Лекция 07 - chrislvt/OS GitHub Wiki
Основной задачей операционной системы является управление памятью, но такое управление невозможно без аппаратной поддержки.Очевидно, что схемы, которые мы с вами рассмотрели при управлении памятью страницами по запросу, являются аппаратными.Это аппаратная реализация. Это невозможно осуществлять программно, так как тогда такое страничное преобразование съело бы всё процессорное время. Очевидно, что должна быть аппаратная поддержка. Схемы эти реализуются аппаратно. Но безусловно задачи выделения памяти, определения какому процессу сколько памяти необходимо выделить выполняются программно. Программно же выполняются задачи определения страницы для вытеснения. Мы с вами рассмотрели алгоритмы вытеснения страниц. Мы с вами рассмотрели и очень близкий к реальной реализации алгоритм аппроксимации LRU с двумя флагами, который( назвали NUR (Not Used Recently) не используемая в последнее время. Введение флага который время от времени сбрасывается является очень эффективным способом определения возможности замещения страницы и используется в современных системах.(Мы увидим это на семинаре)
70-е годы прошлого века начиная с середины 60-х годов были годами интенсивного развития операционных систем и железа. Безусловно эти вещи должны развиваться в тандеме, совместно. Именно тогда появилась идея виртуальной памяти и именно тогда обсуждались все эти особенности и в частности встал вопрос о размере страницы. Размер страницы не является праздным рассуждением. Размер страницы с одной стороны влияет на размер таблиц страниц. Чем меньше размер страницы, тем больше размер таблицы страниц(при том же размере адресного пространства процессора). А мы с вами понимаем, что таблицы страниц являются системными таблицами, должны находиться в области данных ядра системы(в дефицитнейшей области памяти), то есть уменьшение размера страницы должно иметь свои ограничения. Почему же надо уменьшать размер страницы? Из тех соображений, что никогда все команды на странице не выполняются полностью, то есть на одной страницу все команды не выполняются. Чем меньше страницы, тем больший процент команд на этой странице будет выполнен.
Все эти рассуждения о размере страницы естественно подвергались исследованиям.(Вспоминает что она показывала результат исследования снимка памяти, который показывает, что процесс никогда не обращается ко всем своим страницам. Именно это позволяет реализовать схемы управления виртуальной памятью.)
Рассмотрим несколько зависимостей.


График отражает влияние изменения размера страницы при одном и том же объёме памяти на число страничных прерываний.
Это коррелирует с тем рассуждением, которое было только что приведено в пользу маленьких страниц и в пользу больших страниц. Маленькие страницы хороши тем, что на них выполняется больший процент команд, а большие страницы хороши тем, что они уменьшают размеры таблиц страниц, но при этом естественно процент команд которые будут выполнены на таких страницах будет меньше. То есть мы в памяти держим страницу, часть которой не используем. Чем больше страница, тем большая часть этой страницы не используется, чем меньше страница, тем она больше используется.
Мы видим, что число прерываний растёт с ростом размера страницы. Это связано с тем, что с ростом размера страницы в память попадает большее число команд данных, к которым не производится обращений. Вы видите дальше идёт пунктир - число страничных прерываний уменьшается потому что размер страницы становится соизмерим с объёмом физической памяти и получается что в памяти находится практически вся программа и число страничных прерываний будет резко уменьшаться. В процессе практической деятельности получилось что размер страницы в разных системах варьировался от 2КБ до 4КБ. При этом надо смотреть что бралось за единицу памяти (байт или слово или двойное слово) то есть надо внимательно смотреть, но это рассуждение прошлого века. Именно тогда была актуальна проблема. Эта же проблема характерна для настоящего времени. Наверняка вы слышали, что процессоры Intel поддерживают страницу размеров 4КБ, но эти же процессоры поддерживают и большие страницы. Это связано с какими-то базами данных, когда действительно нужно иметь в памяти сразу много данных относящихся к одной позиции. То есть эти процессоры поддерживают как страницы 4КБ, так и страницы большего размера. Это отражается в документации.
Рабочее множество
Проблема страничных прерываний является очень важной серьёзной проблемой в системе. Суммируя всё сказанное, все алгоритмы, можно себе представить, что вот такое вытеснение, замещение страниц выполняется постоянно, но оно выполняется на основе страничных прерываний. То есть обслуживание страничных прерываний является очень важной задачей и в то же время проблемой в системе. Чем меньше страничных прерываний происходит в системе, тем эффективнее выполняются программы. Для решения этой проблемы была сформулирована в 1968 году Деннингом идея рабочего множества, а именно зависимость страничных прерываний от объёма памяти. Эта зависимость стала рассматриваться как обобщённая мера страничного поведения программы.
Мы видели с вами на примере этого уникального эксперимента(результат исследования снимка памяти) кроме того, что на этом снимке памяти было видно, что процесс никогда не обращается ко всем своим страницам одновременно, так же было видно, что в разное время процесс обращается к разному количеству своих страниц. То есть обращение процесса к страницам не является стабильным и равномерным. В результате в качестве локальной меры производительности Деннинг предложил взять число страниц к которым обращается процесс за интервал времени dt и это количество страниц он предложил назвать working set(рабочее множество).


Размер рабочего множества является монотонной функцией от dt, то есть при увеличении dt, число страниц к которым обращается процесс будет стремиться к некоторому пределу, который определяет количество страниц, необходимых процессу для эффективного выполнения. Другими словами процесс будет выполняться без страничных прерываний некоторое время, длительность которого определить невозможно(это случайная величина), если ему удастся загрузить в память все нужные страницы в текущий момент времени. Собственно это и есть рабочее множество. При этом этот процесс абсолютно случайный, ни предсказать страницы к которым процесс будет обращаться в текущий в следующий моменты времени невозможно, ни определить длительность этого интервала - это всё случайные вещи. Но все исследования показывают что именно так работают наши программы, то есть каждый раз, когда процессу удаётся загрузить в память все нужные ему страницы в текущий момент времени, то какой-то интервал времени процесс будет выполняться без страничных прерываний, значит эффективно.
Если процессу не удаётся загрузить в память всё его рабочее множество, то возникает явление, получившее специальное название trashing, а именно подкачка одних и тех же страниц. Причём за время своей жизни процесс меняет рабочие множества.

(ст + нов на рисунке = старое + новое)

В начальный момент времени мы с вами понимаем, что когда мы запускаем программу на выполнение, ей выделяется только минимальное количество страниц (М.Руссинович, Д.Соломон пишут что это 3 страницы) и в начальный момент выполнения процесса процесс интенсивно подкачивает в память нужные ему страницы. Сделать это можно только через страничные прерывания. В какой-то момент времени в памяти оказываются все страницы, которые ему необходимы и это будет первое рабочее множество. Какой-то интервал времени процесс будет выполняться без страничных прерываний, затем ему нужно перейти на другое рабочее множество. Он начинает подкачивать эти страницы пока не загрузит в память всё необходимое ему рабочее множество (второе) и тд. Вот такой выем, такой горб связан с тем, что в памяти в какой-то момент времени ещё находятся страницы из старого рабочего множества, но уже загружены страницы из нового рабочего множества. Очевидно, что введены были соответствующие понятия, например hit rate. Hit rate - доля обращений, не потребовавших смены страницы.
Рассмотрим ещё один интересный график. График зависимости длительности времени прерывания (период прерывания).


Период прерывания - это интервал между обращениями к отсутствующей странице.
Мы видим что происходит сначала рост, а потом происходит перегиб. Перегиб на графике связан с тем, что в какой-то момент времени в памяти окажется всё рабочее множество.
Глобальное локальное замещение.
Как же управлять системой, пейджингом, с тем чтобы процессы могли выполняться эффективно, могли загружать в память всё своё рабочее множество? Очевидно, что это управление не выполняется вручную. Система должна выполнять это автоматически.
Существует два подхода:
- глобальное замещение страниц;
- локальное замещение страниц.
Глобальное замещение означает, что может быть вытеснена любая страница любого процесса для того чтобы процесс смог загрузить свою страницу в память.
Локальное замещение означает, что вытесняются только страницы данного процесса.
У Соломона Руссиновича в частности есть понятие рабочее множество. Но ведь сказать размер рабочего множества невозможно. Это невозможно просто в силу объективных обстоятельств. Программы у нас запускаются, они нами не изучены. Действительно могут быть системы в которых программы, которые выполняются в этой системе очень хорошо изучены. Обычно это касается систем очень важного назначения - систем реального времени. Там выполняемые процессы могут быть изучены досконально. Все их характеристики временные и тд. В системах общего назначения это невозможно. Мы с вами имеем дело в системами общего назначения. Windows управляет системами общего назначения. Поэтому никакие предсказания здесь невозможны. Но они ввели понятие рабочего множества.
На самом деле можно переиначить название рабочее множество как квота. То есть каждому процессу выделяют квоту, например 10 страниц. Любая система контролирует число страничных прерываний. Она должна это контролировать, потому что число страничных прерываний влияет на эффективность работы системы. Если у какого-то процесса резко возрастает число страничных прерываний это означает, что квота, выделенная процессу, мала. Ему надо выделить дополнительную квоту, например плюс три страницы. И опять же наблюдать за числом страничных прерываний. Потом эта квота может быть снижена через некоторое время. Таким образом в системе возможно регулирование числа страничных прерываний.
При страничном управлении памятью существует так называемая скрытая фрагментация. Последняя страница никогда не бывает заполнена полностью. Но при наших огромных объёмах программ это уже смешно. Но это всё рассуждения прошлого века.
Управление памятью сегментами по запросам.
Страницы являются единицей физического деления памяти. Размер страницы определён в системе.
Сегменты являются единицей логического деления памяти. Размер сегмента определяется объёмом программного кода. Очевидно, что у сегмента не может быть безграничного размера, размер сегмента ограничен аппаратными соображениями.
Сегмент вроде как является более логичным для реализации в системе, поскольку действительно мы выполняем какие-то программы определённого размера и безусловно сама идея буквально прям вот находится на поверхности. При этом виртуальный адрес делится на две части: сегмент, смещение. Смещение не может быть безгарнично большим. Размер смещения в системе ограничен какими-то соображениями. В частности мы с вами видели на примере процессоров Intel, поскольку мы с вами уже выполнили лр перевода компьютера из реального режима в защищённый режим и обратно. Там как раз используется управление памятью сегмантами, но мы не в полной мере насладились конечно этим процессом, мы с вами рассматривали только таблицу глобальных дескрипторов, которая описывает сегменты физической памяти, но представление можем себе создать. Соответсвтенно дескриптор сегмента мы с вами видели.


В процессоре должен быть регистр начального адреса таблицы сегментов.Таблица сегментов содержит дескрипторы сегментов адресного пространства процесса.Но для того, чтобы контролировать процесс, в дескрипторе сегмента обязательно должен быть лимит(lim) - размер сегмента. Соответственно производится контроль обращения процесса к своему сегменту и лимит как раз используется для такого контроля. Таким образом и осуществляется защита адресных пространств процессов. То есть система контролирует выход процесса за его адресное пространство. Это самый простой способ контроля. Это нормальное инженерное решение. Там где начинают выдумывать непонятно что, как правило ничего не получается. Инженерные решения это как правило простые решения. Ведь системе проще всего контролировать выход процесса за его адресное пространство. Но еще говорят по другому. Ни один процесс не может обратиться в адресное пространство другого процесса. Но контроль осуществляется именно таким образом.
Можете спросить а как же осуществляется контроль при страничном преобразовании? Процесс не может обратиться к страницам, которые не описаны в его таблицах страниц. Это просто невозможно. Но здесь конечно имеется некий вариант, потому что сегмент - это единица логического деления памяти.
Как уже было сказано с каждым сегментов связан дескриптор. Этот дескриптор содержит адрес сегмента, его размер, соответственно общее название того что мы видели в сегментах с которыми работали это права доступа. То что у Рудакова Финогенова записывается как можно читать, можно писать, можно выполнять это права доступа. У нас всего 3 типа(read, write, execute). Кроме того вы видели дополнительные флаги, которые управляют своппингом. Если мы говорим о страницах, то принято говорить о пейджинге, если мы говорим о сегментах, то принято говорить о свопе.
Реализация сегментированной адресации зависит от организации таблиц дескрипторов сегментов. Существует 3 типа организации таких таблиц.
1 тип. Единая таблица.
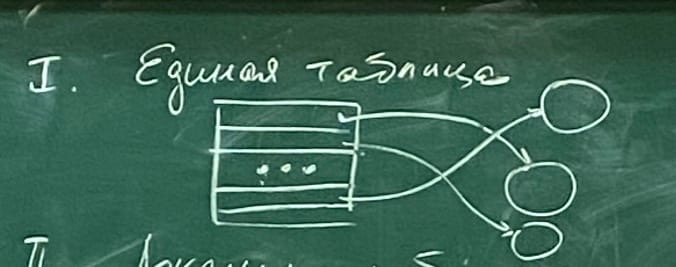
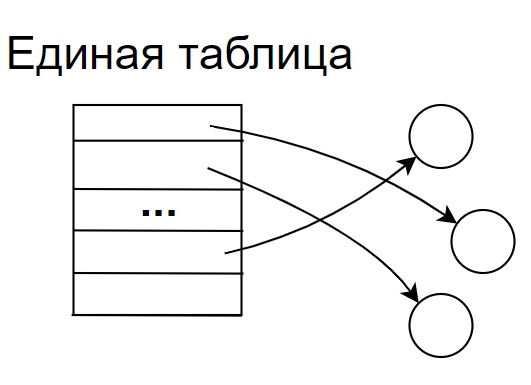
Одна единая таблица которая содержит все дескрипторы сегментов и выполняемых программ, при этом у каждого такого сегмента в системе существует одно единственное имя, которое и является идентификатором дескриптора таблицы. В этом случае такой дескриптор должен содержать список прав доступа для всех процесов которые могут использовать данный сегмент. Такой список прав доступа может быть очень большим. Понятно, что такая система не является гибкой, все процессы обращаются к сегменту по одному единственному его имени.
2 тип. Локальная таблица.


Локальные таблицы, то есть каждый процесс (его адресное пространство разбито на сегменты, соответсвтенно каждое такое локальное адресное пространство имеет свою локальную таблицу дескрипторов. Для того чтобы другие процессы могли обратиться к этому же сегменту этот сегмент должен иметь дескриптор в соответствующих локальный таблицах. То есть для того чтобы процесс смог обращаться к сегментам других програм, эти сегменты должны быть описаны в их локальных таблицах, но при этом получается, что один сегмент в системе может иметь несколько разных имён. Это безусловно усложняет работу с сегментами в системе.
3 тип. Локальная таблица + глобальная таблица.


Локальные таблицы и глобальная таблица. При этом локальные таблицы описывают адресное пространство процессов, но дескрипторы этих локальных таблиц ссылаются на дескрипторы глобальной таблицы. В данной схеме это именно так.
Так ли это в Intel? Мы рассматривали GDT, LDT, так ли там?
Интерес к сегментации обусловлен тем, что сегмент является логической единицей деления памяти. Он определяется соотвестствующей программой т.е. программа занимает определённый сегмент т.е. связана с логикой программы в отличие от страниц. Но если посмотреть на подкачку сегментов, то во-первых мы уже рассматривали управление памятью разделами, перемещаемыми разделами - всё это справедливо для сегментации. Так как сегменты определяются размером программного кода, то они имеют самые разные размеры.Если мы выполняем своппинг, то выгрузив один сегмент в освободившееся адресное пространство нужно загрузить новый сегмент. При загрузке останется адресное пространство в которое мы не сможем что-то загрузить. При этом этот своппинг выполняется постоянно. Понятно что у нас перемещаемые сегменты, но всёравно любое перемещение приводит к соответствующим затратам.
Стратегии выбора сегмента
Стратегии выбора освободившегося раздела для загрузки сегмента будут такие же как в старых схемах(предыдущих). Стратегий было 3: первый подходящий, самый тесный, самый широкий. Эти стратегии и здесь будут работать. Но при этом так как это виртуальная память, то остаются задачи вытеснения сегментов. Если вся память распределена и мы не смогли найти разделы нужного размера, то надо выгрузить какие-то сегменты. Выгрузка сегментов выполняется по тем же соображениям, по которым выполняется выгрузка страниц. Безусловно здесь так же работает тот же признак. Самым лучшим является трудно осуществимый алгоритм LRU. Для загрузки новых сегментов необходимо выбирать сегменты для замещения, но может оказаться, что замещаемый сегмент имеет недостаточно большой размер для того чтобы в освободившуюся область мы могли загрузить большой сегмент. Вместо одного сегмента нам придётся выгрузить несколько. Это дополнительные накладные расходы. То есть проблема замещения сегментов значительно сложнее, чем замещения страниц, хотя все рассуждения остаются в силе.
Мысль разработчиков пришла к третьему способу - управление памятью сегментами, поделёнными на страницы, по запросу.


Смещение делится на два поля: страница и смещение (смещение в странице). Соответственно у нас будет столько таблиц страниц, сколько у нас сегментов. При такой организации размер сегмента должен быть кратен размеру страницы. Вроде бы мы совместили только достоинства двух методов управления виртуальной памятью: сегментацией и страничным управлением. Сегментно-страничное преобразование было реализовано в IBM370.
Рассмотрим особые случаи, которые возможны при таком управлении памятью.


Первый особый случай, который возможен(первая неудача) - особый случай при связывании. Речь идёт об отложенном связывании. Объемы программ увеличиваются, увеличиваются задачи которые решаются с помощью соответствующего программного обеспечения и соответственно прикладное ПО отвечает, как принято говорить у политиков, на вызовы времени. В частности таким ответом являются dl - динамически подгружаемые библиотеки. То есть они появились не просто так. Они подгружаются автоматически когда в них появляется необходимость. Вот оно вам отложенное связывание. (Имеется ввиду link). Этот особый случай конечно как-то обозначается, может быть установлен специальный бит(особый случай при связывании). Тогда возникает прерывание по особому случаю при связывании. В результате обработки этого прерывания нужно сегменту с символическим именем присваивается номер строки таблицы сегментов и заполняется дескриптор сегмента.
Второй особый случай - если установлен бит особый случай в сегменте. Это приводит к прерыванию по особому случаю в сегменте. При обработке этого прерывания для сегмента создаётся таблица страниц и карта файлов. При этом адрес таблицы страниц записывается в дескриптор сегмента.
Третий особый случай - установлен бит особый случай страницы. Это прерывание по особому случаю страницы - страница отсутствует в памяти.
В итоге обработки всех этих особых случаев будет сформирован линейный физический адрес. Очевидно что и в этой схеме возможно кеширование. Мы с вами рассматривали кеширование в страничном преобразовании. В системе MULTICS такой кеш TLB (Translation Lookaside Buffer). Такой кеш должен содержать адреса физических страниц к которым были последние обращения. Такой же кеш возможен и в этой схеме.
Самым простым если бегло смотреть все три способа управления виртуальной памятью (простым в плане замещения) является страничное преобразование при котором мы заменяем страницы на страницы. Но для страниц всегда было минусом коллективное использование программ. Понятно. что в системах многие пользователи заинтересованы в использовании одних и тех же программ. Создавать для каждого отдельную копию такой программы это крайне неэффективно. Кроме того отдельные процессы могут быть заинтересованы в использовании одних и тех же таблиц, одних и тех же наборов данных. Это всё относится к сфере коллективного использования. Очевидно, что сегмент являющийся единицей логического деления программ, позволяет разделить наши программы в простейшем случае на сегмент кода, сегмент данных, сегмент стека. Мы это можем увидеть в том же адресном пространстве Unix при желании. Но для того чтобы процесс мог обращаться к каким-то таблицам, каким-то наборам данных, понятно что эти наборы данных имеют какую-то логическую целостность, принадлежат какому-то большому массиву, какой-то большой таблице (это важное заключение которое надо довести до конца, но на сегодня мы с вами закончим)))))