Kubeflow 파이프 라인 개요 - chojy/Documents GitHub Wiki
Kubeflow 파이프 라인이란 무엇입니까?
Kubeflow Pipelines 플랫폼은 다음으로 구성됩니다.
-
실험, 작업 및 실행을 관리하고 추적하기위한 사용자 인터페이스 (UI).
-
다단계 ML 워크 플로를 예약하기위한 엔진입니다.
-
파이프 라인 및 구성 요소를 정의하고 조작하기위한 SDK입니다.
-
SDK를 사용하여 시스템과 상호 작용하기위한 노트북. 다음은 Kubeflow Pipelines의 목표입니다.
-
엔드 투 엔드 오케스트레이션 : 기계 학습 파이프 라인의 오케스트레이션을 활성화하고 단순화합니다.
-
쉬운 실험 : 다양한 아이디어와 기술을 쉽게 시도하고 다양한 시도 / 실험을 관리 할 수 있습니다.
-
간편한 재사용 : 매번 재 구축 할 필요없이 구성 요소와 파이프 라인을 재사용하여 엔드 투 엔드 솔루션을 신속하게 만들 수 있습니다.
Kubeflow Pipelines의 컨테이너 빌더는 현재 Google Cloud Platform (GCP)에 대한 사용자 인증 정보 만 준비합니다. 결과적으로 컨테이너 빌더는 Google Container Registry 만 지원합니다. 그러나 이미지를 가져 오기 위해 자격 증명을 올바르게 설정 한 경우 컨테이너 이미지를 다른 레지스트리에 저장할 수 있습니다.
파이프 라인이란?
파이프 라인 워크 플로우와 그들이 어떻게 그래프의 형태로 결합의 모든 구성 요소를 포함하는 ML 워크 플로우에 대한 설명입니다. 파이프 라인에는 파이프 라인을 실행하는 데 필요한 입력 (매개 변수)의 정의와 각 구성 요소의 입력 및 출력이 포함됩니다.
파이프 라인을 개발 한 후 Kubeflow Pipelines UI에서 업로드하고 공유 할 수 있습니다.
파이프 라인 구성 요소 A와 패키지 사용자 코드의 독립적 인 세트이다 도커 이미지 수행하는 파이프 라인의 하나의 단계. 예를 들어 구성 요소는 데이터 전처리, 데이터 변환, 모델 학습 등을 담당 할 수 있습니다.
파이프 라인의 예
아래 스크린 샷과 코드 xgboost-training-cm.py는 CSV 형식의 구조화 된 데이터를 사용하여 XGBoost 모델을 생성하는 파이프 라인을 보여줍니다 . GitHub 에서 파이프 라인에 대한 소스 코드 및 기타 정보를 볼 수 있습니다 .
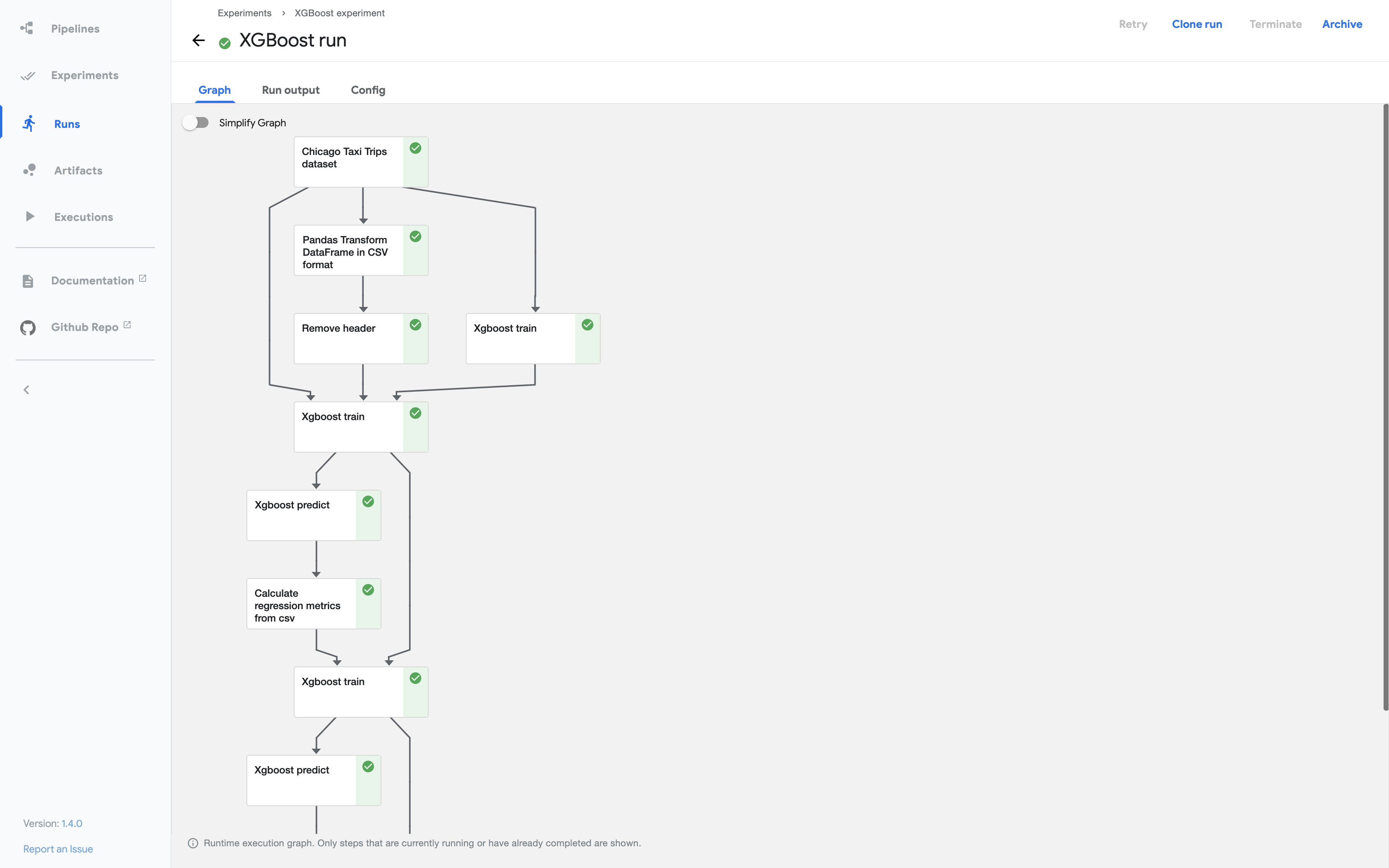
파이프 라인의 런타임 실행 그래프
아래 스크린 샷은 Kubeflow Pipelines UI에있는 예시 파이프 라인의 런타임 실행 그래프를 보여줍니다.
파이프 라인을 나타내는 Python 코드
다음은 xgboost-training-cm.py파이프 라인 을 정의하는 Python 코드에서 발췌 한 것 입니다. GitHub 에서 전체 코드를 볼 수 있습니다
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output='gs://your-gcs-bucket',
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
output_template = str(output) + '/' + dsl.RUN_ID_PLACEHOLDER + '/data'
# Current GCP pyspark/spark op do not provide outputs as return values, instead,
# we need to use strings to pass the uri around.
analyze_output = output_template
transform_output_train = os.path.join(output_template, 'train', 'part-*')
transform_output_eval = os.path.join(output_template, 'eval', 'part-*')
train_output = os.path.join(output_template, 'train_output')
predict_output = os.path.join(output_template, 'predict_output')
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
_analyze_op = dataproc_analyze_op(
project=project,
region=region,
cluster_name=cluster_name,
schema=schema,
train_data=train_data,
output=output_template
).after(_create_cluster_op).set_display_name('Analyzer')
_transform_op = dataproc_transform_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=train_data,
eval_data=eval_data,
target=target,
analysis=analyze_output,
output=output_template
).after(_analyze_op).set_display_name('Transformer')
_train_op = dataproc_train_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=transform_output_train,
eval_data=transform_output_eval,
target=target,
analysis=analyze_output,
workers=workers,
rounds=rounds,
output=train_output
).after(_transform_op).set_display_name('Trainer')
_predict_op = dataproc_predict_op(
project=project,
region=region,
cluster_name=cluster_name,
data=transform_output_eval,
model=train_output,
target=target,
analysis=analyze_output,
output=predict_output
).after(_train_op).set_display_name('Predictor')
_cm_op = confusion_matrix_op(
predictions=os.path.join(predict_output, 'part-*.csv'),
output_dir=output_template
).after(_predict_op)
_roc_op = roc_op(
predictions_dir=os.path.join(predict_output, 'part-*.csv'),
true_class=true_label,
true_score_column=true_label,
output_dir=output_template
).after(_predict_op)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))
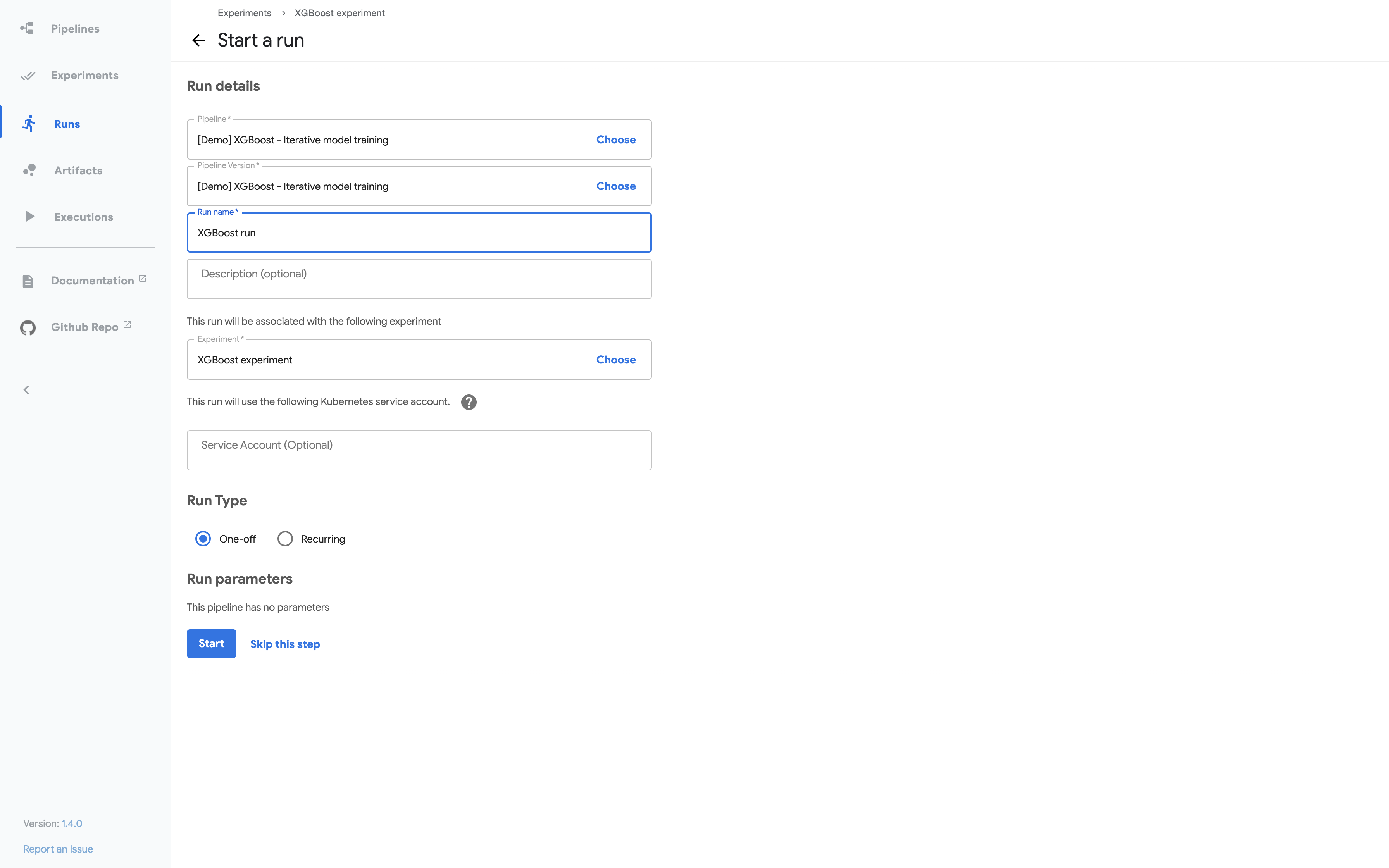
Kubeflow Pipelines UI의 파이프 라인 입력 데이터
아래의 부분 스크린 샷은 파이프 라인 실행을 시작하기위한 Kubeflow Pipelines UI를 보여줍니다. 코드의 파이프 라인 정의는 UI 양식에 표시되는 매개 변수를 결정합니다. 파이프 라인 정의는 매개 변수에 대한 기본값을 설정할 수도 있습니다.
파이프 라인의 출력 다음 스크린 샷은 Kubeflow Pipelines UI에 표시되는 파이프 라인 출력의 예를 보여줍니다.
예측 결과 :
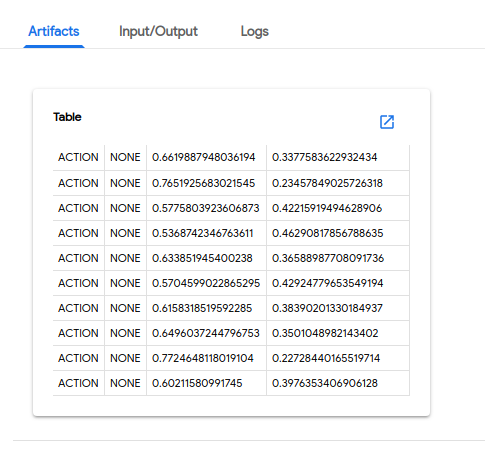
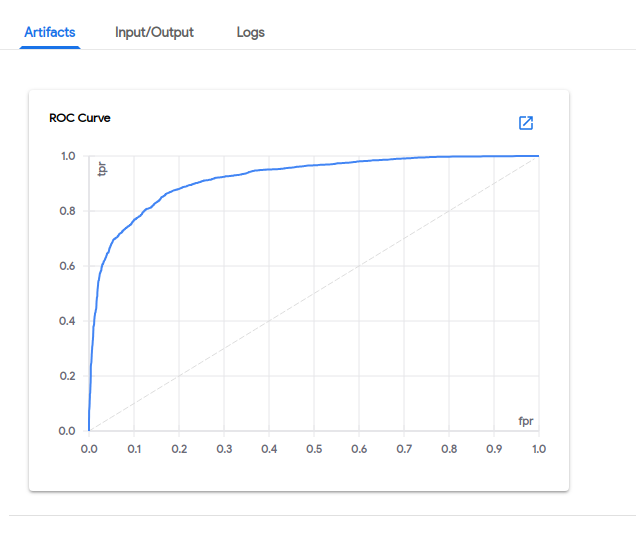
혼동 행렬 :

수신기 작동 특성 (ROC) 곡선 :
건축 개요
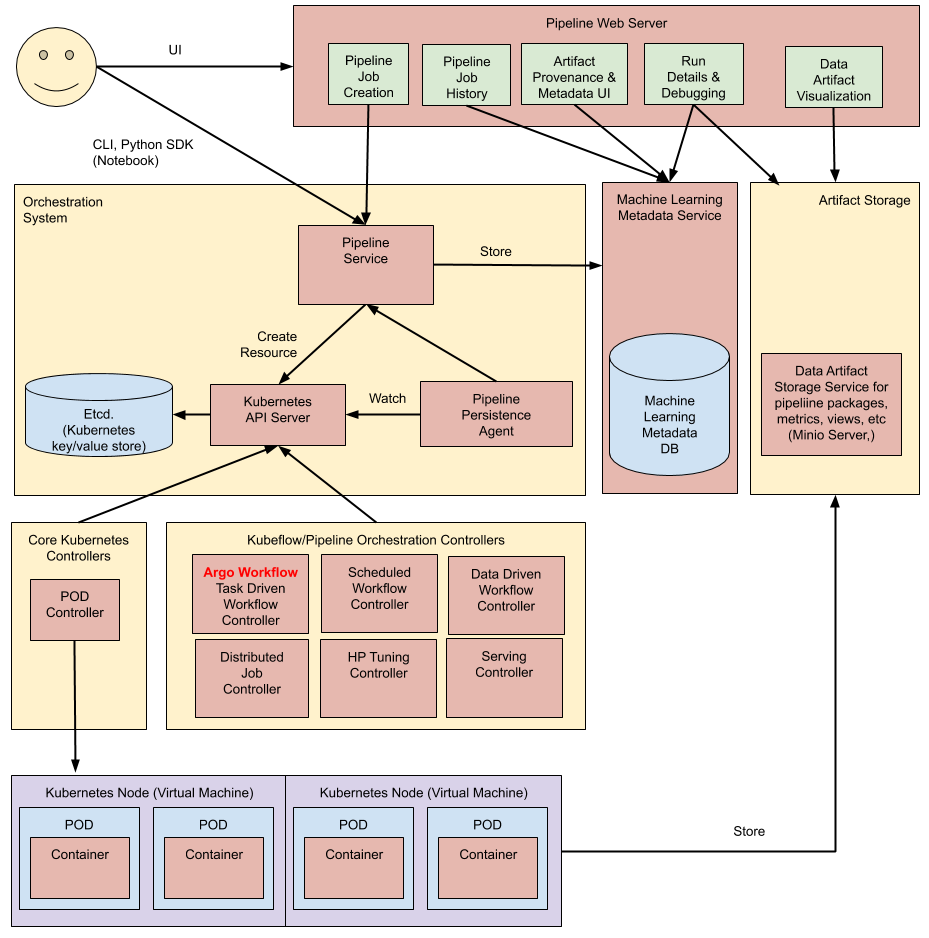
높은 수준에서 파이프 라인 실행은 다음과 같이 진행됩니다.
- Python SDK : Kubeflow Pipelines 도메인 별 언어 ( DSL )를 사용하여 구성 요소를 생성하거나 파이프 라인을 지정합니다 .
- DSL 컴파일러 : DSL 컴파일러 는 파이프 라인의 Python 코드를 정적 구성 (YAML)으로 변환합니다.
- 파이프 라인 서비스 : 파이프 라인 서비스를 호출하여 정적 구성에서 실행되는 파이프 라인을 만듭니다.
- Kubernetes 리소스 : 파이프 라인 서비스는 Kubernetes API 서버를 호출 하여 파이프 라인을 실행하는 데 필요한 Kubernetes 리소스 ( CRD )를 만듭니다 .
- 오케스트레이션 컨트롤러 : 일련의 오케스트레이션 컨트롤러가 파이프 라인을 완료하는 데 필요한 컨테이너를 실행합니다. 컨테이너는 가상 머신의 Kubernetes 포드 내에서 실행됩니다. 예제 컨트롤러는 작업 중심 워크 플로를 조정 하는 Argo Workflow 컨트롤러입니다.
- 아티팩트 저장소 : Pod는 두 가지 종류의 데이터를 저장합니다.
- 메타 데이터 : 실험, 작업, 파이프 라인 실행 및 단일 스칼라 측정 항목. 메트릭 데이터는 정렬 및 필터링을 위해 집계됩니다. Kubeflow Pipelines는 메타 데이터를 MySQL 데이터베이스에 저장합니다.
- 아티팩트 : 파이프 라인 패키지,보기 및 대규모 메트릭 (시계열). 대규모 지표를 사용하여 파이프 라인 실행을 디버그하거나 개별 실행의 성능을 조사합니다. Kubeflow Pipelines는 Minio 서버 또는 Cloud Storage 와 같은 아티팩트 저장소에 아티팩트를 저장 합니다 .
- MySQL 데이터베이스와 Minio 서버는 모두 Kubernetes PersistentVolume 하위 시스템에서 지원합니다.
- 지속성 에이전트 및 ML 메타 데이터 : 파이프 라인 지속성 에이전트는 파이프 라인 서비스에서 생성 된 Kubernetes 리소스를 감시하고 ML 메타 데이터 서비스에서 이러한 리소스의 상태를 유지합니다. Pipeline Persistence Agent는 실행 된 컨테이너 세트와 입력 및 출력을 기록합니다. 입력 / 출력은 컨테이너 매개 변수 또는 데이터 아티팩트 URI로 구성됩니다.
- 파이프 라인 웹 서버 : 파이프 라인 웹 서버는 다양한 서비스에서 데이터를 수집하여 현재 실행중인 파이프 라인 목록, 파이프 라인 실행 기록, 데이터 아티팩트 목록, 개별 파이프 라인 실행에 대한 디버깅 정보, 개별 파이프 라인 실행에 대한 실행 상태를 표시합니다.