Описание процесса разработки - d-01/graduate-2021-dec GitHub Wiki
Теория
В первую очередь были изучены теоретические материалы (ссылки на конспект):
- Основные и смежные понятия
- Существующие способы классификации эмоций
- Обзор существующих датасетов для распознавания эмоций
- Существующие проекты моделей для распознавания эмоций
Обучение модели для распознавания эмоций
Этап 1. Прототип
Задача: быстро создать прототип, чтобы получить базовую точность (точка отсчета), используя простейший пайплайн и простейшую сверточную сеть. В качестве пайплайна использован tf.data.Dataset, потому что файловая структура предоставленного датасета позволяет создать пайплайн одной командой tf.keras.utils.image_dataset_from_directory(), а для нейросети использована архитектура с тремя сверточными слоями из тюториала с сайта tensorflow.org и обучена в течении 20 минут, результат 0.332000 (public), что выше оценки 0.298800 требуемой для зачета.
Архитектура:
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(9)
])
- Layers:
3*conv32 + 1*fc128 + fc9 - Input: 45k images 128x128x1
- Output: 9 classes
- Parameters: 822,921
- Training:
- 40 epochs
- 25 min
- Test accuracy: 0.33400 / 0.33480 (private / public)
Следующая цель: повысить точность (private score) > 0.4.
Этап 2. Быстрый пайплайн для данных
Решено отказаться от использования tf.data.Dataset в качестве пайплайна для входных данных, т.к. размер датасета позволяет полностью загрузить его в память в виде numpy массива, что многократно упрощает работу с данными и ускоряет процесс обучения.
Этап 3. Изменение архитектуры сверточной сети
Новая модель:
- Сверточная нейросеть с более сложной архитектурой на базе MobileNet (0.25M параметров), время обучения 20 минут, точность = 0.37600
Архитектура:
def create_mobile_net(n_classes=9):
from tensorflow.keras import layers
input_shape = (128, 128)
mobilenet_input_shape = (128, 128, 3)
i = tf.keras.layers.Input(input_shape, dtype = tf.uint8)
x = tf.expand_dims(i, axis=-1)
x = tf.image.grayscale_to_rgb(x)
x = tf.cast(x, tf.float32)
x = tf.keras.applications.mobilenet.preprocess_input(x)
core = tf.keras.applications.MobileNet(mobilenet_input_shape,
alpha=0.25, include_top=False)
core.trainable = False
x = core(x)
x = layers.Flatten()(x)
x = layers.Dense(n_classes, activation=None)(x)
model = tf.keras.Model(inputs=[i], outputs=[x])
return model # Parameters #: 255417
- Parameters: 255,417
- Input: 40k images 128x128, gray
- Output: 9 classes
- Training:
- Pretrained weights: ImageNet
- LR: 1e-4
- Epochs: 20
- Time: 20 min
- Test accuracy: 0.37600 / 0.37160 (private / public)
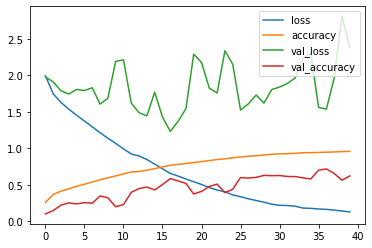
Training progress:
- Переобучение после 5-й эпохи.
Для дальнейшего увеличения точности необходимо решить проблему переобучения с помощью аугментации.
Этап 4. Аугментация
Рассмотрены два варианта:
- Аугментация на CPU, встроенная в пайплайн
tf.data.Dataset - Аугментация на GPU, встроенная в модель (единый вычислительный граф)
По результатам тестов на производительность была выбрана аугментация на GPU и разработан кастомный аугментирующий слой (tf.keras.layer).
- Добавлена аугментация (1 трансформация: hirizontal flip), архитектура та же, обучение 20 минут, точность = 0.42040
- Добавлена аугментация (7 трансформаций), обучение 2ч50м, точность = 0.464400
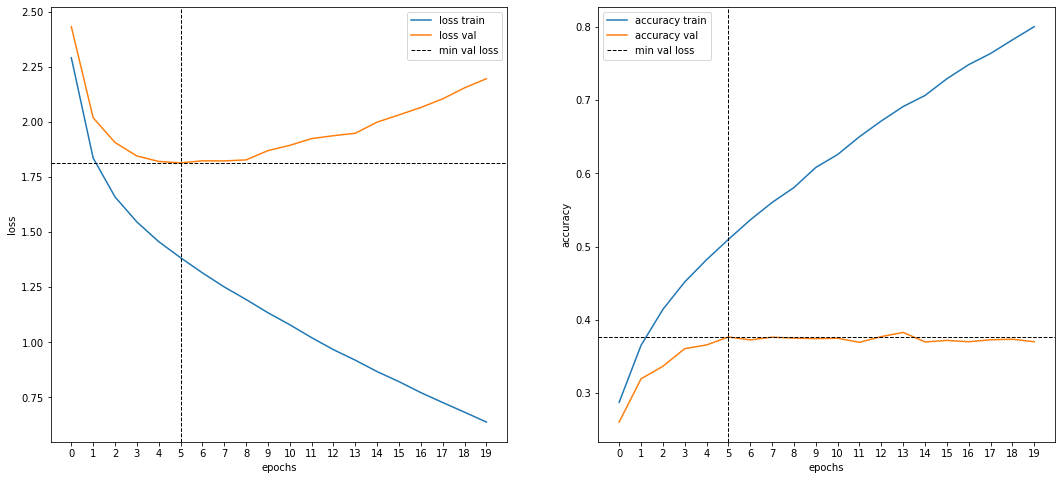
Модель со встроенной аугментацией (1)
Архитектура такая же как на этапе 3 + аугментирующий слой (горизонтальный флип).
- Parameters: 255,417
- Input: 40k images 128x128, gray, augmented (horizontal flip)
- Output: 9 classes
- Training:
- Pretrained weights: ImageNet
- LR: 1e-4
- Epochs: 20
- Time: 20 min
- Test accuracy: 0.42040 / 0.40920 (private / public)
- Переобучение после 11-й эпохи.
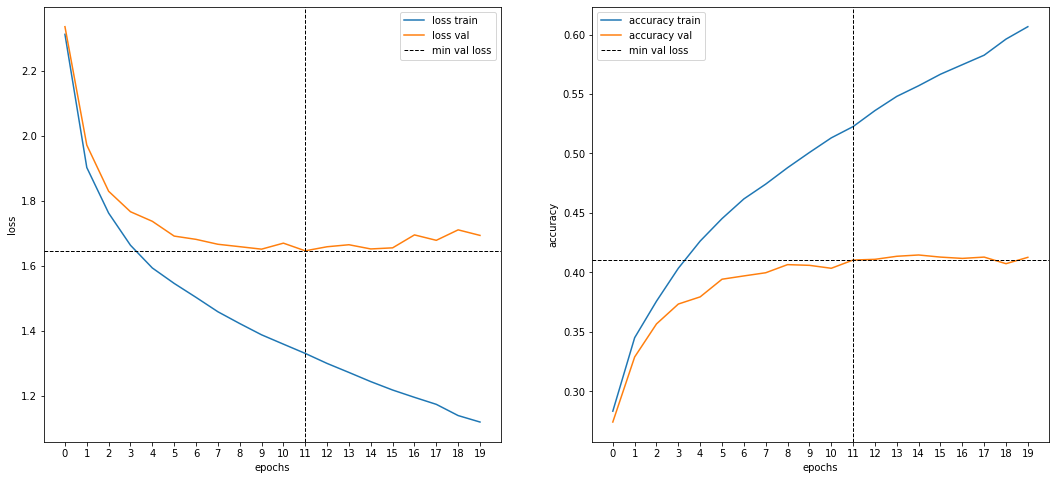
Модель со встроенной аугментацией (7)
Аугментация с помощью 7 трансформаций.
-
Parameters: 255,417
-
Input: 40k images 128x128, gray, augmented (7 methods)
-
7 augmentation transformations:
tf.image.random_contrast(inputs, .2, 2) tf.image.random_brightness(inputs, .1) tf.keras.layers.RandomRotation(.05, fill_mode='nearest') tf.keras.layers.RandomZoom(.2, fill_mode='nearest') tf.keras.layers.RandomTranslation(0.1, 0.1, fill_mode='nearest') tf.keras.layers.RandomFlip('horizontal') RandomJpegQuality(30, 100) # custom
-
-
Output: 9 classes
-
Training:
- Pretrained weights: ImageNet
- LR: 1e-4
- Epochs: 40
- Time: 2h40m
- Test accuracy: 0.46080 / 0.45840 (private / public)
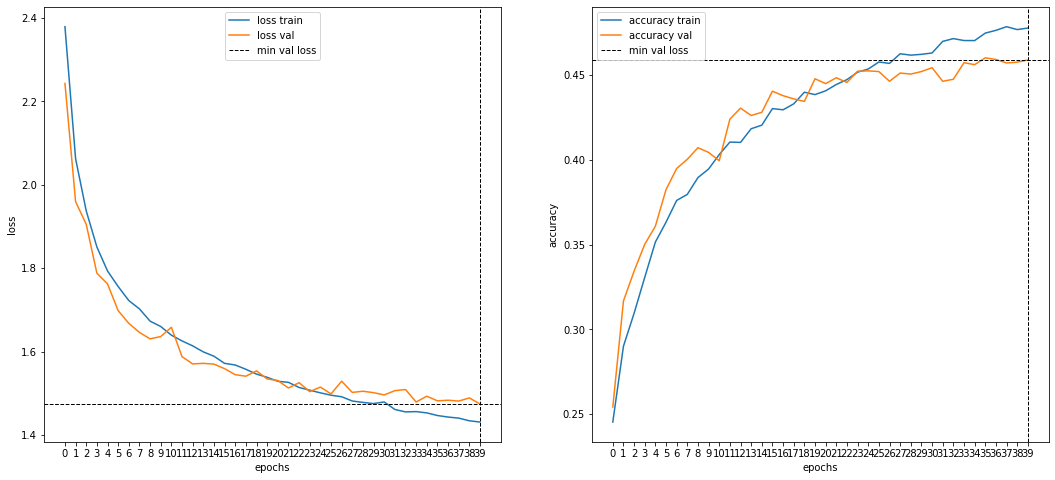
Дальнейшее развитие
Для дальнейшего развития можно работать в сторону повышения качества распознавания, увеличения точности классификатора эмоций.
- Модифицировать датасет:
- Больше данных -- добавить данные из других датасетов (например AffectNet).
- Провести чистку данных: с помощью детектора лиц найти и удалить изображения, где нет лиц.
- Добавить класс
non_faceс изображениями без лиц.
- Увеличить количество методов аугментации, чтобы сделать модель менее чувствительной к качеству изображений:
- Добавить артефакты растяжения изображения разными алгоритмами.
- Добавить искажение пропорций (aspect ratio), растяжение-сжатие по одной оси.
- Добавить искажения специфичные для фотографий: блики, fisheye.
- Препроцессинг входных изображений:
- Применять face alignment с помощью 5-point landmark детектора, чтобы компенсировать разные положение, масштаб и наклон лиц на изображениях.
- С помощью 68-point landmark детектора отделить лица от бэкграунда, что может повысить точность распознавания за счет удаления несущественных деталей с изображения (шум).
- Модифицировать архитектуру модели:
- Протестировать более свежие CNN архитектуры (MobileNet-v3, EfficientNet).
- Увеличить размер модели (увеличить параметр
MobileNet(alpha=1)).
- Усовершенствовать процедуру обучения:
- Добавить чекпоинты.
- Добавить мониторинг.
- Использовать learning rate scheduler.
Обучение модели для valence-arousal разложения
Датасет со значениями valence и arousal меток был получен из датасета для классификации эмоций с помощью системы координат:
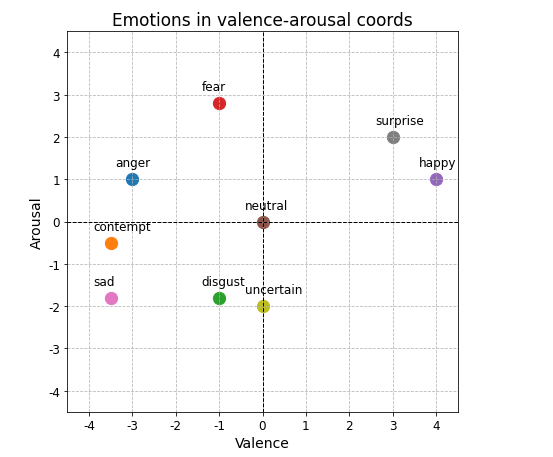
emot_valence_arousal = dict(
anger =(-3.0, 1.0),
contempt =(-3.5, -0.5),
disgust =(-1.0, -1.8),
fear =(-1.0, 2.8),
happy =( 4.0, 1.0),
neutral =( 0.0, 0.0),
sad =(-3.5, -1.8),
surprise =( 3.0, 2.0),
uncertain =( 0.0, -2.0),
)
Кроме того к каждому значению было добавлено случайное смещение (шум) выбранное из равномерного распределения в промежутке [-0.4, 0.4].
Для valence-arousal (приятный-напряженный) предсказания использовались две отдельные модели, полученные на базе классификационной модели для предсказания выражения лица.
У классификационной модели выходной слой был заменен на слой с одним нейроном + выполнена стандартная процедура дообучения (разморозка сверточных слоев и обучение на пониженном LR).
Лосс функция:
- MSE
Метрики:
- RMSE
- SAGR
Sign Agreement Metric (SAGR) -- shows the fraction of cases where the model predicts the right "direction" of emotion, i.e. positive value for pleasant/tense, negative value for unpleasant/calm.
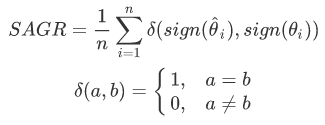
Valence model training:
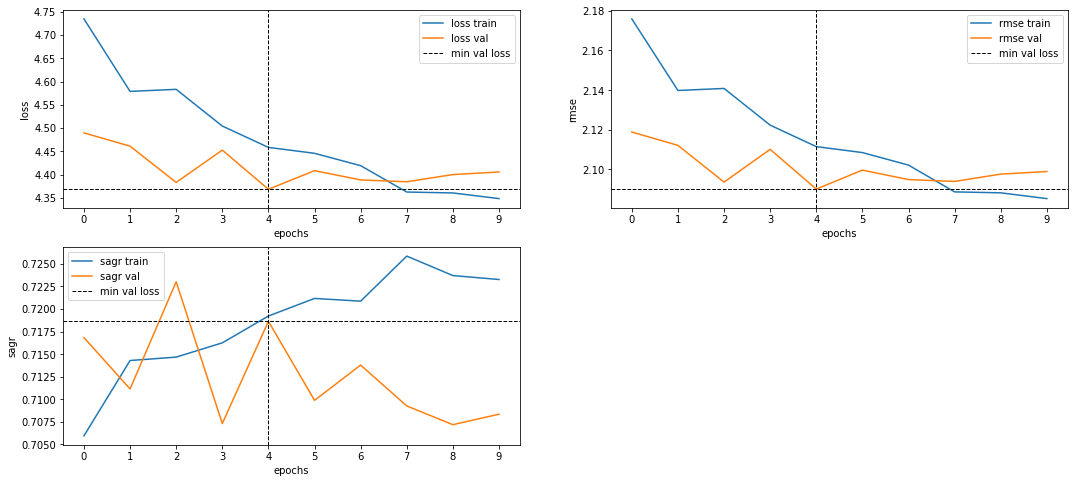
- Training time: 50m
- SAGR ~ 0.7186 (т.е. в 72% модель верно предсказывает -- лицо выражает приятную или неприятную эмоцию).
Arousal model training:
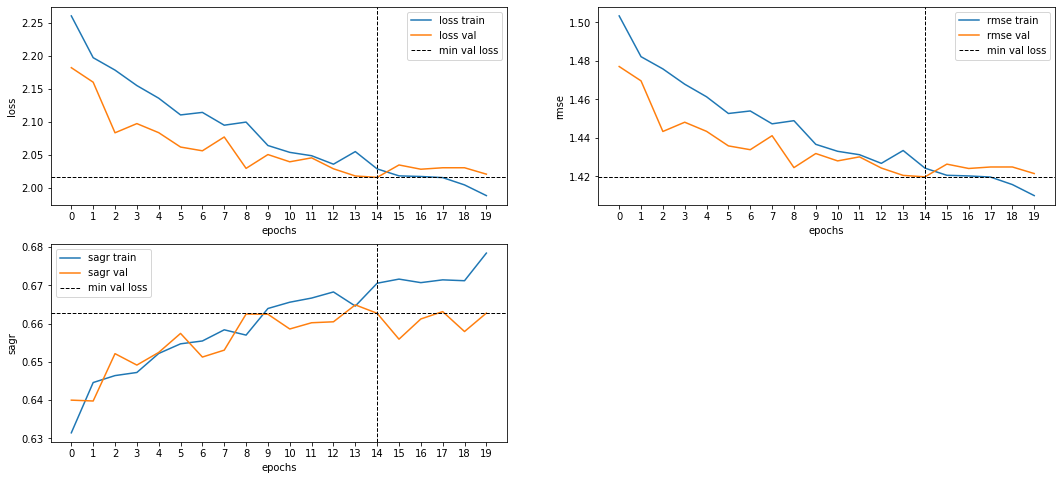
- Training time: 1h40m
- SAGR ~ 0.6627 (т.е. в 66% модель верно предсказывает -- выражение лица напряженное или расслабленное).
Демонстрация и тестирование производительности: colab.
Проверка точности с помощью обратного преобразования
Для проверки точности также было выполнено обратное преобразование, VA → emotion, по минимальному евклидову расстоянию до одного из центров (anger, contempt, disgust, etc.).
- kaggle score (private/public): 0.30080 / 0.29759
- Функция преобразования и генератор файла submisstion_va.csv: colab
Распознавание эмоций на изображении
Распознавание эмоций на произвольном (не подготовленном) изображении состоит из нескольких этапов:
- Сделать кроп -- вырезать из изображения область, где находится лицо. Для обнаружения области с лицом применяется детектор лиц.
- Получить название эмоции, передав кроп в модель распознавания эмоций.
- Нарисовать аннотацию.
Распознавание эмоций на видео-потоке
В качестве видео-потока может выступать как видео-файл, так и поток (stream) с веб-камеры.
Распознавание эмоций в реальном времени на видео состоит из последовательного распознавания эмоций на отдельных кадрах, но для аннотации используется оверлей -- полупрозрачное изображение с рамкой, выводимое поверх видео.
Выбор детектора лиц
Все детекторы тестируются на одном и том же наборе изображений, где на каждом тестовом изображении присутствует одно лицо крупным планом по центру.
Все тесты выполнены в среде Google Colab.
Скорость
| Backend | FPS (CPU) | ms/img (CPU) | FPS (GPU) | ms/img (GPU) |
|---|---|---|---|---|
| opencv | 59 | 17 | 62 | 16 |
| ssd | 10 | 102 | 10 | 97 |
| dlib (deepface) | 48 | 21 | 48 | 21 |
| mtcnn | 2.5 | 388 | 2.5 | 391 |
| retinaface | - | - | 4.1 | 242 |
| dlib (hog) | 54.5 | 18 | 53.6 | 19 |
| dlib (cnn) | 4.2 | 238 | 74.2 | 13 |
- dlib (deepface) -- один из бэкэндов библиотеки deepface использует dlib HOG detector.
- Из результатов видно, что mtcnn не использует GPU для ускорения инференса.
- dlib (hog) -- функция
dlib.get_frontal_face_detector(). - dlib (cnn) -- функция
dlib.cnn_face_detection_model_v1("mmod_human_face_detector.dat").
Точность
Число обнаруженных лиц из 100 фотографий.
Co-occurance matrix:
| ssd | retinaface | opencv | dlib (hog) | mtcnn | dlib (cnn) | |
|---|---|---|---|---|---|---|
| ssd | 70 | 64 | 64 | 69 | 69 | 70 |
| retinaface | 64 | 70 | 62 | 69 | 70 | 70 |
| opencv | 64 | 62 | 90 | 89 | 88 | 90 |
| dlib (hog) | 69 | 69 | 89 | 96 | 94 | 96 |
| mtcnn | 69 | 70 | 88 | 94 | 97 | 97 |
| dlib (cnn) | 70 | 70 | 90 | 96 | 97 | 99 |
- На диагонали -- число детекций из 100 изображений (напр. mtcnn обнаружил 97 лиц из 100).
- На пересечении -- число изображений, где оба алгоритма обнаружили лицо.
- На текущий момент (2021-11-06) реализация RetinaFace имеет проблемы с обнаружением:
Выводы
- Наиболее точный: dlib (cnn).
- Наиболее быстрый на CPU: Haar Cascade (opencv), на GPU: dlib (cnn)
- Оптимальный выбор:
- Для CPU -- dlib (hog):
- По точности 3-й после dlib (cnn) и mtcnn.
- По скорости на CPU 2-й, после haar cascade (opencv).
- Для GPU -- dlib (cnn):
- По точности 1-й.
- По скорости на GPU 1-й.
- Для CPU -- dlib (hog):
Демо. Веб-камера
Вывод потока с веб-камеры в Google Colab + распознавание эмоций + оверлей с аннотацией.
Демо. Видео-файл
В качестве источника видео-потока используется mp4 файл.
- Если не указать путь к файлу (
None), то используется поток с веб-камеры.
По окончании видео выводится график эмоций на временной шкале:
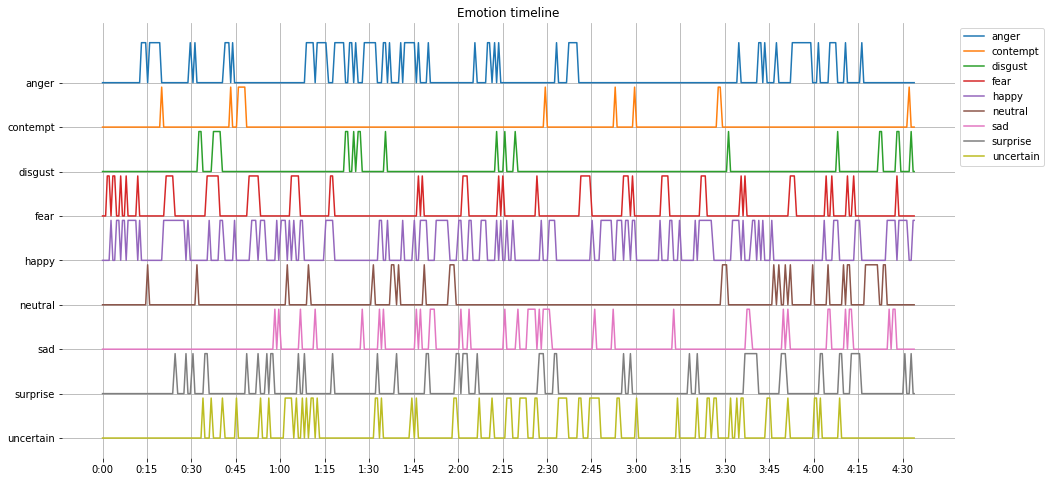
С помощью графика surprise можно выбрать кадры, на которых запечатлены моменты вызвавшие наибольшее удивление: