.collect(Collectors.joining(", "));
log.info("Start " + methodName + "(" + argsAsString + ")");
val retVal = method.invoke(bean, args);
log.info("Finish " + methodName);
return retVal;
}
);
}
return bean;
}
}Это самый обычный объект, разница в том, что бинами принято называть те объекты, которые управляются Spring и живут внутри DI-контейне ра.
По умолчанию бин задается - синглтон. Таким образом все публичные переменные класса могут быть изменены одновременно из разных мест, а значит бин - не потокобезопасен. Однако поменяв область действия бина на другую можно сделать его потокобезопасным (но производительность упадет).
- name - уникальный идентификатор бина;
- initialization method - метод инициализации бина;
- destroy method - метод уничтожения бина, который будет использоваться при уничтожении контейнера, содержащего бин;
- autowireCandidate - является ли этот компонент кандидатом на автоматическое подключение к какому-либо другому компоненту.
- singleton - один единственный bean для каждого контейнера Spring IoC (используется по умолчанию).
- prototype - создает новый экземляр бина на каждое обращение к объекту (т.е. будет иметь неограниченное количество экземпляров bean).
- request - создается один экземпляр бина на каждый HTTP-запрос.
- session - создается один экземпляр бина на каждую HTTP-сессию.
- web socket - создается определенный экземпляр для определенного сокета.
- application - создается один экземпляр бина для жизненного цикла бина. Похоже на singleton, но когда бины ограничены областью приложения.
- Загрузка описаний бинов, создание графа зависимостей(между бинами);
- Создание и запуск BeanFactoryPostProcessors;
- Создание бинов;
- Spring внедряет значения и зависимости в свойства бина;
- Если бин реализует метод setBeanName() из интерфейса NameBeanAware, то ID бина передается в метод
- Если бин реализует BeanFactoryAware, то Spring устанавливает ссылку на bean factory через setBeanFactory() из этого интерфейса;
- Если бин реализует интерфейс ApplicationContextAware, то Spring устанавливает ссылку на ApplicationContext через setApplicationContext();
- BeanPostProcessor это специальный интерфейс, и Spring позволяет бинам имплементировать этот интерфейс. Реализуя метод postProcessBeforeInitialization(), можно изменить экземпляр бина перед его(бина) инициализацией(установка свойств и т.п.);
- Если определены методы обратного вызова, то Spring вызывает их. Например, это метод, аннотированный @PostConstruct или метод initMethod из аннотации @Bean;
- Теперь бин готов к использованию. Его можно получить с помощью метода ApplicationContext#getBean();
- После того как контекст будет закрыт(метод close() из ApplicationContext), бин уничтожается;
- Если в бине есть метод, аннотированный @PreDestroy, то перед уничтожением вызовется этот метод; Если бин имплементирует DisposibleBean, то Spring вызовет метод destroy(), чтобы очистить ресурсы или убить процессы в приложении. Если в аннотации @Bean определен метод destroyMethod, то вызовется и он.
Если в классе будет статический метод, то при инициализации впервую очередь создастся статический метод (из-за особенностей статических полей), а потом уже Bean, который "навешивается" на статический метод. При этом Spring не позволяет внедрять бины напрямую в статические поля, нужно создать нестатический сеттер-метод
- Model - блок объединяет данные приложения (на практике POJO классы);
- View - блок отвечает за возвращения клиенту наполнения в виде текста или изображений.;
- Controller - включен между Model и View. Управляет процессом преобразования входящих запросов в адекватные ответы. Действует как ворота, направляющие всю поступающую информацию. Переключает поток информации из модели в представление и обратно.
Создает условие бин, если выполняется условие.
Фронт-контролер в проекте Spring MVC.
Указывает, что класс осуществляет функции сервиса. Можно указать название сервиса в параметрах.
Используется, чтобы отметить, что метод будет выполняться по расписанию. Принимает в себя один атрибут из списка: cron, fixedDelay (задача будет выполнена в первый раз после значения initialDelay, и она будет продолжать выполняться в соответствии с fixedDelay), fixedRate (следующая задача не будет вызвана до тех пор, пока не будет выполнена предыдущая).
Используется для связывания с URL.
Позволяет отправлять Object в запросе.
Позволяет отправлять query-параметр в запросе.
Позволяет отправлять path variable в запросе.
@Qualifier - используется совместно с @Autowired для уточнения данных связывания, когда возможны коллизии (например одинаковых имен\типов).
Указывает scope для бина.
Указывает на то, что бин должен быть инициализирован лениво. Для того, чтобы бин создавался в момент обращения к нему, инжектить надо через setter'ы:
@Configuration
public class ChildConfig {
@Bean
@Lazy
public Child1 child1() {
return new Child1();
}
}
public class Child1 {
private String value = "2";
@PostConstruct
void onInit() {
System.out.println("child1");
}
public void setValue(String value) {
this.value = value;
}
}
@RestController
@RequestMapping(value = "/api/v1/")
public class Controller {
private final Child1 child1;
public Controller(@Lazy final Child1 child1) {
this.child1 = child1;
}
}
// or
@RestController
@RequestMapping(value = "/api/v1/")
public class Controller {
private Child1 child1;
@Autowired
public void setChild1(@Lazy Child1 child1) {
this.child1 = child1;
}
}Аннотацию @Lazy надо повесить над бином и над сеттером/конструктором, в который зависимость внедряется.
Если вы используете преимущественно внедрение через конструктор, можно создать неразрешимый сценарий циклической зависимости. Например: Класс A требует экземпляр класса B через внедрение на основе конструктора, а класс B требует экземпляр класса A через внедрение на основе конструктора. Если сконфигурировать бины классов A и B на внедрение друг в друга, IoC-контейнер Spring обнаружит эту циклическую ссылку во время выполнения и сгенерирует исключение BeanCurrentlyInCreationException.
Одним из возможных решений является редактирование исходного кода некоторых классов, чтобы конфигурирование осуществлялось с помощью сеттеров, а не конструкторов. Еще один вариант, использование аннотации @Lazy:
@Service
public class AService {
private final BService service;
@Autowired
public AService(@Lazy BService service) {
this.service = service;
}
public String get() {
return String.valueOf(service.hashCode());
}
}
@Service
public class BService {
private final AService service;
@Autowired
public BService(@Lazy AService service) {
this.service = service;
}
public String get() {
return String.valueOf(service.hashCode());
}
}Они все служат для обозначения класса как бин:
- @Component - кандидата для создания bean;
- @Service - класс содержит бизнес-логику и вызывает методы на уровне хранилища. Ничем не отличается от классов с @Component;
- @Repository - указывает, что класс выполняет роль хранилища (объект доступа к DAO). При этом отлавливает определенные исключения персистентности и пробрасывает их как одно непроверенное исключение Spring Framework. Для этого Spring оборачивает эти классы в прокси, и в контекст должен быть добавлен класс PersistenceExceptionTranslationPostProcessor;
- @Controller - указывает, что класс выполняет роль контроллера MVC. Диспетчер сервлетов просматривает такие классы для поиска @RequestMapping; 4.1. @RestController Автоматически добавляются аннотации @Controller, а так же @ResponseBody (позволяет отправлять Object в ответе) применяется ко всем методам;
- @RedisHash - аналог @Entity для Redis. Указываю hash и время жизни;
- @Id - отмечает ключ;
- @Indexed - отмечает индекс (по нему можно искать).
Представляет функции CRUD (Create, Read, Update, Delete).
- Можно ли сменить логику существующих методов в репозитории? Например есть findAll() и нужно, не переименовывая метод, сделать, например, чтобы данные сортировались. Да, можно, просто переопределяем метод, @Override не добавляем, добавляем @Query.
- save(S entity);
- Iterable
saveAll(Iterableentities); - findById(ID id);
- existsById(ID id);
- findAll();
- findAllById(Iterable ids);
- count();
- deleteById(ID id);
- delete(T entity);
- deleteAllById(Iterable<? extends ID> ids);
- void deleteAll(Iterable<? extends T> entities);
- void deleteAll().
Этот интерфейс предоставляет метод findAll(Pageable pageable), который позволяет разбивать на страницы (Pageable). Pageable - page size, current page number, sorting (ASC, DESC).
- findAll(Sort sort);
- findAll(Pageable pageable);
- findAll();
- findAll(Example example, Sort sort);
- saveAll(Iterable
entities); - flush() – сбросить все ожидающие задачи в БД;
- saveAndFlush(S entity) – сохранить объект и немедленно flush изменения, используется, когда нашей бизнес-логике необходимо прочитать сохраненные изменения на более позднем этапе той же транзакции до commit;
- deleteAllInBatch(Iterable entities) – удалить итерируемый объект, можем передать несколько объектов, чтобы удалить их в batch режиме.
Говорит Hibernate (ORM), что класс является сущностью.
Указывает схему и таблицу в БД. Если имя класса и имя таблицы совпадают, то аннотацию можно не указывать.
Указывает колонку таблицы.
Указывает на primary key.
Указывает на то, что Hibernate должен сгенерировать ID объекта, в соответствии с одной из стратегий: AUTO, IDENTITY, SEQUENCE, TABLE. Эти четыре типа генерации приведут к созданию одинаковых значений, но с использованием разных механизмов базы данных.
Будет применен генератор на основе типа ключа (UUID, Integer и т.д.).
Идентификатор будет автоматически увеличиваться, но будут отключены batch-обновления.
Использует последовательности (если БД поддерживает, если не поддерживает, то переключается на table-генерацию).
@Entity
public class User {
@Id
@GeneratedValue(generator = "sequence-generator")
@GenericGenerator(
name = "sequence-generator",
strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",
parameters = {
@Parameter(name = "sequence_name", value = "user_sequence"),
@Parameter(name = "initial_value", value = "4"),
@Parameter(name = "increment_size", value = "1")
}
)
private long userId;
// ...
}В этом примере мы также установили начальное значение для последовательности, что означает, что генерация первичного ключа начнется с 4.
Этот генератор использует сегменты генерации значений идентификаторов базовой таблицы БД.
При помощи этой аннотация можно указать кастомный генератор id.
Некоторые аргументы аннотаций:
- cascade - операции могут быть каскадными, по умолчанию отключено;
- fetch type - тип выборки данных, может быть ленивым (LAZY) и не терпеливым (eager).
Одна запись в таблице A ссылается на одну запись в таблице B.
Одна запись в таблице A ссылается на много записей в таблице B.
Много записей в таблице B, ссылаются на одну запись в таблице A.
Много записей в таблице A (сотрудники) ссылается на много записей в таблице B (задачи).
Аннотация @JoinColumn определяет столбец, который объединит два объекта. Он определяет столбец foreign key сущности и связанное с ним поле primary key. Эта аннотация позволяет нам создавать связи между сущностями, быстро сохранять данные и получать к ним доступ. Обычно он используется с аннотациями @ManyToOne или @OneToOne для определения ассоциации.
Проблема N + 1 возникает, когда фреймворк доступа к данным выполняет N дополнительных SQL-запросов для получения тех же данных, которые можно получить при выполнении одного SQL-запроса.
Есть две сущности:
Мы получем проблему N + 1, когда вместо одного запроса выполняем 5:
SELECT
pc.id AS id,
pc.review AS review,
pc.post_id AS postId
FROM post_comment pc
SELECT p.title FROM post p WHERE p.id = 1
SELECT p.title FROM post p WHERE p.id = 2
SELECT p.title FROM post p WHERE p.id = 3
SELECT p.title FROM post p WHERE p.id = 4Для решения проблемы можно поступить следующим образом (извлечь все данные одним запросом):
SELECT
pc.id AS id,
pc.review AS review,
p.title AS postTitle
FROM post_comment pc
JOIN post p ON pc.post_id = p.idИспользование FetchType.EAGER для JPA - плохая идея, тем более он подвержен проблеме N + 1. Поэтому стоит использовать FetchType.LAZY. Либо сделать запрос JOIN FETCH через EntityManager:
List<PostComment> comments = entityManager.createQuery("""
select pc
from PostComment pc
join fetch pc.post p
""", PostComment.class)
.getResultList();
for(PostComment comment : comments) {
LOGGER.info(
"The Post '{}' got this review '{}'",
comment.getPost().getTitle(),
comment.getReview()
);
}- value/cacheNames - имя (имена) кэшей, в которых хранятся результаты вызова методов;
- key - выражение в SpEL (Spring Expression Language) для динамического вычисления ключа;
- conditional - выражение в SpEL для условия кэширования.
Проблема кэша в том, что он не может быть бесконечным. Аннотация позволяет удалить одно или несколько (все) значений. allEntries = true говорит о том, что нужно полностью очистить кэш.
Позволяет обновлять содержание кэша во время выполнения метода. Отличие этой аннотации от @Cachable в том, что @CachePut сначала запустит метод, а потом поместит его результаты в кэш.
Клиент для загрузки properties файлов с Config Server и загрузки в DI-контейнер бинов, специфичных для Spring Cloud компонентов. Поддерживает
Расширение Spring Security, реализует:
- Единый вход OAuth2, с ретрансляцией токенов (проброс токенов извне, через Gateway).
- Защиту ресурсов токенами OAuth2
Пример: Создаем конфигурацию для web security:
@Configuration
public class WebSecurityConfiguration {
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
return http
.csrf(AbstractHttpConfigurer::disable)
.authorizeHttpRequests(ahr -> {
ahr.requestMatchers(
// путь, доступ к которому возможен только после авторизации
"/api/v1/private/**"
).fullyAuthenticated()
.anyRequest().permitAll(); // любой запрос, разрешить всем
})
.httpBasic(Customizer.withDefaults()) // basic auth используем
.build();
}
// использщуется для хранения пароля в хэшированном виде
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder(8);
}
}Далее создаем сервис, который обращается к БД для получения данных о пользователе (должен реализовывать интерфейс UserDetailsService):
@Service
@RequiredArgsConstructor
public class UserService implements UserDetailsService {
private final PasswordEncoder passwordEncoder;
private final UserHelperService userHelperService;
private final UserMapper userMapper;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
/*
* Получаем данные пользователя из таблицы
* Модель реализует интерфейс UserDetails
*/
return userMapper.toModel(
userHelperService.findByUsername(username)
);
}
// ...
// ТУТ ДРУГОЙ КОД
// ...
// создаем пользователя, пароль хэшируем
private UserEntity createUserEntity(final RegUser model) {
val account = new Account();
val encodedPassword = passwordEncoder.encode(model.password());
val spk = Base58.encode(account.getSecretKey());
return userMapper.toEntity(model)
.setPassword(encodedPassword)
.setAddress(account.getPublicKey().toBase58())
.setPk(spk);
}
}Создаем authorization provider для basic auth:
@Slf4j
@Component
@RequiredArgsConstructor
public class UserAuthenticationProvider implements AuthenticationProvider {
private final PasswordEncoder passwordEncoder;
private final UserService userService;
@Override
public Authentication authenticate(Authentication authentication) throws AuthenticationException {
val username = authentication.getName(); // получаем имя пользователя из запроса
val rawPassword = authentication.getCredentials().toString(); // получаем пароль
// получаем данные для пользователя из таблицы
UserDetails userDetails = userService.loadUserByUsername(username);
val encodedPassword = userDetails.getPassword();
// проверяем хэши паролей
if (passwordEncoder.matches(rawPassword, encodedPassword)) {
return new UsernamePasswordAuthenticationToken(
username,
encodedPassword,
userDetails.getAuthorities()
);
}
else {
// выбрасываем исключение, если данные для авторизации некорректные
throw new BadCredentialsException(ErrorCode.CREDENTIALS.getMessage());
}
}
@Override
public boolean supports(Class<?> authentication) {
return authentication.equals(UsernamePasswordAuthenticationToken.class);
}
}Декларативный REST клиент.
Используется для валидации полей в запросе (пример, аннотации @NotNull, @Size, @NotEmpty, @Positive).
Можно создать кастомную аннотацию, для примера создадим аннотацию для проверки password и confirmPassword на эквивалетность.
Создадим саму аннотацию:
@Documented
// указываем класс, который используется для валидации
@Constraint(validatedBy = PasswordsEqualsValidator.class)
@Target({ElementType.TYPE, ElementType.METHOD, ElementType.FIELD, ElementType.PARAMETER})
@Retention(RUNTIME)
public @interface PasswordsEquals {
String password(); // название поля пароля с паролем
String confirmPassword(); // название поля с подтверждением пароля
String message() default "Invalid password";
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
@Target({ ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@interface List {
PasswordsEquals[] value();
}
}Создадим сам валидатор (должен реализовывать ConstraintValidator):
public class PasswordsEqualsValidator implements ConstraintValidator<PasswordsEquals, Object> {
private String password;
private String confirmPassword;
@Override
public void initialize(PasswordsEquals constraintAnnotation) { // принимает аннотацию на вход
this.password = constraintAnnotation.password();
this.confirmPassword = constraintAnnotation.confirmPassword();
}
@Override
public boolean isValid(Object value, ConstraintValidatorContext context) { //
String passwordValue = (String) new BeanWrapperImpl(value).getPropertyValue(password);
String confirmPasswordValue = (String) new BeanWrapperImpl(value).getPropertyValue(confirmPassword);
return Objects.equals(passwordValue, confirmPasswordValue);
}
}Создадим объект, в котором будем проверять поля:
@PasswordsEquals(
password = "password",
confirmPassword = "confirmPassword"
)
public record RegUserDto(
@NotBlank(message = "Invalid username")
String username,
@NotBlank(message = "Password is empty")
String password,
@NotBlank(message = "Confirm password is empty")
String confirmPassword
) {
}Основная идея в выделении так называемой сковозной функциональности.
- Join point - точка наблюдения, присеодинения к коду, где планируется внедрнение функциональности.
- Pointcut - это срез, запрос точек присоединения
- Advice - набор инструментов, выполняемых на точках среза (Pointcut). Инструкции можно выполнять по событиям разных типов:
- Before — перед вызовом метода
- After — после вызова метода
- After returning — после возврата значения из функции
- After throwing — в случае exception
- After finally — в случае выполнения блока finally
- Around — можно сделать пред., пост., обработку перед вызовом метода, а также вообще обойти вызов метода.
На один Pointcut можно повесить несколько Advice разного типа. 4. Aspect - модуль, в котором собраны описания Pointcut и Advice.
Пример:
ДОБАВИТЬИщет есть ли бин TransactionManager. Если он есть Spring его автоматически подключает. Если его не удалось найти, тогда мы должны указать его явно (value, transactionManager).
У аннотации также есть следующие аргументы:
- propagation - тип propagation
- REQUIRED/DEFAULT - если запущена транзакция — выполнять внутри нее, иначе создает новую транзакцию. Если ошибка в запросе, то в базу ничего на запишется.;
- SUPPORTS - методу не важно, будет транзакция или нет, он в любом случае выполнится, но если будет транзакция, то он выполнится внутри нее.;
- MANDATORY - использует существующую транзакцию. Если ее нет — бросает exception.;
- REQUIRES_NEW - создает в любом случае новую транзакцию. Если запущена существующая транзакция — она останавливается на время выполнения метода, новый метод выполняется в новой транзакции, и дальше выполняется внешняя транзакция, если она есть;
- NOT_SUPPORTED - означает не выполнять в текущей транзакции. Если транзакция запущена — она останавливается на время выполнения метода. Метод выполняется вне транзакции. Когда метод выполнился — транзакция запускается.;
- NEVER - означает, что данный метод не должен выполняться в транзакции. Если транзакция запущена — бросает exception.;
- NESTED - вложенная транзакция (подтранзакция). Подтвержается вместе с внешней транзакцией.Если нет существующей транзакции — работает как REQUIRED..
- timeout - таймаут для транзакции в секундах;
- isolation - уровень изоляции (READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE);
- rollbackFor - указываем роллбэк для определенного exception;
- noRollbackFor — Указывает, что откат не должен происходить, если целевой метод вызывает исключение, которое вы укажете.
Он создает EntityManager, если он необходим, и осуществляет старт новой транзакции. В зависимости от того, выполняется ли хоть одна транзакция в текущий момент или нет и параметра “propagation” у метода, аннотированного @Transactional, создается новая транзакция.
- создается новый EntityManager;
- EntityManager привязывается к “текущему потоку Thread”;
- берется соединение из пула соединений БД;
- это соединение привязывается к “текущему потоку Thread” при помощи ThreadLocal (Класс ThreadLocal предоставляет локальные переменные потока. Каждый поток имеет свою собственную инициализированную копию переменной).
Представляет необходимый интерфейс для работы с несколькими объектами в контексте сохранения. Определить границы транзакции вручную можно следующим образом:
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("jpa-example");
EntityManager entityManager = entityManagerFactory.createEntityManager();
try {
entityManager.getTransaction().begin();
entityManager.persist(firstEntity);
entityManager.persist(secondEntity);
entityManager.getTransaction().commit();
} catch (Exception e) {
entityManager.getTransaction().rollback();
}Если true (по умолчанию), то сессия Hibernate держится открытой все время обработки HTTP-запроса, включая этап создания представления (View) - JSON-ресурса и HTML-странице. Это делает возможным ленивую загрузку данных в слое представления после коммита транзакции в слое бизнес-логики. Например, мы запрашиваем из БД сущность Article. Статья должна быть отображена вместе с комментариями. OSIV (Open session in View) позволяет при рендеринге HTML просто вызвать метод сущности getComments(), и комментарии будут загружены отдельным запросом. При отключенном режиме OSIV мы получим LazyInitializationException, так как сессия уже закрыта, и сущность Article больше не управляется Hibernate.
Плюсы:
- Обратная совместимость;
- Если отключить OSIV, новичкам может быть непонятно, почему не работает такая интуитивно ожидаемая вещь, как получение коллекции связанных элементов при обращении к методу сущности. Вместо этого пользователь получит LazyInitializationException, это замедлит его путь к работающему приложению;
- OSIV позволяет увеличить простоту кода, удобство и скорость разработки.
Минусы:
- Запросы к БД без транзакции работают в режиме авто-коммита, сильно ее нагружая;
- Долгие соединения с БД опять же увеличивают нагрузку на нее и уменьшают пропускную способность.
- https://spring-projects.ru/guides/lessons/lesson-2/
- https://habr.com/ru/articles/222579/
- https://github.com/Shell26/Java-Developer/blob/master/spring.md#%D0%9E%D1%81%D0%BE%D0%B1%D0%B5%D0%BD%D0%BD%D0%BE%D1%81%D1%82%D0%B8-%D0%B8-%D0%BF%D1%80%D0%B5%D0%B8%D0%BC%D1%83%D1%89%D0%B5%D1%81%D1%82%D0%B2%D0%B0-spring-framework
- https://javarush.com/quests/lectures/questspring.level06.lecture22
- https://www.baeldung.com/hibernate-identifiers
- https://javarush.com/quests/lectures/questhibernate.level13.lecture02
- https://habr.com/ru/articles/674882/
- https://medium.com/@kirill.sereda/%D1%82%D1%80%D0%B0%D0%BD%D0%B7%D0%B0%D0%BA%D1%86%D0%B8%D0%B8-%D0%B2-spring-framework-a7ec509df6d2
- https://habr.com/ru/companies/otus/articles/764244/
- https://habr.com/ru/companies/jugru/articles/218203/
- https://habr.com/ru/companies/otus/articles/529692/